
Java String類拼接時的編譯器優化
阿新 • • 發佈:2019-02-09
先看程式碼:
public class Main {
public static void main(String[] args) throws Exception{
String baseStr = "baseStr";
final String baseFinalStr = "baseStr";
String str1 = "baseStr01";
String str2 = "baseStr" + "01";
// JAVA 1.6之後,常量字串的“+”操作,編譯階段直接會合成為一個字串
// 所以str1與str2指向常量池中的同一引用地址。 其中String str3 = baseStr + "01";,這條語句編譯器會自動呼叫StringBuilder類進行字串拼接,以此來優化效能。
比如:
public class Test 用javap -c Test.class 反編譯
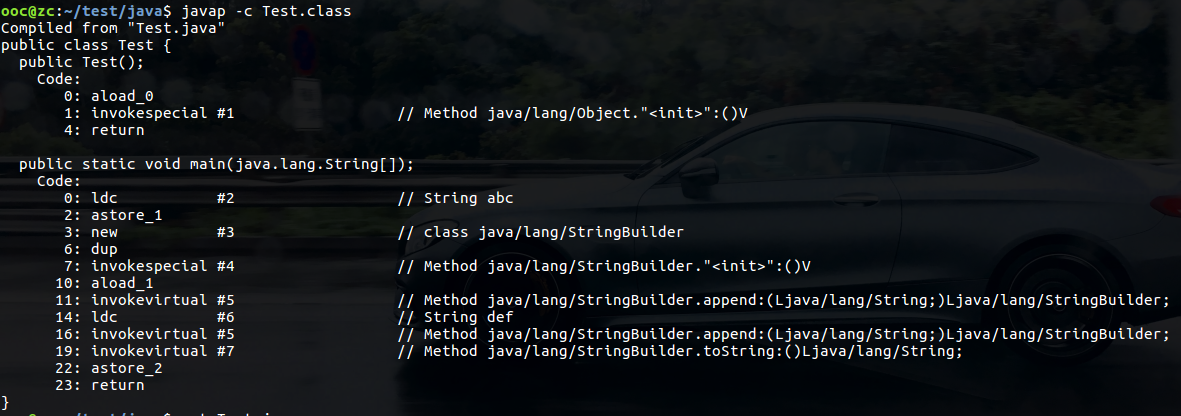
可以看出字串用’+'運算子拼接時編譯器會自動使用StringBuilder類優化效能,拼接完成後呼叫StringBuilder的toString()方法返回String物件。
雖然字串拼接時會自動呼叫StringBuilder來優化效能,但不能太依賴編譯器的自動優化,比如在迴圈條件下,編譯器的優化可能並不好。(每次迴圈都新建一個StringBuilder物件)
StringBuilder 的toString()方法
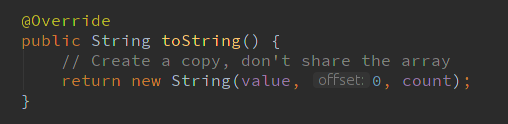
可以看出,這裡用new新建了一個String物件,即不從字串池中獲取。
即在執行時進行拼接的String會生成新的String物件(在堆中),在編譯器已經完成拼接的String物件在String Pool中。