
Attention-Aware Compositional Network for Person Re-identification論文精讀
Attention-Aware Compositional Network for Person Re-identification
Abstract
現在行人重識別(Person ReID)越來越火,一個比較大的挑戰是首先跨攝像頭目標重識別,其次是每一個行人patch中背景複雜、人體姿態不一和遮擋等情況增加了特徵提取並學習的難度。目前有很多工作已經開始引入了額外的監督資訊比如行人的關鍵點,通過一種part-base的方法去強約束模型對於行人特徵的學習能力。關鍵點的引入可以使得行人的一些區域性特徵提取變得更加準確,過往有很多工作證明了這種工作的有效性。
作者在本篇文章主要提出了一種Person ReID的架構叫做Attention-Aware Compositional Network (AACN),這種結構主要由兩個子結構構成。
- Pose-guided Part Attention (PPA)
- Attention-aware Feature Composition (AFC)
前者用於學習特徵預測人體關鍵點、剛性結構和非剛性結構的特徵圖,同時對於不同結構所預測出來的特徵圖,還引入了一個概念叫做 pose-guided visibility scores,主要是用來對每個人體部件的可視程度進行打分加權。AFC結構用於將PPA得到的attention資訊與全域性的特徵組合在一起,然後通過行人的ID作為標籤進行分類訓練(reid loss)。作者的這個方法在目前主流的Person ReID資料集比如Market-1501, CUHK03, CUHK01, SenseReID,CUHK03-NP and DukeMTMC-reID上都取得了最好的結果。
Introduction
近幾年研究Person ReID的文章很多,這主要得益於其具備廣泛而重要的應用,最常見的一個需求就是老人、小孩走丟了之後能快速分析將其找回。但是由於人體姿態、光照、背景和不同攝像機成像之間存在差異。跨攝像頭的Person ReID即行人檢索有較高的難度。part-base的方法可以使得CNN模型提取特徵的過程中更加關心與重要人體區域的特徵,但目前仍存在一定的問題。如下圖(a),(b),(c)所示,畫框型別的人體部件標註引入了額外的背景資訊和其他部件的區域,在提取的特徵中真正關心的部件特徵只佔了一部分。

同時觀察上圖的(d),(e),(f),交叉的部件和揹包都會讓目標人體部件的特徵提取出現不準確的情況。所以在這篇文章中,作者引入了姿態也就是關鍵點來精細化行人部件的特徵提取,稱之為Pose-guided的方法。在說這部分之前作者對比了過往part-based方法中常用的手段,如下圖所示。

RoI是我們剛才所說的對不同的部件使用box畫框標註的方法,Patch和Strip分別設計了網格和橫條去拆分一幅圖,然後針對每一個part都提取特徵進行學習。從圖中可以很直觀的看出,作者使用的這種Pose-guided的方法能更準確的學習人體部件區域的Attention Map。對於本文的貢獻點總結如下:
- 提出了一個叫做Attention-Aware Compositional Network (AACN)的結構用來解決行人不對齊和遮擋的問題。
- Pose-guided的方法能更準確的排除掉背景等區域的干擾資訊,並且基於該方法得到的行人剛性和非剛性Attention Map能被用於大部分基於Attention的方法中。
- 對於不同部件的Attention Map引入了visibility score主要解決了行人中一些部件出現遮擋的問題。
- 在目前的主流Person ReID資料集上取得了最好的效能結果。
Related Work
這部分感興趣可以檢視論文了解。
Attention-Aware Compositional Network
如同前文提到的一樣,作者的AACN框架包含兩個結構,分別是Pose-guided Part Attention(PPA)和Attention-aware Feature Composition (AFC)。前者對一張輸入影象處理之後輸出attention map和visibility scores,然後這部分的輸出和AFC的第一個stage輸出也就是Global Feature相結合之後作為AFC模組的後端輸入。總體結構圖如下圖所示:
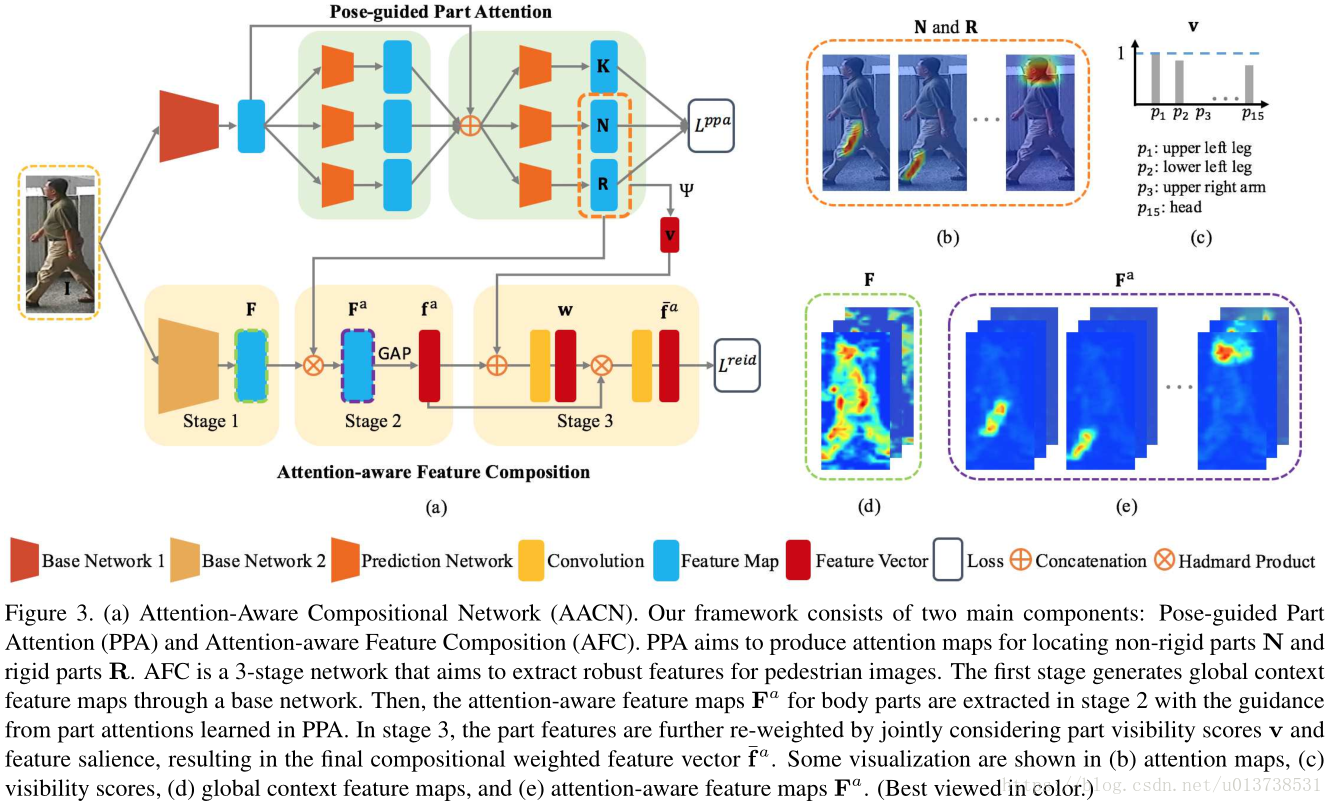
PPA結構主要包含了兩個stage,每一個stage分別對應三個輸出,為關鍵點的特徵圖、剛性結構的特徵圖和非剛性結構的特徵圖。使用2 stage級聯的方式可以使得網路在學習過程中對於特徵圖的生成更為準確。結構如上圖中(a)的上半部分。AFC模組主要是用GoogleNet作為stage1的backbone用於影象全域性特徵圖的生成,然後在stage2和stage3中分別於PPA的attention map和visibility scores相結合計算。如上圖中的(b)下半部分所示。
Pose-guided Part Attention
類似於下圖(a),人的結構可以按照關鍵點的分佈而分為剛性結構和非剛性結構。
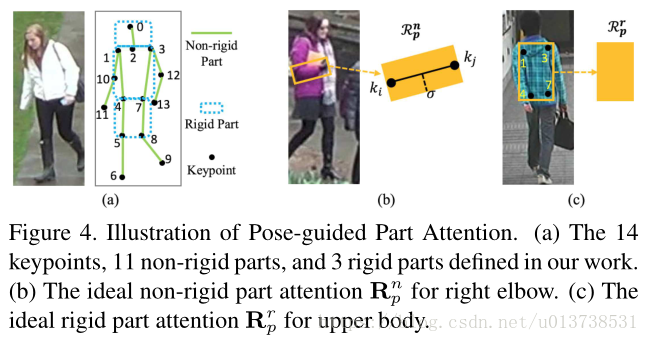
剛性結構主要是人體的軀幹,分別頭部、上半身軀幹和下半身軀幹,非剛性結構的話主要是腿、胳膊等人體部件。PPA結構中使用了一個2stage的CNN模型,最終輸出關鍵點K、剛性結構R和非剛性結構N三種attention map。這一部分對三種attention map分別計算loss,公式如下所示:
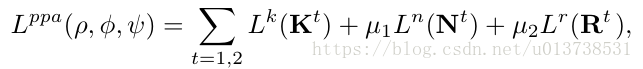
Loss for Keypoint Confidence Map
對於人體關鍵點的attention map,作者定義loss表達為,人體總共在這篇文章中歸結為14個關鍵點,所以最終輸出的attention map總共有14個,每一個attention map分別對應一個關鍵點的迴歸結果。在真值標籤中,對於某個座標位置上的關鍵點需要使用Gaussian kernel(高斯核函式)中心展開得到其對應的heatmap真值標籤。然後計算損失的時候使用MSE Loss來衡量真值heatmap和預測出來的attention map之間的差異。公式如下:
Loss for Non-Rigid Part Attention
對於人體的非剛性結構,之前的方法都是使用box作為框定的標籤,本文受 Part Affinity Field (PAF)方法的啟發,對於某一個非剛性結構,使用兩個關鍵點定位到這個結構的兩端,然後連線以後以一定的寬度外擴得到一個矩形區域表示非剛性結構的attention map真值。最終使用MSE Loss來計算真值和預測值之間的差異:
Loss for Rigid Part Attention
上文提到的三個人體剛性部件,同樣使用了關鍵點作為引導然後勾勒出幾何區域來表示真值的heatmap,對於頭肩部分選擇關鍵點的組合為,對於上半身選擇,對於下半身選擇。同樣的該部分也使用了MSE Loss,如下所示:
Part Visibility Score
attention map中attention區域的大小能直觀的表示出一個部件在一幅影象中的成像大小,受這個思想的啟發,作者對於每個attention map做一個累加計算,得到的值定義為visibility scores,如果這個值越大,那麼就說明人體該部分的部件遮擋情況不是特別嚴重。公式如下所示:
分別表示了作者對人體的所有剛性結構和非剛性部件的在PPA結構的輸出特徵圖中做了特徵累加。
Attention-aware Feature Composition
如上面的結構圖所示,AFC結構包含了三個stage,分別是一個Global Context Network(GCN)用於提取影象的全域性特徵, Attention-Aware Feature Alignment和 Weighted Feature Composition。後兩個結構分別利用了PPA輸出的attention map和visibility scores與全域性的影象feature map結合計算。
Stage 1: Global Context Network (GCN)
GCN結構使用了GoogleNet作為backbone輸出影象的全域性特徵,與原本的CNN結構不一樣的是,作者將inception 5b/output部分後面的模組替換為了一個3x3,卷積核個數為256的卷積層,其中一個作用是降低了網路的效能開銷,同時使用了這個結構結合448x192的輸入(原版CNN輸入為224x224),最終GCN的輸出特徵圖從7x7變為14x6。對於這一部分,作者修改網路結構之後將改過的GCN模型在ImageNet網路上做了預訓練。
Stage 2: Attention-Aware Feature Alignment
對比上述結構圖中(a)的下半部分,AFC的stage2首先第一個輸入時GCN的global feature,其次是PPA結構輸出來的剛性結構和非剛性結構的attention map(假如有N個)。每一個attention map使用哈達瑪乘積依次與global feature進行計算,最終可以得到N個global feature。對於每一個global feature首先使用GAP(global average pooling)計算之後將所有的feature vector拼接起來。基本上可以用以下公式表示這個過程。