
文字分類實戰(十)—— BERT 預訓練模型 文字分類實戰(一)—— word2vec預訓練詞向量
1 大綱概述
文字分類這個系列將會有十篇左右,包括基於word2vec預訓練的文字分類,與及基於最新的預訓練模型(ELMo,BERT等)的文字分類。總共有以下系列:
所有程式碼均在textClassifier倉庫中,覺得有幫助,請給個小星星。
2 資料集
資料集為IMDB 電影影評,總共有三個資料檔案,在/data/rawData目錄下,包括unlabeledTrainData.tsv,labeledTrainData.tsv,testData.tsv。在進行文字分類時需要有標籤的資料(labeledTrainData),資料預處理如文字分類實戰(一)—— word2vec預訓練詞向量中一樣,預處理後的檔案為/data/preprocess/labeledTrain.csv。
3 BERT預訓練模型
BERT 模型來源於論文BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
BERT 模型是將預訓練模型和下游任務模型結合在一起的,也就是說在做下游任務時仍然是用BERT模型,而且天然支援文字分類任務,在做文字分類任務時不需要對模型做修改。谷歌提供了下面七種預訓練好的模型檔案。

BERT模型在英文資料集上提供了兩種大小的模型,Base和Large。Uncased是意味著輸入的詞都會轉變成小寫,cased是意味著輸入的詞會儲存其大寫(在命名實體識別等專案上需要)。Multilingual是支援多語言的,最後一個是中文預訓練模型。
在這裡我們選擇BERT-Base,Uncased。下載下來之後是一個zip檔案,解壓後有ckpt檔案,一個模型引數的json檔案,一個詞彙表txt檔案。
在應用BERT模型之前,我們需要去github上下載開源程式碼,我們可以直接clone下來,在這裡有一個run_classifier.py檔案,在做文字分類專案時,我們需要修改這個檔案,主要是新增我們的資料預處理類。clone下來的專案結構如下:
在run_classifier.py檔案中有一個基類DataProcessor類,其程式碼如下:
class DataProcessor(object): """Base class for data converters for sequence classification data sets.""" def get_train_examples(self, data_dir): """Gets a collection of `InputExample`s for the train set.""" raise NotImplementedError() def get_dev_examples(self, data_dir): """Gets a collection of `InputExample`s for the dev set.""" raise NotImplementedError() def get_test_examples(self, data_dir): """Gets a collection of `InputExample`s for prediction.""" raise NotImplementedError() def get_labels(self): """Gets the list of labels for this data set.""" raise NotImplementedError() @classmethod def _read_tsv(cls, input_file, quotechar=None): """Reads a tab separated value file.""" with tf.gfile.Open(input_file, "r") as f: reader = csv.reader(f, delimiter="\t", quotechar=quotechar) lines = [] for line in reader: lines.append(line) return lines
在這個基類中定義了一個讀取檔案的靜態方法_read_tsv,四個分別獲取訓練集,驗證集,測試集和標籤的方法。接下來我們要定義自己的資料處理的類,我們將我們的類命名為IMDBProcessor
class IMDBProcessor(DataProcessor): """ IMDB data processor """ def _read_csv(self, data_dir, file_name): with tf.gfile.Open(data_dir + file_name, "r") as f: reader = csv.reader(f, delimiter=",", quotechar=None) lines = [] for line in reader: lines.append(line) return lines def get_train_examples(self, data_dir): lines = self._read_csv(data_dir, "trainData.csv") examples = [] for (i, line) in enumerate(lines): if i == 0: continue guid = "train-%d" % (i) text_a = tokenization.convert_to_unicode(line[0]) label = tokenization.convert_to_unicode(line[1]) examples.append( InputExample(guid=guid, text_a=text_a, label=label)) return examples def get_dev_examples(self, data_dir): lines = self._read_csv(data_dir, "devData.csv") examples = [] for (i, line) in enumerate(lines): if i == 0: continue guid = "dev-%d" % (i) text_a = tokenization.convert_to_unicode(line[0]) label = tokenization.convert_to_unicode(line[1]) examples.append( InputExample(guid=guid, text_a=text_a, label=label)) return examples def get_test_examples(self, data_dir): lines = self._read_csv(data_dir, "testData.csv") examples = [] for (i, line) in enumerate(lines): if i == 0: continue guid = "test-%d" % (i) text_a = tokenization.convert_to_unicode(line[0]) label = tokenization.convert_to_unicode(line[1]) examples.append( InputExample(guid=guid, text_a=text_a, label=label)) return examples def get_labels(self): return ["0", "1"]
在這裡我們沒有直接用基類中的靜態方法_read_tsv,因為我們的csv檔案是用逗號分隔的,因此就自己定義了一個_read_csv的方法,其餘的方法就是讀取訓練集,驗證集,測試集和標籤。在這裡標籤就是一個列表,將我們的類別標籤放入就行。訓練集,驗證集和測試集都是返回一個InputExample物件的列表。InputExample是run_classifier.py中定義的一個類,程式碼如下:
class InputExample(object): """A single training/test example for simple sequence classification.""" def __init__(self, guid, text_a, text_b=None, label=None): """Constructs a InputExample. Args: guid: Unique id for the example. text_a: string. The untokenized text of the first sequence. For single sequence tasks, only this sequence must be specified. text_b: (Optional) string. The untokenized text of the second sequence. Only must be specified for sequence pair tasks. label: (Optional) string. The label of the example. This should be specified for train and dev examples, but not for test examples. """ self.guid = guid self.text_a = text_a self.text_b = text_b self.label = label
在這裡定義了text_a和text_b,說明是支援句子對的輸入的,不過我們這裡做文字分類只有一個句子的輸入,因此text_b可以不傳參。
另外從上面我們自定義的資料處理類中可以看出,訓練集和驗證集是儲存在不同檔案中的,因此我們需要將我們之前預處理好的資料提前分割成訓練集和驗證集,並存放在同一個資料夾下面,檔案的名稱要和類中方法裡的名稱相同。
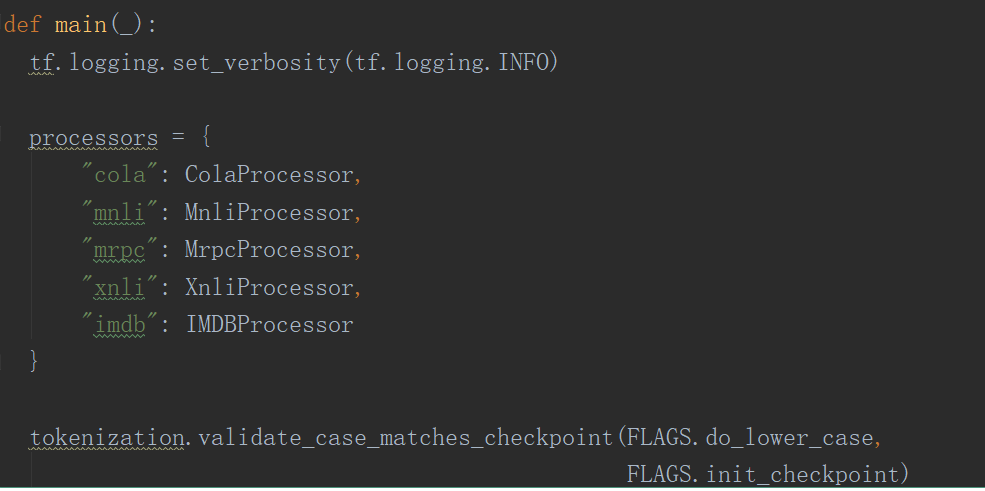
到這裡之後我們已經準備好了我們的資料集,並定義好了資料處理類,此時我們需要將我們的資料處理類加入到run_classifier.py檔案中的main函式下面的processors字典中,結果如下:
之後就可以直接執行run_classifier.py檔案,執行指令碼如下:
export BERT_BASE_DIR=../modelParams/uncased_L-12_H-768_A-12 export DATASET=../data/ python run_classifier.py \ --data_dir=$MY_DATASET \ --task_name=imdb \ --vocab_file=$BERT_BASE_DIR/vocab.txt \ --bert_config_file=$BERT_BASE_DIR/bert_config.json \ --output_dir=../output/ \ --do_train=true \ --do_eval=true \ --init_checkpoint=$BERT_BASE_DIR/bert_model.ckpt \ --max_seq_length=200 \ --train_batch_size=16 \ --learning_rate=5e-5\ --num_train_epochs=2.0
在這裡的task_name就是我們定義的資料處理類的鍵,BERT模型較大,載入時需要較大的記憶體,如果出現記憶體溢位的問題,可以適當的降低batch_size的值。
目前迭代完之後的輸出比較少,而且只有等迭代結束後才會有結果輸出,不利於觀察損失的變化,後續將修改輸出。目前的輸出結果:
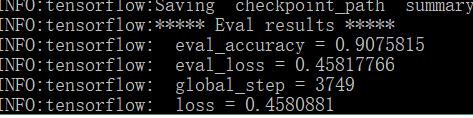
測試集上的準確率達到了90.7% ,這個結果比Bi-LSTM + Attention(87.7%)的結果要好。而且我們還無法確定目前的BERT模型是否已收斂,後續將修改訓練時的輸出日誌。