
字和詞語聯合訓練的詞向量模型
今天又讀了一篇劉知遠老師團隊2015年在頂會Ijcai上發表的論文《Joint Learning of Character and Word Embeddings》,同樣是有關於在詞向量生成部分進行了改進,引入了詞語組成成分的單個漢字的資訊(論文主要針對的是中文),提升了詞向量生成的質量。因為模型名稱叫做“character-enhanced word embeddding model”,故模型簡稱為CWE。
從論文的題目可以看出,這篇paper在進行詞向量訓練的時候,講詞語中把組成詞語的漢字單獨抽取出來,和詞語一起進行訓練。這樣就使那些共享漢字的詞語之間產生了聯絡,因為paper的假設是“semantically compositional”的詞語中的漢字對詞語的意思具有一定的表徵作用,比方說詞語“智慧”。但是在漢語中並不是所有的詞語都是semantically compositional,比方說一些翻譯過來的詞語“巧克力”,“沙發”,再比方說一些實體的名稱,比方說一些人名、地名和國家名。在這些詞語中,單個漢字的意思可能和本來這個詞語要表達的意思是完全沒有關係的。在本篇paper中,作者做了大量的工作去把這些沒有semantically compositional性質的詞語全部人工的挑選出來,對於這些詞語不去進行單個字的拆分處理。
這篇論文提出的模型,是在word2vec的CBOW基礎之上進行改進的,模型整體的優化函式如下所示:
從中可以明顯的看出,在CBOW模型中,context的表示是
介紹完了傳統的CBOW模型之後,就要介紹這篇paper提出的模型,模型示意圖如下所示:
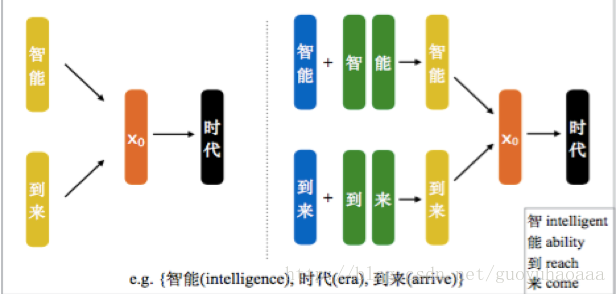
從上圖可以清楚的看出,在傳統的CBOW模型中,target word“時代”的context資訊是直接把“智慧”和“到來”的詞向量形式進行相加;而在CWE模型中,對於context中的詞語的表徵,一方面來自於詞向量,還有一部分在自於這些詞語中的字的向量,具體的計算方式如下:
其中,
注意上述公式中的
上述只是一個大概的框架模型,還有一些細節問題沒有考慮,其中最主要的一個問題就是:同一個漢字,在不同的詞語中可能具有完全不同的語義,如果使用一個向量來表徵一個字,那麼很可能會無法標識出這些差異性,故使用多個向量來表徵同一個漢字,有下面幾種方式:
1 Position-based Character Embedding
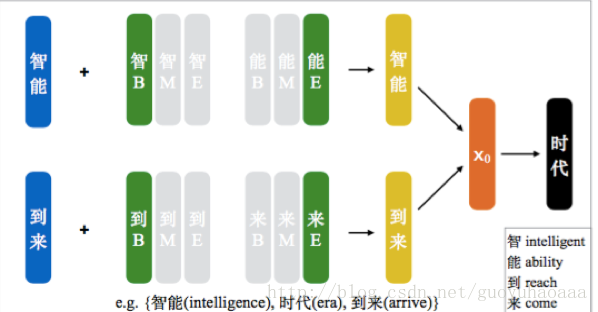
從名字可以看出,在該模型中同一個漢字根據其在詞語中出現的位置不同,對應不同位置的向量表示形式。分析可知,漢字在詞語中出現的位置有:Begin,Middle,End這三種情況,故每一個漢字都有三種向量表示形式,在進行
2 Cluster_based Character Embedding
今天又讀了一篇劉知遠老師團隊2015年在頂會Ijcai上發表的論文《Joint Learning of Character and Word Embeddings》,同樣是有關於在詞向量生成部分進行了改進,引入了詞語組成成分的單個漢字的資訊(論文主要針對的是中文
詞向量說明如下:
詞向量模型表徵的是詞語與詞語之間的距離和聯絡,詞向量也叫詞嵌入 word embedding
CBOW 模型: 根據某個詞的上下文,計算中間詞出現的概率,預測的是中心詞
Skip-Gram 模型: 跟據中間詞,分別計算它的上下文概率,與 CBOW 模型相反
詞向量嵌入需要高效率處理大規模文字語料庫。word2vec。簡單方式,詞送入獨熱編碼(one-hot encoding)學習系統,長度為詞彙表長度的向量,詞語對應位置元素為1,其餘元素為0。向量維數很高,無法刻畫不同詞語的語義關聯。共生關係(co-occurre
開啟美好的九月
最近在學習textCNN進行文字分類,然後隨機生成向量構建embedding網路的分類效果不是很佳,便考慮訓練Glove詞向量來進行訓練,整個過程還是有遇到一些問題,希望懂的旁友能來指點下~
關於GloVe
GloVe,全稱是Global Vectors fo
在自然語言處理和文字分析的問題中,詞袋(Bag of Words, BOW)和詞向量(Word Embedding)是兩種最常用的模型。更準確地說,詞向量只能表徵單個詞,如果要表示文字,需要做一些額外的處理。下面就簡單聊一下兩種模型的應用。
所謂BOW,就是將文字/Query看作是一系列詞的集合 1 大綱概述
文字分類這個系列將會有十篇左右,包括基於word2vec預訓練的文字分類,與及基於最新的預訓練模型(ELMo,BERT等)的文字分類。總共有以下系列:
word2vec預訓練詞向量
textCNN 模型
charCNN 模型
Bi-LSTM 模型
Bi-LST 1 大綱概述
文字分類這個系列將會有十篇左右,包括基於word2vec預訓練的文字分類,與及基於最新的預訓練模型(ELMo,BERT等)的文字分類。總共有以下系列:
word2vec預訓練詞向量
textCNN 模型
charCNN 模型
Bi-LSTM 模型
Bi-LST
主要內容
這篇文章主要內容是介紹從初始語料(文字)到生成詞向量模型的過程。
詞向量模型
詞向量模型是一種表徵詞在整個文件中定位的模型。它的基本內容是詞以及它們的向量表示,即將詞對映為對應的向量,這樣就可以被計算機識別和計算。它的檔案字尾名是.bin。
1 大綱概述
文字分類這個系列將會有十篇左右,包括基於word2vec預訓練的文字分類,與及基於最新的預訓練模型(ELMo,BERT等)的文字分類。總共有以下系列:
word2vec預訓練詞向量
textCNN 模型
charCNN 模型
Bi-LSTM 模型
Bi-LST
例句:Jane wants to go to Shenzhen.Bob wants to go to Shanghai.一、詞袋模型 將所有詞語裝進一個袋子裡,不考慮其詞法和語序的問題,即每個詞語都是獨立的。例如上面2個例句,就可以構成一個詞袋,袋子裡包括Jane、w sig 財經 left 調用 采樣 cto imp gensim average 博客園的markdown用起來太心塞了,現在重新用其他編輯器把這篇博客整理了一下。
目前用word2vec算法訓練詞向量的工具主要有兩種:gensim 和 tensorflow。gensim www. 頻率 cbo homepage 算法 文章 有一個 tro 概率
閱讀目錄
1. 詞向量
2.Distributed representation詞向量表示
3.詞向量模型
4.word2vec算法思想
5.doc2vec算法思 技術分享 alt 自然語言 inf bsp word 學習 向量 9.png 自然語言處理與深度學習:
語言模型:
N-gram模型:
自然語言處理詞向量模型-word2vec
1 def word_vector_gener():
2 """
3 幾種不同的方法來生成詞向量
4 :return:
5 """
6 from gensim.models import Word2Vec
7 from gensim.test
一、原理
skip-thought模型結構藉助了skip-gram的思想。在skip-gram中,是以中心詞來預測上下文的詞;在skip-thought同樣是利用中心句子來預測上下文的句子,其資料的結構可以用一個三元組表示 (st−1,st,st+1)(st−1,st,st+1)&nb
自然語言處理中,在詞的表示上,向量的方式無疑是最流行的一種。它可以作為神經網路的輸入,也可直接用來計算。比如計算兩個詞的相似度時,就可以用這兩個詞向量的距離來衡量。詞向量的訓練需要大規模的語料,從而帶來的是比較長的訓練時間。spark框架基於記憶體計算,有忘加快詞向量的訓練速度。 以下是sp
準備工作
當我們下載了anaconda後,可以在命令視窗通過命令
conda install gensim
安裝gensim
gensim介紹
gensim是一款強大的自然語言處理工具,裡面包括N多常見模型,我們體驗一下:
interfa 深度學習掀開了機器學習的新篇章,目前深度學習應用於影象和語音已經產生了突破性的研究進展。深度學習一直被人們推崇為一種類似於人腦結構的人工智慧演算法,那為什麼深度學習在語義分析領域仍然沒有實質性的進展呢?
引用三年前一位網友的話來講:
“Steve Renals算了一下icassp錄取文章題目中包含 深度學習掀開了機器學習的新篇章,目前深度學習應用於影象和語音已經產生了突破性的研究進展。深度學習一直被人們推崇為一種類似於人腦結構的人工智慧演算法,那為什麼深度學習在語義分析領域仍然沒有實質性的進展呢?
引用三年前一位網友的話來講:
“Steve Renals算了一下icassp錄取文章題目中 1 大綱概述
文字分類這個系列將會有十篇左右,包括基於word2vec預訓練的文字分類,與及基於最新的預訓練模型(ELMo,BERT等)的文字分類。總共有以下系列:
word2vec預訓練詞向量
textCNN 模型
charCNN 模型
Bi-LSTM 模型
Bi-LST
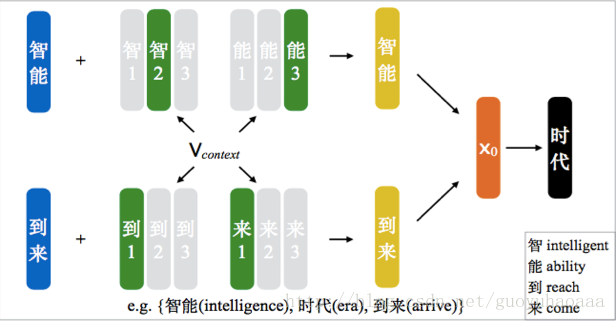
該模型運用了k-means演算法思想的部分原理,也就是對於每一個漢字提前分配x個字向量,x的個數是模型的一個超引數,代表了潛在定義的每個漢字所對應的語義模式(我們也可以稱之為模式向量)。至於在利用式子
相關推薦
字和詞語聯合訓練的詞向量模型
使用 rnn 訓練詞向量模型
Tensorflow實戰學習(十八)【詞向量、維基百科語料庫訓練詞向量模型】
Ubuntu下GloVe中文詞向量模型訓練
詞袋模型和詞向量模型
文字分類實戰(四)—— Bi-LSTM模型 文字分類實戰(一)—— word2vec預訓練詞向量
文字分類實戰(七)—— Adversarial LSTM模型 文字分類實戰(一)—— word2vec預訓練詞向量
使用Google word2vec訓練我們自己的詞向量模型
文字分類實戰(十)—— BERT 預訓練模型 文字分類實戰(一)—— word2vec預訓練詞向量
詞袋模型(BOW,bag of words)和詞向量模型(Word Embedding)概念介紹
文本分布式表示(二):用tensorflow和word2vec訓練詞向量
[Algorithm & NLP] 文本深度表示模型——word2vec&doc2vec詞向量模型
自然語言處理詞向量模型-word2vec
訓練詞向量
Skip-Thought詞向量模型實現Sent2Vec
Spark Mlib(三)用spark訓練詞向量
基於python的gensim word2vec訓練詞向量
文字深度表示模型——word2vec&doc2vec詞向量模型(轉)
[Algorithm & NLP] 文字深度表示模型——word2vec&doc2vec詞向量模型
文字分類實戰(一)—— word2vec預訓練詞向量