
深度學習面試問題總結
第一部分:深度學習
1、神經網路基礎問題
(1)BP,Back-propagation(要能推倒)
後向傳播是在求解損失函式L對引數w求導時候用到的方法,目的是通過鏈式法則對引數進行一層一層的求導。這裡重點強調:要將引數進行隨機初始化而不是全部置0,否則所有隱層的數值都會與輸入相關,這稱為對稱失效。
大致過程是:
首先前向傳導計算出所有節點的啟用值和輸出值,

計算整體損失函式:

然後針對第L層的每個節點計算出殘差(這裡是因為UFLDL中說的是殘差,本質就是整體損失函式對每一
層啟用值Z的導數),所以要對W求導只要再乘上啟用函式對W的導數即可
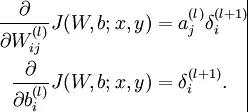
(2)梯度消失、梯度爆炸
梯度消失:這本質上是由於啟用函式的選擇導致的, 最簡單的sigmoid函式為例,在函式的兩端梯度求導結果非常小(飽和區),導致後向傳播過程中由於多次用到啟用函式的導數值使得整體的乘積梯度結果變得越來越小,也就出現了梯度消失的現象。
梯度爆炸:同理,出現在啟用函式處在啟用區,而且權重W過大的情況下。但是梯度爆炸不如梯度消失出現的機會多。
(3)常用的啟用函式
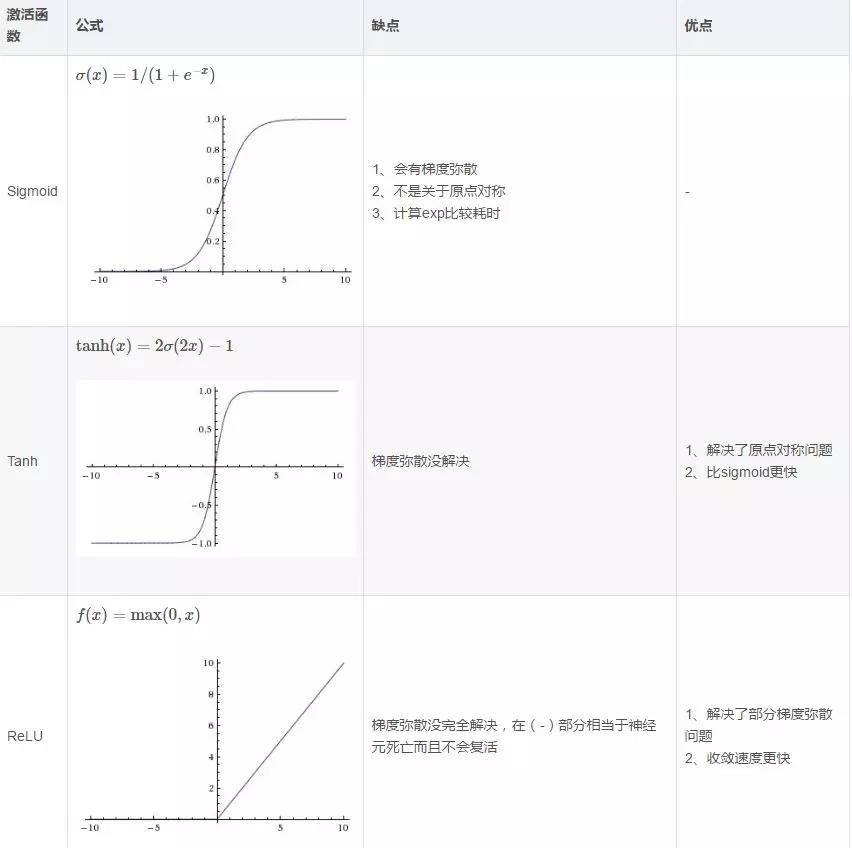
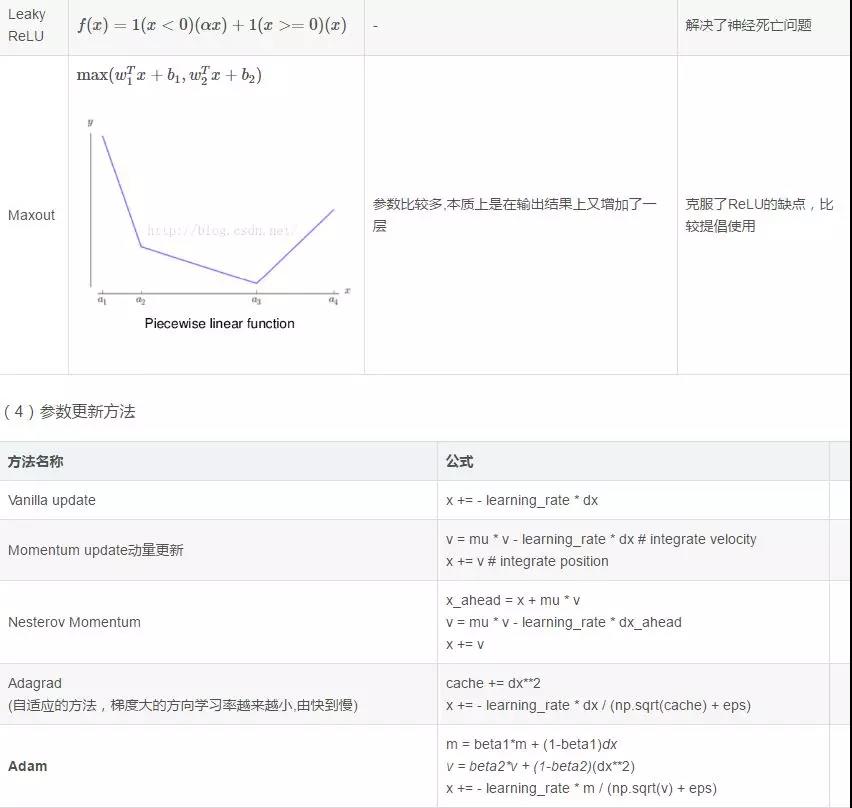
(5)解決overfitting的方法
dropout, regularization, batch normalizatin,但是要注意dropout只在訓練的時候用,讓一部分神經元隨機失活
2、CNN問題
(1) 思想
改變全連線為區域性連線,這是由於圖片的特殊性造成的(影象的一部分的統計特性與其他部分是一樣的),通過區域性連線和引數共享大範圍的減少引數值。可以通過使用多個filter來提取圖片的不同特徵(多卷積核)。
(2)filter尺寸的選擇
通常尺寸多為奇數(1,3,5,7)
(3)輸出尺寸計算公式
輸出尺寸=(N - F +padding*2)/stride + 1
步長可以自由選擇通過補零的方式來實現連線。
(4)pooling池化的作用
雖然通過.卷積的方式可以大範圍的減少輸出尺寸(特徵數),但是依然很難計算而且很容易過擬合,所以依然利用圖片的靜態特性通過池化的方式進一步減少尺寸。
(5)常用模型,最好能記住模型大致的尺寸引數。
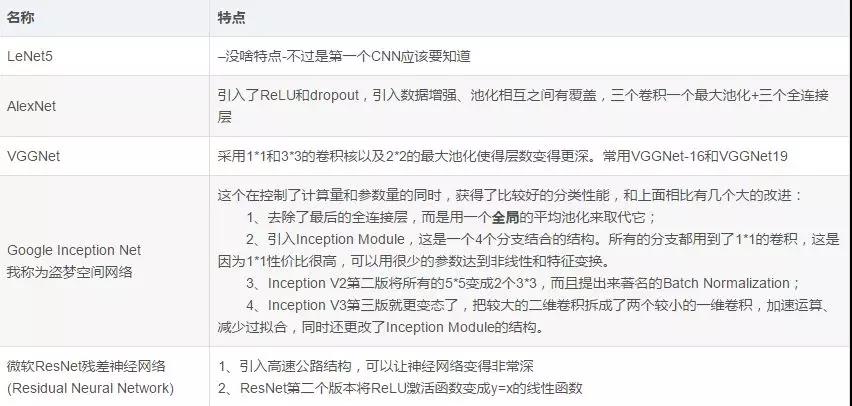
3、RNN
1、RNN原理:
在普通的全連線網路或CNN中,每層神經元的訊號只能向上一層傳播,樣本的處理在各個時刻獨立,因此又被成為前向神經網路(Feed-forward+Neural+Networks)。而在RNN中,神經元的輸出可以在下一個時間戳直接作用到自身,即第i層神經元在m時刻的輸入,除了(i-1)層神經元在該時刻的輸出外,還包括其自身在(m-1)時刻的輸出。所以叫迴圈神經網路
2、RNN、LSTM、GRU區別
RNN引入了迴圈的概念,但是在實際過程中卻出現了初始資訊隨時間消失的問題,即長期依賴(Long-Term Dependencies)問題,所以引入了LSTM。
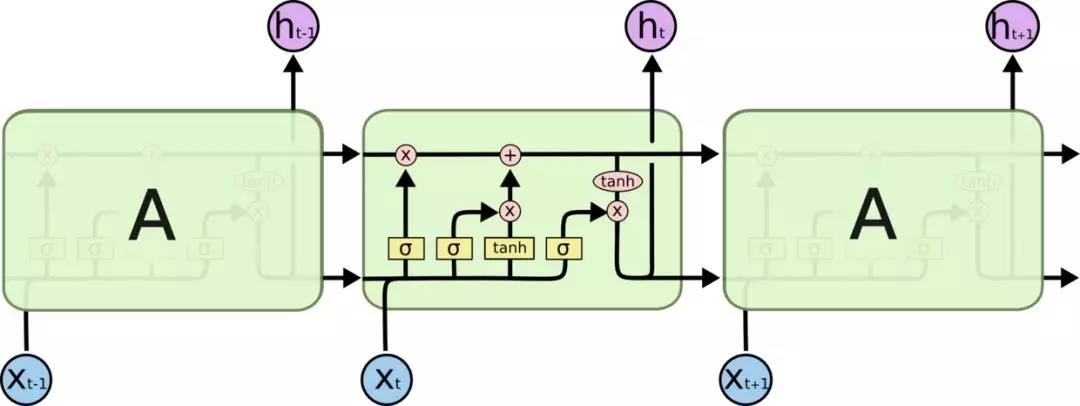
LSTM:因為LSTM有進有出且當前的cell informaton是通過input gate控制之後疊加的,RNN是疊乘,因此LSTM可以防止梯度消失或者爆炸。推導forget gate,input gate,cell state, hidden information等因為LSTM有進有出且當前的cell informaton是通過input gate控制之後疊加的,RNN是疊乘,因此LSTM可以防止梯度消失或者爆炸的變化是關鍵,下圖非常明確適合記憶:
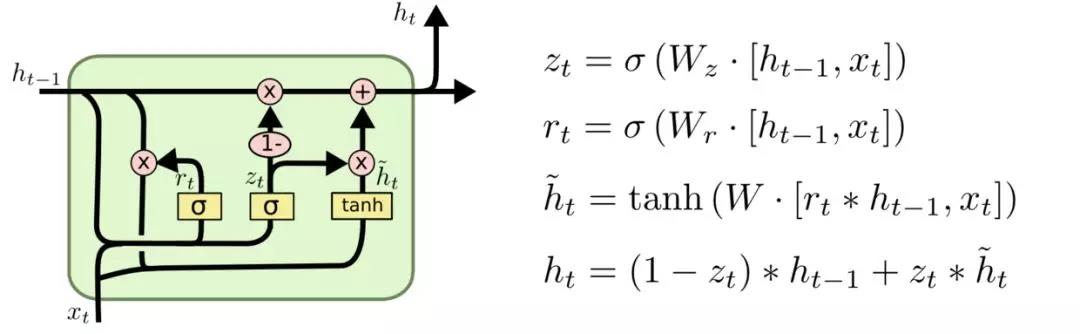
是LSTM的變體,將忘記門和輸入們合成了一個單一的更新門。
3、LSTM防止梯度彌散和爆炸
LSTM用加和的方式取代了乘積,使得很難出現梯度彌散。但是相應的更大的機率會出現梯度爆炸,但是可以通過給梯度加門限解決這一問題。
4、引出word2vec
這個也就是Word Embedding,是一種高效的從原始語料中學習字詞空間向量的預測模型。分為CBOW(Continous Bag of Words)和Skip-Gram兩種形式。其中CBOW是從原始語句推測目標詞彙,而Skip-Gram相反。CBOW可以用於小語料庫,Skip-Gram用於大語料庫。具體的就不是很會了。
3、GAN
1、GAN的思想
GAN結合了生成模型和判別模型,相當於矛與盾的撞擊。生成模型負責生成最好的資料騙過判別模型,而判別模型負責識別出哪些是真的哪些是生成模型生成的。但是這些只是在瞭解了GAN之後才體會到的,但是為什麼這樣會有效呢?
假設我們有分佈Pdata(x),我們希望能建立一個生成模型來模擬真實的資料分佈,假設生成模型為Pg(x;θθ),我們的目的是求解θ的值,通常我們都是用最大似然估計。但是現在的問題是由於我們相用NN來模擬Pdata(x),但是我們很難求解似然函式,因為我們沒辦法寫出生成模型的具體表達形式,於是才有了GAN,也就是用判別模型來代替求解最大似然的過程。
在最理想的狀態下,G可以生成足以“以假亂真”的圖片G(z)。對於D來說,它難以判定G生成的圖片究竟是不是真實的,因此D(G(z)) = 0.5。這樣我們的目的就達成了:我們得到了一個生成式的模型G,它可以用來生成圖片。
2、GAN的表示式
通過分析GAN的表達可以看出本質上就是一個minmax問題。其中V(D, G)可以看成是生成模型和判別模型的差異,而minmaxD說的是最大的差異越小越好。這種度量差異的方式實際上叫做Jensen-Shannon divergence。
3、GAN的實際計算方法
因為我們不可能有Pdata(x)的分佈,所以我們實際中都是用取樣的方式來計算差異(也就是積分變求和)。具體實現過程如下:
有幾個關鍵點:判別方程訓練K次,而生成模型只需要每次迭代訓練一次,先最大化(梯度上升)再最小化(梯度下降)。
但是實際計算時V的後面一項在D(x)很小的情況下由於log函式的原因會導致更新很慢,所以實際中通常將後一項的log(1-D(x))變為-logD(x)。
實際計算的時候還發現不論生成器設計的多好,判別器總是能判斷出真假,也就是loss幾乎都是0,這可能是因為抽樣造成的,生成資料與真實資料的交集過小,無論生成模型多好,判別模型也能分辨出來。解決方法有兩個:1、用WGAN 2、引入隨時間減少的噪聲
4、對GAN有一些改進有引入f-divergence,取代Jensen-Shannon divergence,還有很多,這裡主要介紹WGAN
5、WGAN
上面說過了用f-divergence來衡量兩個分佈的差異,而WGAN的思路是使用Earth Mover distance (挖掘機距離 Wasserstein distance)。