
CVPR2018論文翻譯 Human Semantic Parsing for Person Re-identification
論文連結:
摘要
混亂的背景、光照、視角等因素制約了提取魯棒性表示的能力,因此reid是個挑戰性的任務。為了改進表示學習,通常提取行人身體各部分的區域性特徵。然而,實際中通常基於包圍框的部分檢測。本文提出了改編的human semantic parsing,它有著畫素等級的精確率和建模任意輪廓的能力,因此一個很好的選擇。
我們提出的SPReID不僅超出了它的baseline效能,還實現了state-of-the-art.我們還表明,通過採用一個簡單但有效的訓練策略,標準CNN結構(例如Inception-V3和ResNet-152),無需修改,單獨地操作整副影象,就能超過當前最佳水平。
一.導論
行人重識別問題定義;行人重識別難點,提出一個有效的reid系統必須能夠學習到針對個體的、上下文不變的、攝像頭視角不可知的表示。
最近,藉助區域性(part-level)特徵來改進全域性(image-level)表示是reid的主要主題。image-level的表示容易雜亂或被遮擋,part-level表示更魯棒。然而,partdetection在低解析度影象下是很困難的,而一點的錯誤都會傳遞到整個reid系統。這就是為什麼一些研究傾向於從影象塊、水平條來提取特徵,它們稍微與人體各部分有聯絡。
另一方面,幾乎所有先前的設計bodyparts的工作都先是用現成的姿態估計模型,再從預測到的關節位置來推斷包圍框。接著系統提取全域性和區域性特徵,用的是一個能大概看作是multi-branch的deep CNN結構。這些模型通常包含很多子模型並且用多個階段訓練,為reid問題量身定做。本文提出兩個問題:首先。這麼複雜的模型真的必要嗎?其次,對body parts用包圍框真的能獲取到好的區域性特徵嗎?
為了解決第一個問題,我們展示了,基於沒有修飾的Inception-V3,處理一張完整的影象,用很直接的訓練策略優化,就能夠達到SOA.我們不用binary或者什麼triplet loss,只用softmax交叉熵,用兩種不同的輸入解析度。接著採用重排序作為後處理技術。
對於第二個問題,我們提出用語義分割,更針對於人類語義解析,來替代包圍框。顯然包圍框太粗糙,會包括背景,不能捕捉人體的形變。而語義分割能精確定位隨機輪廓,即使在嚴重的姿態改變下。我們先訓練human semantic parsing model來將人體分成多個語義區域,接著使用它們來挖掘reid的區域性線索。我們分析了整合human semantic parsing到reid的兩種做法,並證明了它們確實補充了表示。
本文貢獻:
1)我們簡單而有效的訓練方法能夠顯著超過SOA。基於Inception-V3和ResNet-152模型,三個不同基準資料集。
2)提出SPReID,用人體語義解析來提取區域性視覺線索。我們的語義分割模型不僅改進了reid,還在人體語義解析問題上取得了SOA。
3)提升了reid的效能,達到SOA水平。
本文組織:
第2節是reid文獻綜述;第3節是我們的方法;第4節是試驗結果和討論;第5節是實現的細節;第6節總結。
三.方法
我們預設將Inception-V3結構作為人體語義分割和重識別的主幹模型。首先,我們簡單描述Inception-V3結構,然後,我們提供人體語義分割模型的細節,最後解釋如何將其整合到reid框架。
3.1 Inception-V3結構
48層網路結構。用全域性平均池化代替全連線層,因此能夠輸入任意尺寸影象。儘管比其它流行的resnet網路的變體要更淺層,我們的實驗展示了它能比resnet152甚至更好的效能,並且計算代價更小。我們會給出兩種選擇的量化比較。
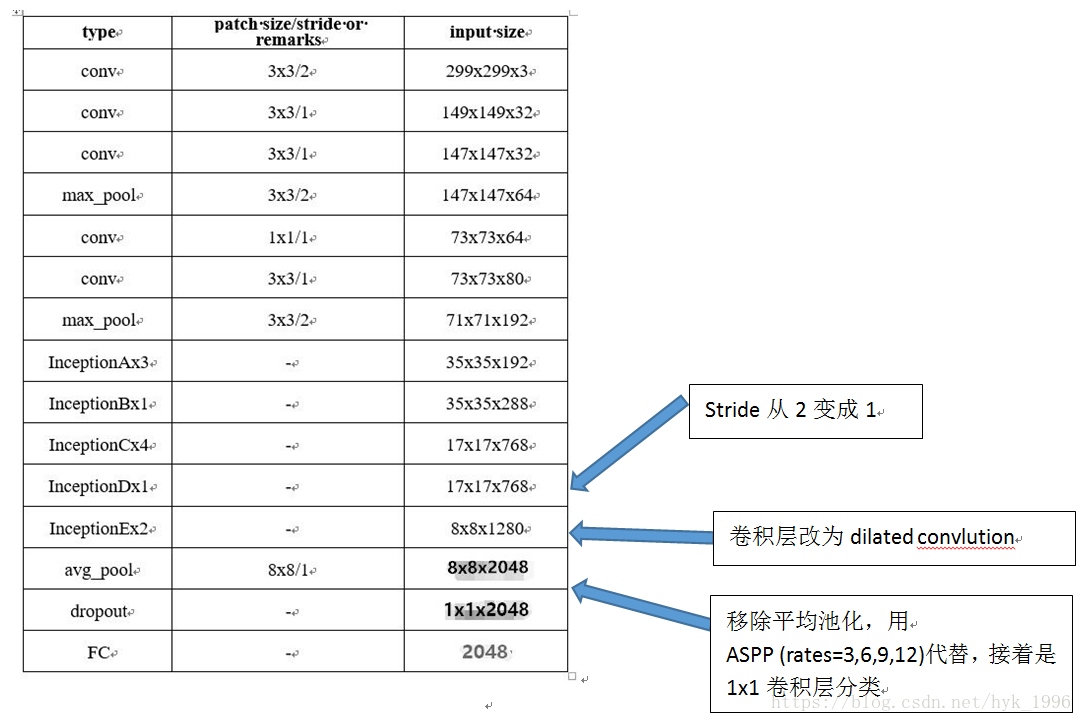
3.2 語義分割模型
採用Inception-V3作為人體語義解析模型的主幹,為此對Inception-V3做了兩點修改,使其更適合語義分割任務。
因為語義分割嚴重依賴於充分的解析度,因此我們將最後的grid reduction module的stride從2改為1,使使得output stride由32變為16. 為了處理這多出的計算(位於最後Inception塊),相關的卷積層用dilated convolution代替。接著我們移除全域性平均池化,增加atrous spatial pyramid pooling (rates=3,6,9,12),再接一個1X1卷積層作為分類器。這個將允許我們在畫素等級進行多分類,並且是語義分割結構中的常用方法。
3.3 行人重識別模型
我們的SPReID模型,由一個卷積主幹、一個語義分割分支和兩個聚合點組成。對於卷積主幹,同樣是Inception-V3,但移除了全域性池化層,因此輸出的是stride=32(縮小32倍)的2048個通道的tensor.
Baseline模型為主幹網路加全域性池化,輸出2048維的全域性表示。訓練採用多分類的softmax交叉熵損失。在測試時,我們直接採用分類層前的2048維向量來進行檢索匹配。
第4節我們展示了選用不同主幹網路Inception-V3、ResNet-50、ResNet-152時效能的變化。
為了挖掘區域性視覺線索,我們用五個不同身體區域(前景、頭、上身、下身、鞋子)的概率圖。這個概率圖生成自語義分割模型和每個通道的L1規範化。在SPReID,我們多次池化CNN主幹網路的輸出響應,每次用五張概率圖中的一個。概率圖作為權值,對輸出響應做矩陣點乘。就得到了5個2048為特徵向量,每個代表一個身體部位。接著,我們對頭、上身、下身、鞋子的表示進行元素層面的最大操作。接著將輸出和前景以及全域性表示進行串接。
我們提出的技術能夠應用於任何CNN主幹結構。注意到語義分割通常需要高解析度影象,因此我們對輸入影象進行了雙線性插值,後面又對輸出響應進行了同樣的操作以適應人體語義分割的輸出。
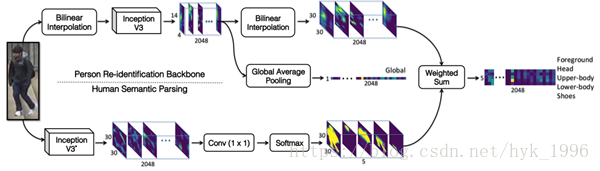
圖1 SPReID
四.實驗
4.1 資料集和評估方法
基於三個基準資料集Market1501,CUHK03和DukeMTMC-reID.
Market1501:包括了1501個行人的32668張影象,由五個高解析度和一個低解析度攝像頭拍攝得到,在這個資料集中,用DPM方法得到了行人包圍框。因此,有些包圍框沒有配準好。在它的標準評估協議中,訓練集包括了751個行人共12936張影象。測試集裡,沒有出現在訓練集的750個行人的影象被用來建立gallery和query集。這些集合分別包括了19734和3368張影象。
DukeMTMC-reID:這個資料集的行人影象由DukeMTMC跟蹤資料集中提取得到。DukeMTMC資料集用8個高解析度攝像頭得到,行人包圍框由人工標註。DukeMTMC-reID的標準評估協議和Market1501的格式一致。具體地說,702個人的16522張影象作為訓練集。對於gallery和probe,分別有16522和2228張影象,主體為不曾出現在訓練集中的702個人。
CUHK03:有1467個行人共13164張影象。這些影象由6個監控攝像頭記錄,每個人被2個不同的攝像頭拍攝到。這個資料集用到了人手標註和DPM檢測兩種方法來找行人包圍框。它的評估協議和上面兩個資料集不同,在我們的實驗中,按照原論文提到的標準協議來評估得到人手標註資料集的結果。
除了用到上面提到的這些資料集來評估結果外,我們還採用了3DPeS, CUHK01, CUHK02, PRID, PSDB, Shinpuhkan和VIPeR資料集來拓展我們的訓練集。這些訓練集被彙集得到一個包括111000張影象的訓練集。我們用CMC曲線和mAP來評估重識別模型好壞。所有實驗都設定為單查詢(single query)。
4.2 訓練網路
為了訓練我們的重識別模型,我們彙總了10個不同的重識別基準,詳見4.1節,其中總共約111,000個影象約17,000個身份。基線模型僅在完整影象上執行,不使用語義分割。我們首先使用尺寸為492×164的輸入影象對它們進行200K次迭代訓練。然後,我們微調每個額外的50K迭代,但採用更高的輸入解析度748×246。我們在Market-1501,CUHK03和DukeMMC-reID資料集上分別進行微調。SPReID的訓練是在10個數據集的聚合上完成的,其設定與上述完全相同。其相關實驗中的輸入影象解析度設定為512×170。
我們在Look into Person(LIP)[14]資料集上訓練人類語義解析模型,該資料集由約30,000個影象和20個語義標籤組成。然後將不同區域的預測概率組合在一起以建立5個粗略標籤(Foreground, Head, Upper-body, Lower-body and Shoes),以便解析人體以供重識別。我們的實驗表明,即使在嚴重姿態變化和遮擋的情況下,人類語義分析模型也能夠很好地定位各種人體部位。儘管超出了本工作的範圍,為了展示我們人類語義解析的質量,我們在表1中顯示,在LIP驗證集中,我們的模型勝過了當前的最好結果。圖2說明了我們的人類語義分析模型如何分割來自DukeMTMC-reID重識別基準的示例影象。
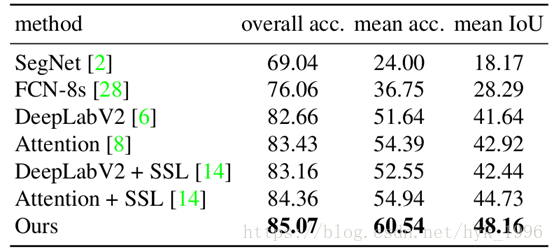 表1 人體語義分割模型的效能(在LIP驗證集上)
表1 人體語義分割模型的效能(在LIP驗證集上)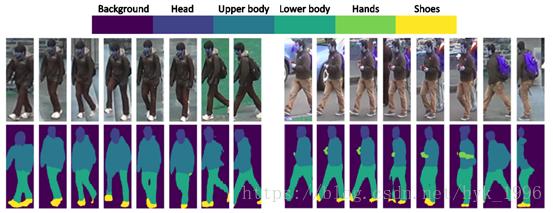
圖2 我們的語義分割模型對DukeMTMC-reID資料集上的影象做的測試
4.3 重識別效能
在本節中,我們從分析baseline重識別模型的表現開始。我們將展示輸入影象解析度、對大影象尺寸的微調、backbone的不同選擇、以及最後的聚合結點之間的權重共享的效果。我們展示了基準模型可以大幅度超越當前最先進的技術,這要歸功於我們簡單而精心設計的訓練策略。然後,我們定量說明SPReID在利用人類語義解析進行行人重識別時的有效性。我們在三個基準資料集上通過與其他先進演算法進行比較來總結本節。
輸入影象解析度的影響:在表2中,我們展示了使用不同輸入解析度來訓練網路時,我們的Inception-V3基線模型的定量結果。除此之外,其餘設定/引數對於所有模型都是相同的。我們觀察到,在所有三個資料集上,對更高解析度的輸入影象進行訓練可獲得更好效能(mAP和重識別率)。儘管如我們所預期的那樣,當我們考慮rank-10和rank-1時,這種差距往往會縮小。當我們合併10個不同的重識別資料集時,模型-S、模型-M和模型-L在約17K個身份的111K張影象上訓練。由於對高解析度影象的訓練在計算上是昂貴的,為了進一步推進效能邊界,我們採用經過訓練的Model-L並使用748×246(比Model-L的預訓練的影象大1.5倍)的輸入影象對其進行微調。表2顯示,這種微調做法,表示為Model-L ft,在Model-L的頂部產生平均4.75%的mAP和1.71%的rank-1。因此,我們確認使用大輸入影象來訓練重識別模型的優勢。
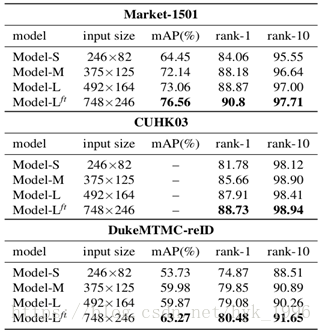
表2 採用不同輸入解析度來訓練模型的結果
重識別主幹架構的選擇:表3顯示了在我們的基準模型中改變重識別主幹架構的效果。 儘管Inception-V3[37]的體系結構相對較淺,但它與ResNet-152 [16]相比具有極強的競爭力,同時效能也大大超過ResNet-50 [16],而ResNet-50的深度大致相同。表3還顯示,通過用高解析度影象進行微調而實現的效能增益(參考表2)在各種架構選擇中都是有效的。在我們的實驗中,我們觀察到ResNet-152的計算成本比Inception-V3高3倍(由前向+後向時間測量)。因此,鑑於它們相對相似的效能,我們選擇了Inception-V3作為我們的主要骨幹架構。
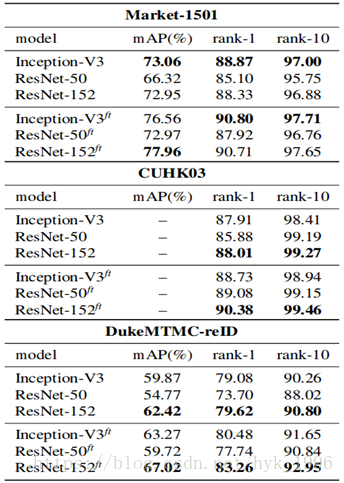
表3 不同骨幹結構對效能的影響。ft為高解析度影象fine-tune模型。實驗中Resnet152是InceptionV3計算代價的3倍。
SPReID效能:表4比較了我們提出的SPReID與Inception-V3基線重識別的效能。 所有模型都使用第4.2節中詳述的設定進行訓練。我們觀察到無論是否有前景變化(分別表示為SPReID w/fg和SPReID wo/fg)都優於Inception-V3基線,而它們的組合(L2-標準化+級聯)導致效能進一步提高。利用SPReID進行人類語義分析可以改善基線重識別模型:Market-1501,mAP為6.61%,rank-1為2.58%,CUHK03為1.33%,DukeMMC-reID,分別為8.91%和4.22%。由於Inception-V3基線和SPReID之間的唯一區別在於他們如何聚合最終卷積層的啟用,我們可以證實我們提出的方法在有效利用人類語義分析來改善人重識別方面的優勢。
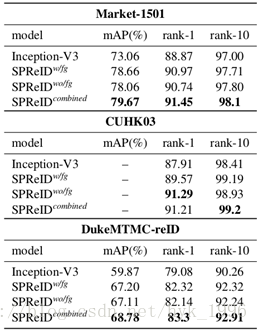
表4 SPReID的效能
權值分配的影響:圖1所示的SPReID模型有兩個聚合頭。一個簡單地執行全域性平均池化,而另一個使用與不同人體部位關聯的概率圖作為權重來聚合卷積啟用。表5根據兩個聚合頭是否共享重識別主幹網路來比較兩種情況。我們觀察到,除了CUHK03 [24]以外,相互獨立的骨幹網路結構比權值共享的效果略好,但經過用非常高解析度的影象微調後,差距會縮小。值得注意的是,在這兩種情況下,SPReID都優於Inception-V3基線(參考表4)。
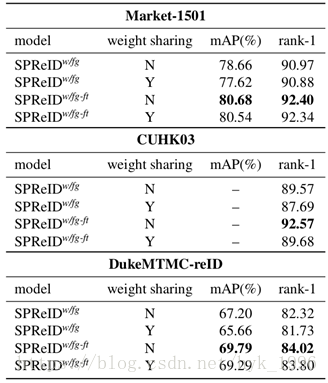
表5 全域性平均池化和基於語義池化的主幹網路權值是否共享對效能的影響
從表6中,我們觀察到,使用我們提出的訓練程式進行訓練時,基線重識別模型勝過當前的最新技術。這些結果特別有趣,因為模型不那麼複雜,並且也很直接。當利用重排序[51]時,改善幅度進一步增加。因此,我們確認一個沒有花裡胡哨的簡單模型足以實現最先進的重識別效能。表6顯示,SPReID可以有效利用來自人體部位的區域性視覺提示。在所有三個資料集中,SPReID combined-ft優於Inception-V3 ft基線,並具有較大的優勢。雖然,當模型與ResNet-152 ft強基線結合時,差距會縮小。與前一種情況類似,通過重排序作為後期處理,效能將進一步提高。
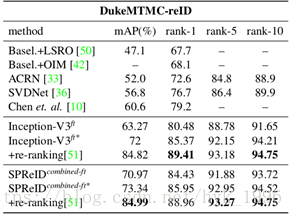
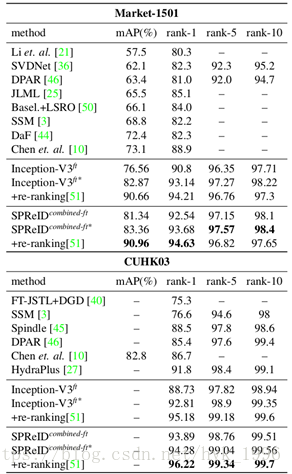
表6 和最先進方法的比較。*號表示和ResNet-152ft進行結合(L2標準化和串接)
五.實現細節
行人重識別:在兩個訓練階段,mini-batch size設定為15,動量為0.9,我們使用權值衰減(0.0005)和梯度截斷(2.0)。第一階段的初始化學習率為0.01,第二階段減少為0.001。在整個訓練過程中,我們衰減學習率10次,用rate=0.9的指數偏移。我們用Nesterov Accerlarated Gradient訓練模型,用ImageNet的預訓練模型初始化權值。
人體語義解析:我們訓練我們的人類語義解析模型進行30K迭代,其中Inception-V3主幹,空洞空間金字塔池化和1x1卷積層的初始學習率分別設定為0.01,0.1和0.1。 除了使用512×512輸入影象的輸入解析度之外,其餘引數和設定與用於重識別模型訓練的引數和設定類似。
六.結論
在本文中,我們首先提出了兩個主要問題。首先,要達到最先進的效能,重識別模型是否需要很複雜。 其次,對人體部位的包圍框是否是利用區域性視覺線索的最佳辦法。 通過本文,我們用廣泛的一系列實驗解決了這兩個問題。 我們證明,當在大量高解析度影象上正確訓練時,實際上一個簡單的深度卷積體系結構可以勝過當前的最新技術。我們還證明,通過在我們提出的SPReID框架中利用人類語義分析,可以進一步提高最先進的基線模型的效能。 SPReID對重識別骨幹進行最小限度的修改,併為利用人體部位提供更自然的解決方案。 我們希望,這項工作鼓勵研究團體更多地投入使用人類語義解析來進行重識別任務。