幾分鐘走進神奇的光流|FlowNet 2.0: Evolution of Optical Flow Estimation with Deep Networks
故事背景
那是15年的春天,本文的作者和其他幾個人,使用CNN做光流估計,於是FlowNet成了第一個用CNN做光流的模型,當時的結果還不足以和傳統結果相匹配。2016年冬天,作者和一群小夥伴又基於Flow Net的工作進行了改進,效果得到了提升,可以與傳統方法相匹敵。
15年的思想主要是把兩張用來估計光流資訊的圖片輸入網路,經過訓練使網路學到光流資訊,後面會講到當時用到的兩個網路。
作者
Eddy Ilg, Nikolaus Mayer, Tonmoy Saikia, Margret Keuper, Alexey Dosovitskiy, Thomas Brox
專案地址
http://lmb.informatik.uni-freiburg.de/Publications/2016/IMKDB16/
FlowNet1.0 地址
http://lmb.informatik.uni-freiburg.de/resources/binaries/
一句話總結
本文依然是用CNN來做光流估計,提出了一種訓練方法,引入了Stack的結構,對小位移單獨處理,提高了網路的效果。好評!
看點
- 訓練時資料集的使用
- 網路結構
- 還有請留言:-D
0. 預備~
到了大家最喜歡看網路結構的時候了
這一節主要介紹在第一版FlowNet中的兩個網路結構及幾個資料庫
0.1 FlowNetS
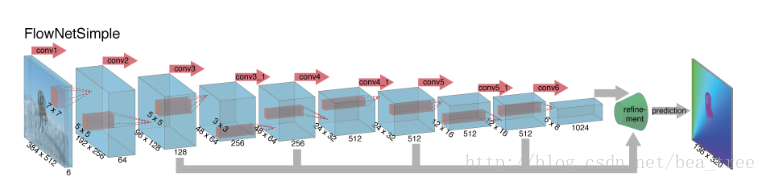
第一個模型:FlowNetS
主要特色:
- 輸入由原來的一張圖片變為了兩張,通道數由3變為6
- 多層feature引入最後的Refinement模組,Refinement的具體結構將在後面涉及
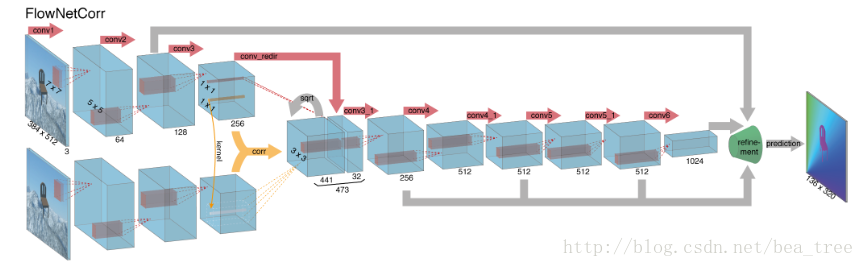
0.2 FlowNetC
第二個模型:FlowNetC
主要特色:
- 圖片不再直接放到通道,而是先分別通過一個三層網路 然後進入一個名叫 correlation layer的層
0.3 correlation layer
該層的主要作用是比較來自兩張圖片的feature map的關係,文章用了卷積的形式,還是比較巧妙的,具體方程如下
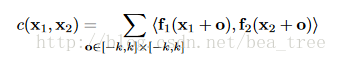
C代表correlation,f1和f2分別代表兩個feature map, k代表要比較的區域,x1,x2分別代表兩個feature map上的點。具體的計算流程還是看原文字,這裡只要知道這個層的主要作用是計算兩個層的關係就可以了。
0.4 Refinement
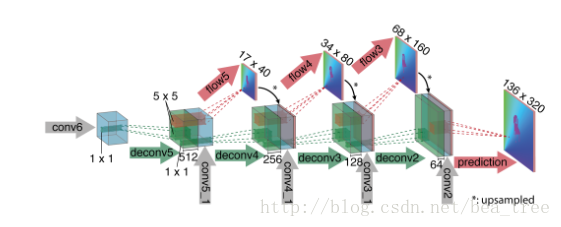
這裡就是不斷的上採然後 前面的feature map的reuse,這裡還加入了預測得到的flow。具體細節同樣請看第一版的FlowNet
總的來說,FlowNetS的效果不如FlowNetC的效果
0.5 Chairs 資料庫
一群在各種背景下會飛的椅子,確切的說是22872對椅子

0.6 FlyingThings3D(下面稱為Things3D)
一堆會飛的東西 但是更接近於現實,22k對


0.7 Sintel
一共1041對

1. Dataset Schedules
本文的三個訓練策略
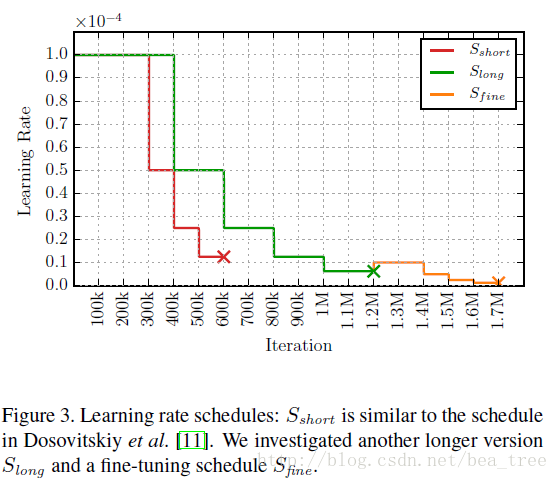
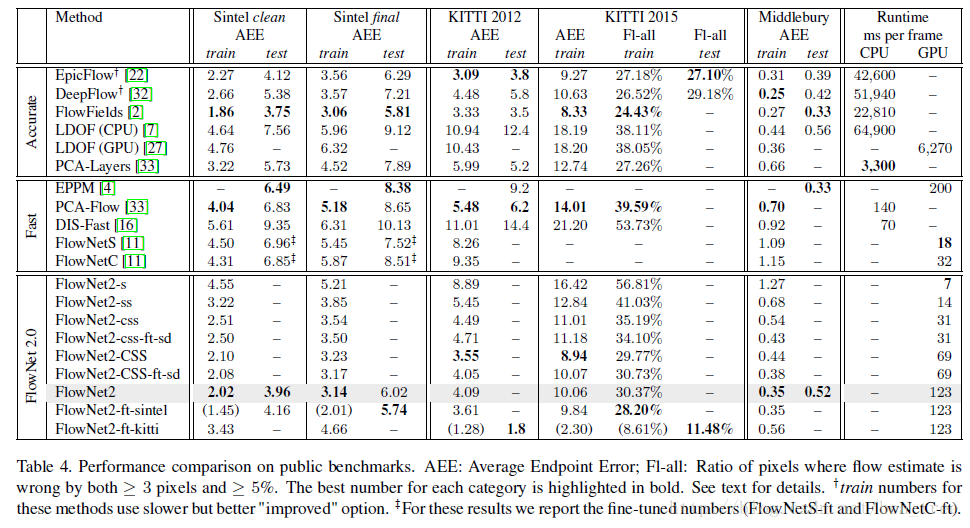
使用不同的訓練策略和不同的資料集順序得到的結果:
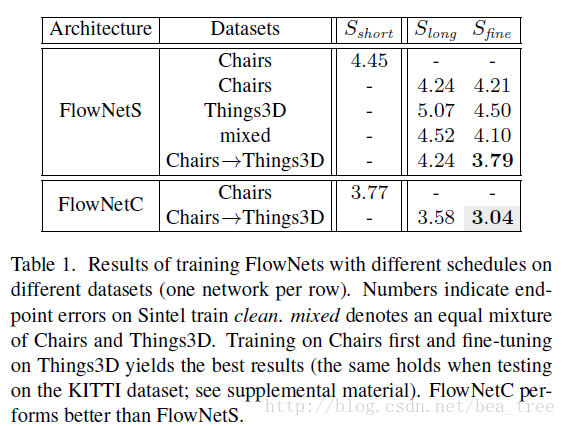
這裡可以看出,先使用Chairs這樣簡單的樣本然後再使用Things3D,可以得到比一起mixed訓練更好的結果。
2. Stacking Networks
結構如下:
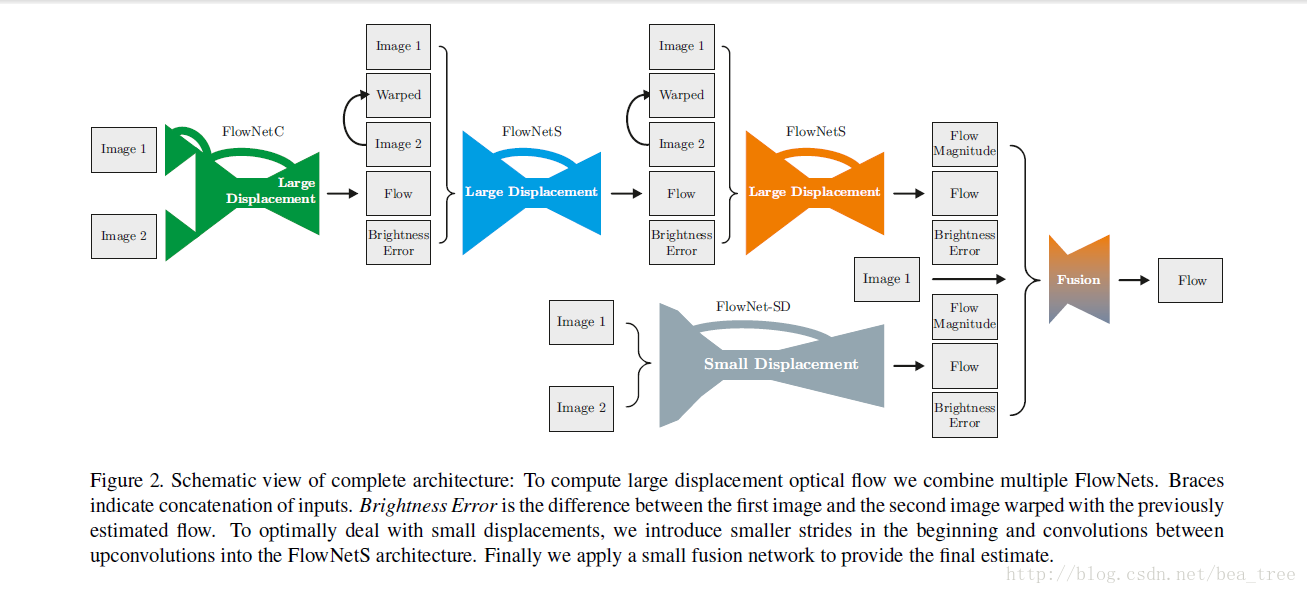
- 首先,第一個網路的輸入是兩幅圖片
- 其次,在之後的網路含有warp layer時
- 輸入經過warp layer及雙線性差值之後的 img2及其I1的差值(brightness error)及img1,img2,flow(共5種)
- 所謂warplayer 就是將原圖根據得到的flow的值進行位置變化
- 再次,當沒有warp layer時 輸入 img1 img2 及flow(3種)
2.1 Stacking Two Networks
這部分只用FlowNetS一種網路,具體實驗設計如下表:

實驗觀察:
1. 不加warp時,疊加網路,在Chairs資料集上錯誤率下降,Sintel上上升,文章認為,這是由於過擬合造成的(訓練是在Chairs上訓練的)
2. Warp的效果很明顯
3. 在Net1上加輔助loss有利
4. 在Sintel資料集上的最優結果來自fixed net1+training net2+warp
2.2 Stacking Multiply Diverse Networks
文章在這裡除了引入FlowNetS,FlowNetC,還引入了每層只有3/8個通道的FlowNetc和FlowNets以小寫的s和c表示,3/8的來源:
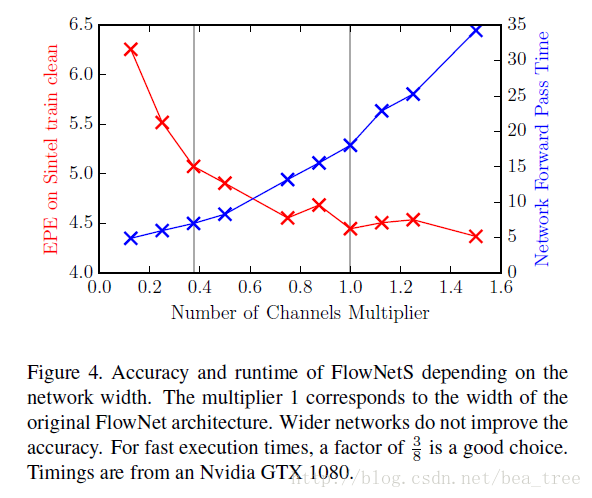
這小節做的試驗訓練方法都是用Chairs->Things3D的方法,且網路按照one-by-one的設定訓練
試驗設定及結果:
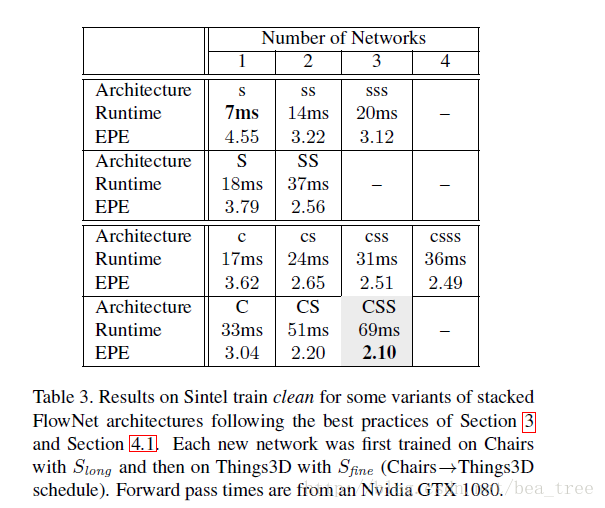
CSS表示FlowNetC+2個FlowNetS,其他以此類推,由此可見,兩個小網路雖然在一起引數更少但是效果好於一個大網路
2.3 Small Displacement
上面使用的Chairs 及Things3D資料集相對真實場景的變動較大,所以訓練的效果在實際應用時並不太好,所以作者就重新做了一個數據集,叫作ChairsSDHom, 使用FlowNet2-CSS在ChairsSDHom及Sintel上finetune 得到FlowNet-Css-ft-sd, finetune時對small displacement的loss權重加強,效果在微變物體上表現變好,變化大的物體的效果也還不錯,但是仍然還有噪聲。
於是作者就設計了網路結構圖中右下角的FlowNet-SD。
主要改進:
- 將FlowNetS的第一層的stride=2變為1
- 將7x7和5x5變為幾個3x3
- 在上取樣前加了卷積層用了平滑噪聲
2.4 Fusion Net
最後的Fusion用了融合前面FlowNetCSS-ft-sd及FlowNet-SD的結果,結構如下:
3 實驗
隨便看看就可以了