
Storm 1.0.2
單詞計數拓撲WordCountTopology實現的基本功能就是不停地讀入一個個句子,最後輸出每個單詞和數目並在終端不斷的更新結果,拓撲的資料流如下:
- 語句輸入Spout: 從資料來源不停地讀入資料,並生成一個個句子,輸出的tuple格式:{"sentence":"hello world"}
- 語句分割Bolt: 將一個句子分割成一個個單詞,輸出的tuple格式:{"word":"hello"} {"word":"world"}
- 單詞計數Bolt: 儲存每個單詞出現的次數,每接到上游一個tuple後,將對應的單詞加1,並將該單詞和次數傳送到下游去,輸出的tuple格式:{"hello":"1"} {"world":"3"}
- 結果上報Bolt: 維護一份所有單詞計數表,每接到上游一個tuple後,更新表中的計數資料,並在終端將結果打印出來。
開發步驟:
1.環境
- 作業系統:mac os 10.10.3
- JDK: jdk1.8.0_40
- IDE: intellij idea 15.0.3
- Maven: apache-maven-3.0.3
2.專案搭建
- 在idea新建一個maven專案工程:storm-learning
- 修改pom.xml檔案,加入strom核心的依賴,配置slf4j依賴,方便Log輸出

<dependencies>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>1.6.1</version>
</dependency>
<dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-core</artifactId>
<version>1.0.2</version>
</dependency>
</dependencies>
3. Spout和Bolt元件的開發
- SentenceSpout
- SplitSentenceBolt
- WordCountBolt
- ReportBolt
SentenceSpout.java

1 public class SentenceSpout extends BaseRichSpout{ 2 3 private SpoutOutputCollector spoutOutputCollector; 4 5 //為了簡單,定義一個靜態資料模擬不斷的資料流產生 6 private static final String[] sentences={ 7"The logic for a realtime application is packaged into a Storm topology", 8 "A Storm topology is analogous to a MapReduce job", 9 "One key difference is that a MapReduce job eventually finishes whereas a topology runs forever", 10 " A topology is a graph of spouts and bolts that are connected with stream groupings" 11 }; 12 13 private int index=0; 14 15 //初始化操作 16 public void open(Map map, TopologyContext topologyContext, SpoutOutputCollector spoutOutputCollector) { 17 this.spoutOutputCollector = spoutOutputCollector; 18 } 19 20 //核心邏輯 21 public void nextTuple() { 22 spoutOutputCollector.emit(new Values(sentences[index])); 23 ++index; 24 if(index>=sentences.length){ 25 index=0; 26 } 27 } 28 29 //向下遊輸出 30 public void declareOutputFields(OutputFieldsDeclarer outputFieldsDeclarer) { 31 outputFieldsDeclarer.declare(new Fields("sentences")); 32 } 33 }
SplitSentenceBolt.java
1 public class SplitSentenceBolt extends BaseRichBolt{ 2 3 private OutputCollector outputCollector; 4 5 public void prepare(Map map, TopologyContext topologyContext, OutputCollector outputCollector) { 6 this.outputCollector = outputCollector; 7 } 8 9 public void execute(Tuple tuple) { 10 String sentence = tuple.getStringByField("sentences"); 11 String[] words = sentence.split(" "); 12 for(String word : words){ 13 outputCollector.emit(new Values(word)); 14 } 15 } 16 17 public void declareOutputFields(OutputFieldsDeclarer outputFieldsDeclarer) { 18 outputFieldsDeclarer.declare(new Fields("word")); 19 } 20 }
WordCountBolt.java
1 public class WordCountBolt extends BaseRichBolt{ 2 3 //儲存單詞計數 4 private Map<String,Long> wordCount = null; 5 6 private OutputCollector outputCollector; 7 8 public void prepare(Map map, TopologyContext topologyContext, OutputCollector outputCollector) { 9 this.outputCollector = outputCollector; 10 wordCount = new HashMap<String, Long>(); 11 } 12 13 public void execute(Tuple tuple) { 14 String word = tuple.getStringByField("word"); 15 Long count = wordCount.get(word); 16 if(count == null){ 17 count = 0L; 18 } 19 ++count; 20 wordCount.put(word,count); 21 outputCollector.emit(new Values(word,count)); 22 } 23 24 25 public void declareOutputFields(OutputFieldsDeclarer outputFieldsDeclarer) { 26 outputFieldsDeclarer.declare(new Fields("word","count")); 27 } 28 }
ReportBolt.java
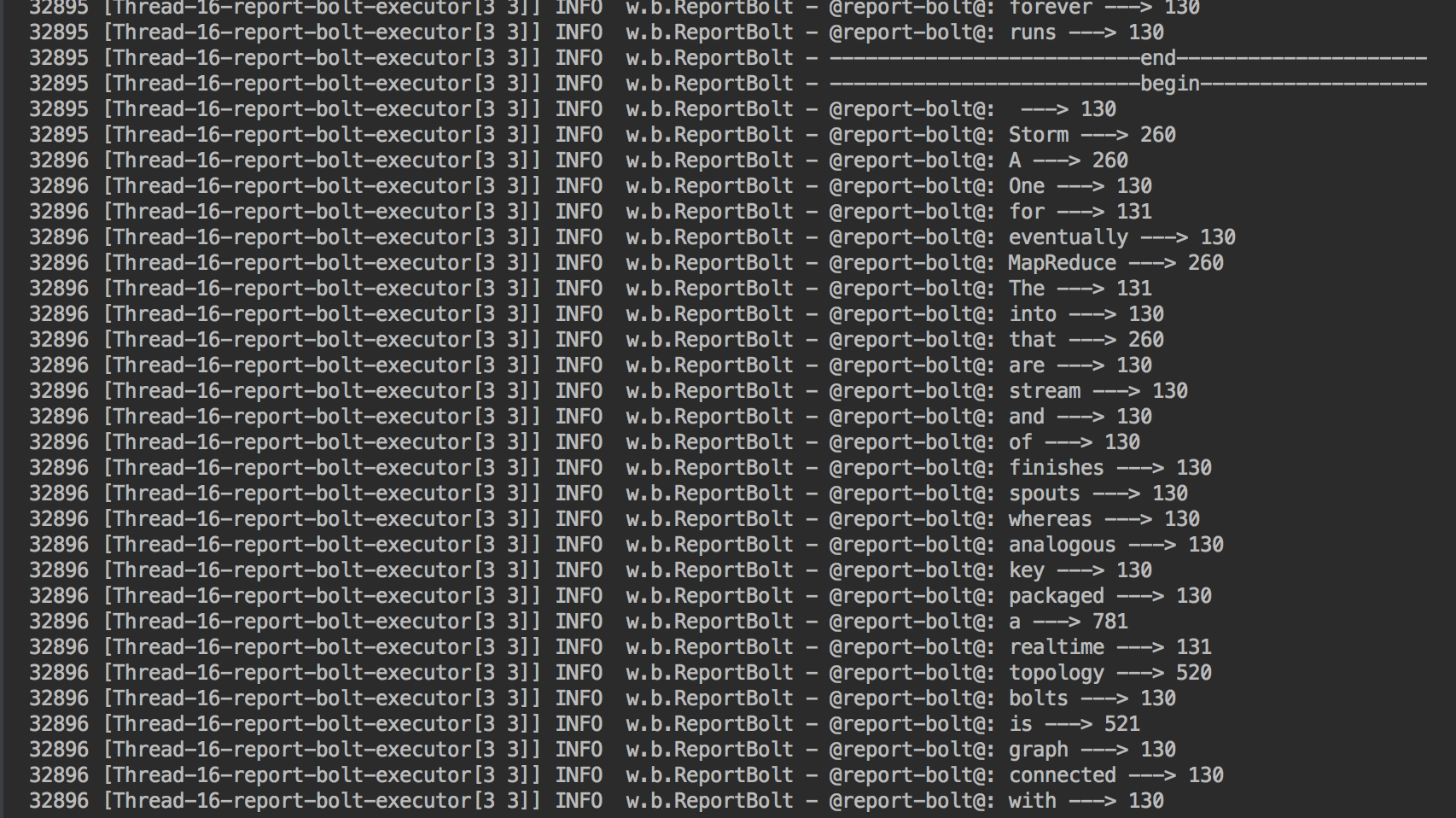
1 public class ReportBolt extends BaseRichBolt { 2 3 private static final Logger log = LoggerFactory.getLogger(ReportBolt.class); 4 5 private Map<String, Long> counts = null; 6 7 public void prepare(Map map, TopologyContext topologyContext, OutputCollector outputCollector) { 8 counts = new HashMap<String, Long>(); 9 } 10 11 public void execute(Tuple tuple) { 12 String word = tuple.getStringByField("word"); 13 Long count = tuple.getLongByField("count"); 14 counts.put(word, count); 15 //列印更新後的結果 16 printReport(); 17 } 18 19 public void declareOutputFields(OutputFieldsDeclarer outputFieldsDeclarer) { 20 //無下游輸出,不需要程式碼 21 } 22 23 //主要用於將結果打印出來,便於觀察 24 private void printReport(){ 25 log.info("--------------------------begin-------------------"); 26 Set<String> words = counts.keySet(); 27 for(String word : words){ 28 log.info("@[email protected]: " + word + " ---> " + counts.get(word)); 29 } 30 log.info("--------------------------end---------------------"); 31 } 32 }
4.拓撲配置
- WordCountTopology
1 public class WordCountTopology { 2 3 private static final Logger log = LoggerFactory.getLogger(WordCountTopology.class); 4 5 //各個元件名字的唯一標識 6 private final static String SENTENCE_SPOUT_ID = "sentence-spout"; 7 private final static String SPLIT_SENTENCE_BOLT_ID = "split-bolt"; 8 private final static String WORD_COUNT_BOLT_ID = "count-bolt"; 9 private final static String REPORT_BOLT_ID = "report-bolt"; 10 11 //拓撲名稱 12 private final static String TOPOLOGY_NAME = "word-count-topology"; 13 14 public static void main(String[] args) { 15 16 log.info(".........begining......."); 17 //各個元件的例項 18 SentenceSpout sentenceSpout = new SentenceSpout(); 19 SplitSentenceBolt splitSentenceBolt = new SplitSentenceBolt(); 20 WordCountBolt wordCountBolt = new WordCountBolt(); 21 ReportBolt reportBolt = new ReportBolt(); 22 23 //構建一個拓撲Builder 24 TopologyBuilder topologyBuilder = new TopologyBuilder(); 25 26 //配置第一個元件sentenceSpout 27 topologyBuilder.setSpout(SENTENCE_SPOUT_ID, sentenceSpout, 2); 28 29 //配置第二個元件splitSentenceBolt,上游為sentenceSpout,tuple分組方式為隨機分組shuffleGrouping 30 topologyBuilder.setBolt(SPLIT_SENTENCE_BOLT_ID, splitSentenceBolt).shuffleGrouping(SENTENCE_SPOUT_ID); 31 32 //配置第三個元件wordCountBolt,上游為splitSentenceBolt,tuple分組方式為fieldsGrouping,同一個單詞將進入同一個task中(bolt例項) 33 topologyBuilder.setBolt(WORD_COUNT_BOLT_ID, wordCountBolt).fieldsGrouping(SPLIT_SENTENCE_BOLT_ID, new Fields("word")); 34 35 //配置最後一個元件reportBolt,上游為wordCountBolt,tuple分組方式為globalGrouping,即所有的tuple都進入這一個task中 36 topologyBuilder.setBolt(REPORT_BOLT_ID, reportBolt).globalGrouping(WORD_COUNT_BOLT_ID); 37 38 Config config = new Config(); 39 40 //建立本地叢集,利用LocalCluster,storm在程式啟動時會在本地自動建立一個叢集,不需要使用者自己再搭建,方便本地開發和debug 41 LocalCluster cluster = new LocalCluster(); 42 43 //建立拓撲例項,並提交到本地叢集進行執行 44 cluster.submitTopology(TOPOLOGY_NAME, config, topologyBuilder.createTopology()); 45 } 46 }
5.拓撲執行
- 方法一:通過IDEA執行
在idea中對程式碼進行編譯compile,然後run;
觀察控制檯輸出會發現,storm首先在本地自動建立了執行環境,即啟動了zookepeer,接著啟動nimbus,supervisor;然後nimbus將提交的topology進行分發到supervisor,supervisor啟動woker程序,woker程序裡利用Executor來執行topology的元件(spout和bolt);最後在控制檯發現不斷的輸出單詞計數的結果。
zookepeer的連線建立

nimbus啟動

supervisor啟動

worker啟動

Executor啟動執行
結果輸出
- 方法二:通過maven來執行
- 進入到該專案的主目錄下:storm-learning
- mvn compile 進行程式碼編譯,保證程式碼編譯通過
- 通過mvn執行程式:
mvn exec:java -Dexec.mainClass="wordCount.WordCountTopology" - 控制檯輸出的結果跟方法一一致
其他資料:
相關推薦
Storm 1.0.2
單詞計數拓撲WordCountTopology實現的基本功能就是不停地讀入一個個句子,最後輸出每個單詞和數目並在終端不斷的更新結果,拓撲的資料流如下: 語句輸入Spout: 從資料來源不停地讀入資料,並生成一個個句子,輸出的tuple格式:{"sentence"
Storm的StreamID使用樣例(版本1.0.2)
alt constant rate fields olt topology next blog for 隨手嘗試了一下StreamID的的用法。留個筆記。 ==數據樣例== { "Address": "小橋鎮小橋中學對面", "CityCode": "
Oracle 12.1.0.2 對JSON的支持
使用 lin 1.5 text lob mysq 索引 acl var Oracle 12.1.0.2版本有一個新功能就是可以存儲、查詢、索引JSON數據格式,而且也實現了使用SQL語句來解析JSON,非常方便。JSON數據在數據庫中以VARCHAR2, CLOB或者BLO
為什麽0.1+0.2=0.30000000000000004
0.1+0.2浮點數運算你使用的語言並不爛,它能夠做浮點數運算。計算機天生只能存儲整數,因此它需要某種方法來表示小數。這種表示方式會帶來某種程度的誤差。這就是為什麽往往 0.1 + 0.2 不等於 0.3。為什麽會這樣?實際上很簡單。對於十進制數值系統(就是我們現實中使用的),它只能表示以進制數的質因子為分母
面試題3:在一個長度為n的數組裏的所有數字都在0到n-1的範圍內。 數組中某些數字是重復的,但不知道有幾個數字是重復的。也不知道每個數字重復幾次。請找出數組中任意一個重復的數字。 例如,如果輸入長度為7的數組{2,3,1,0,2,5,3},那麽對應的輸出是第一個重復的數字2。
length value 如果 while 返回 sys public ret || package siweifasan_6_5; /** * @Description:在一個長度為n的數組裏的所有數字都在0到n-1的範圍內。 * 數組中某些數字是重復的,
spark(2.1.0) 操作hbase(1.0.2)
hadoop mon per bsp trac 事先 com maker scala 1、spark中引入外部jar包 1)創建/usr/software/spark_jars目錄,放入spark操作hbase的jar包:hbase-annotations-1.0.2.
aix下oracle 12.1.0.2 asmca不能打開的故障
chown clas srv 無法 password scope acl div 之前 因為要添加一個新的13T磁盤組,所以決定通過asmca處理。 結果輸入asmca之後,沒有反應,前後兩天都是如此。 第三天,IBM的存儲工程師已經把心的MPIO掛上,如果還無法操作,只能
如何解決JavaScript中0.1+0.2不等於0.3
幫我 console 解決 如何解決 進制 範圍 無限 scrip 接下來 console.log(0.1+0.2===0.3)// true or false?? 在正常的數學邏輯思維中,0.1+0.2=0.3這個邏輯是正確的,但是在JavaScr
12.1.0.2.0 RAC GI PSU 12.1.0.2.180116
12.1.0.2.180116rac12c01:/home/grid&$ORACLE_HOME/OPatch/opatch lsinv Oracle Interim Patch Installer version 12.2.0.1.12Copyright (c) 2018, Oracle Corpor
oracle 12c 12.1.0.2.0 BUG 22562145
erro can action fail may seq arc cti -- Wed May 23 17:46:14 2018TT01: Standby redo logfile selected for thread 1 sequence 42251 for desti
oracle 12C ORA-07445 12.1.0.2.0
idt dba summary left col 12c TE fff feedback Mon Jun 11 14:06:23 2018 Exception [type: SIGSEGV, SI_KERNEL(general_protection)] [ADDR:0x0]
Oracle 12.1.0.2 卸載數據庫
ssi his listener sep directory odi ani ted pre 本案例數據庫(12.1.0.2)安裝在文件系統上,因此只需要deinstall 數據庫即可。 前提: (1)關閉數據庫,shutdown immediate; (2)關閉監聽,ls
ArcSDE for Oracle 12.1.0.2 In-Memory元件測試
如今,記憶體資料庫被大家廣泛認可,懂得技術的人都明白,資料從磁碟讀寫肯定比在記憶體中讀寫要慢很多,而且目前也有很多記憶體資料已經有非常成熟的實施經驗,當然,當今資料庫的老大Oracle更加不會無視這個市場,很早就渲染他們Oracle12c的記憶體元件多麼的牛叉,快到不行更是他們經常使用的詞彙。
Oracle 12.1.0.2 對JSON的支援
Oracle 12.1.0.2版本有一個新功能就是可以儲存、查詢、索引JSON資料格式,而且也實現了使用SQL語句來解析JSON,非常方便。JSON資料在資料庫中以VARCHAR2, CLOB或者BLOB進行儲存。Oracle建議使用者在插入JSON資料之前,使用is_json來驗證輸入JSO
為什麼JavaScript裡面0.1+0.2 === 0.3是false
0.1+0.2 === 0.3 //返回是false, 這是為什麼呢?? 我們知道浮點數計算是不精確的,上面的返回式實際上是這樣的:0.1 + 0.2 = 0.30000000000000004 0.1 + 0.2 - 0.3 = 5.551115123125783e-17 5.551115123125
0.1+0.2不等於0.3
在正常的數學邏輯思維中,0.1+0.2=0.3這個邏輯是正確的,但是在JavaScript中0.1+0.2!==0.3,在JavaScript中的二進位制的浮點數0.1和0.2並不是十分精確,在他們相加的結果並非正好等於0.3,而是一個比較接近的數字 0.30000000000000004 ,所以條
!DOCTYPE validators PUBLIC "-//OpenSymphony Group//XWork Validator 1.0.2//EN"
原因是http://www.opensymphony.com/xwork/xwork-validator-1.0.2.dtd已經不是dtd約束檔案了, 開啟網址,發現opensymphony的網址已經遷移走了,因為xwork的東西已經併入struts2中,成為apache的一部分. 所有的dtd
初夏小談:旋轉字串優化1.0,2.0(不用迴圈)
左旋與右旋原理一樣。之前旋轉不夠簡單,對此研究出更加優化的演算法。 #include<Aventador_SQ.h> //優化1.0 void XuanZhuan1(char *arr, int k) { char arr1[1024] = "0"; int i = 0; i
為什麽js中0.1+0.2不等於0.3,怎樣處理使之相等?(轉載)
number 就會 理解 als 轉載 解決 面試 精度 超過 為什麽js中0.1+0.2不等於0.3,怎樣處理使之相等? console.log(0.1+0.2===0.3)// true or false?? 在正常的數學邏輯思維中,0.1+0.2=0.3這個邏輯是正確
0.1+0.2!=0.3
看下面程式碼 double c = 0.1 + 0.2; System.out.println(c); 還有js中 var c = 0.1 + 0.2; console.log(c); 結果都是0.30000000000000004 這是由於java和js 採用IEE