
基於深度機器學習演算法DBNs的風險識別模型
前言:最初關注深度機器學習是聽了NUS的汪晟博士關於深度機器學習平臺SIGNA的介紹,當時就發現深度機器學習是人工智慧的一個革新的進步。但是由於從事的雲端計算和大資料方向的工作,所以平時只是作為自己的興趣領域看了一些相關的入門級資料。最近事業部的同事在討論文物保護的風險識別問題,不自覺地想到能否將深度機器學習運用到文物保護的風險識別中,於是做了一些較深入的研究,設計了一個基於深度機器學習DBN演算法的風險識別模型。
一、傳統機器學習與深度機器學習
傳統機器學習最初是來源於Back Propagation演算法的發明,因此人們在研究中發現可以使用BP演算法和人工神經網路模型對大量的樣本資料進行學習並最終經過反覆調整和優化可以得到樣本資料的統計規律,利用這一統計規律可以進行普通資料的分析以及對將要引起的反應進行一定程度上的預測。這種傳統的機器學習非常依賴於樣本資料的質量,如果沒有高質量、高特徵的樣本資料,會導致預測模型的準確性大大降低。但是這和通過手工的編寫SQL正則表示式來進行資料判斷的方式相比,已經是大大的進步。傳統的機器學習從上世紀80年代末被發現並得到熱捧以來,在風險識別、商業智慧、經濟預測等領域得到大量的應用,相應的也開發出了大量的機器學習演算法如SVM、決策樹、聚類演算法等。總的來說,這是人工智慧第一次引起人們的重大關注和應用,也讓人們更加的憧憬人工智慧的未來。
深度機器學習的興起是來源於《科學》雜誌上一篇文章《Reducing the dimensionality of data with neural networks》,這篇文章的作者是加拿大多倫多大學教授、機器學習領域的泰斗Geoffrey Hinton和他的學生RuslanSalakhutdinov。這篇文章表達了兩個主要觀點:1)多隱層的人工神經網路具有優異的特徵學習能力,學習得到的特徵對資料有更本質的刻畫,從而有利於視覺化或分類;2)深度神經網路在訓練上的難度,可以通過“逐層初始化”(layer-wise pre-training)來有效克服。自此人們開始了深度機器學習的研究和探索,目前深度機器學習的演算法還是主要借鑑傳統的機器學習演算法,但是在不斷的實踐和研究中一些神一樣存在的大牛也開發出了幾個深度機器學習演算法如(RBM)限制波爾茲曼機 、Deep Belief Networks深信度網路等。
二、Deep Belief Networks深信度網路
Depp Belief Networks(DBN)深信度網路也是加拿大多倫多大學教授、機器學習領域的泰斗Geoffrey Hinton在一篇文章中提出的,一個經典的DBN神經網路如圖1。DBN相比於傳統的機器學習演算法如SVM、聚類演算法、決策樹等有一個更加智慧等優勢,就是DBN可以自主的在訓練過程中發現樣本資料之間的關聯關係和規律,並會通過調節自身的權重值來持久化發現的關聯關係和規律。
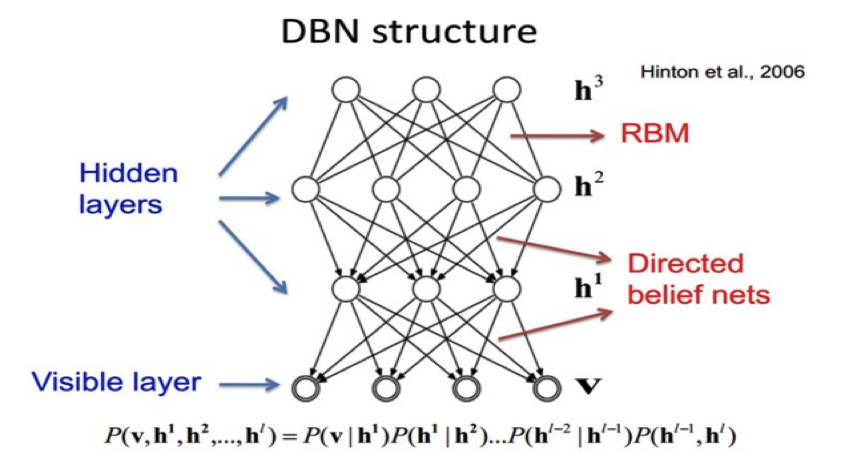
(圖1 )
DBNs是一個概率生成模型,與傳統的判別模型的神經網路相比,概率生成模型是建立一個觀察資料和標籤之間的聯合分佈,對P(Observation|Label)和 P(Label|Observation)都做了評估,而判別模型僅僅評估了P(Label|Observation)。對應到上圖就是P(v|h)和P(h|v),輸入值v通過P(v|h)可以得到隱藏層h,而經過引數值調整之後隱藏層h通過P(h|v)可以得到一個與之前輸入值近似的(理論上是完全一樣)v1,這樣隱藏層就可以作為一個特徵模型(類似於卷積演算法中的卷積核)存在,也就能對輸入值進行識別。
DBNs的核心元件就是RBM(限制玻爾茲曼機),限制玻爾茲曼機是一種特殊型別的馬爾科夫隨機場,它含有一層隨機隱藏單元和一層隨機可見單元。RBM能表示一個二分圖,所有可見的單元連結到所有隱藏單元,而且沒有可見—可見或者隱藏—隱藏之間的連結。具體解釋就是所有的隱藏層的輸入都作為可見層的輸入,所有可見層的輸入都作為隱藏層的輸入,那麼在經過多層的RBM之後,如果最終得到的V1和V值近似相同,那麼我們就可以到一個識別模型,通過在最高層加入監督學習進行最優權重的調整就可以得到一個比較完美的識別模型。
三、基於深度機器學習DBN演算法的風險識別模型
在進行風險識別的機器學習模型訓練中,傳統的機器學習演算法往往會遇到一個無法解決問題的,那就風險樣本資料不足,能夠提取的特徵有限。因為在正常的生產環境中,無害資料遠遠大於有害資料,而基於統計學的傳統機器學習演算法只有在大量的、高質量的樣本資料訓練下才能得到比較理想的識別模型。基於深度機器學習DBN演算法的風險識別模型的思想是使用可以使用有限無害資料進行訓練,通過多層神經網路(RBM)的迭代來進行多維度、多層次的學習,這來快速的增加學習得到特徵數量,這種通過RBM疊加進行貪婪逐層學習的方法在很多領域都取得了很好的效果。下圖2是基於DBN演算法風險識別的訓練模型。
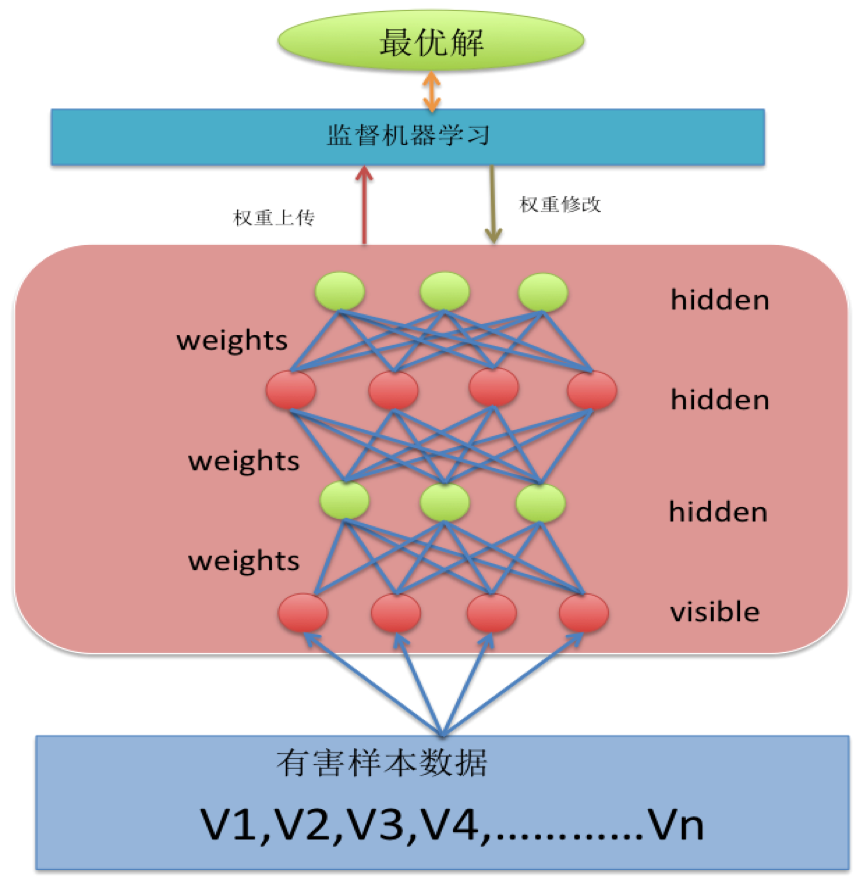
(圖2)
在完成風險識別模型的訓練後,就會形成一個穩定的神經網路。這個神經網路是會自動進行更新學習的,就像人在學習到新的之後會覆蓋掉原來舊的或者錯誤的知識一樣。完成訓練的風險識別模型如下圖3:
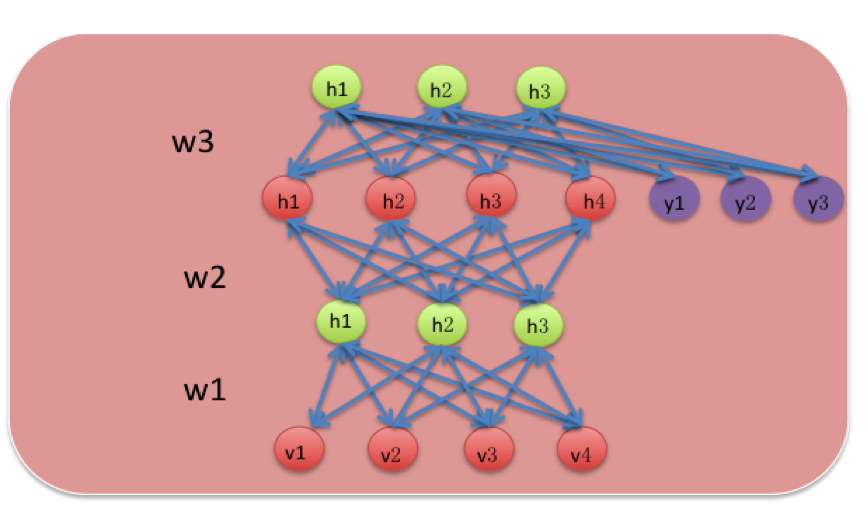
(圖3)
其中y1,y2,y3是進行監督學習時的標籤神經元,w1,w2,w3是經過監督學習的BP演算法後得到的最優權重值,h1,h2,h3,h4則是隱藏層的神經元,v1,v2,v3,v4是視覺化層的神經元。
經過訓練的DBN神經網路就可以作為風險識別模型進行風險的識別,風險識別模型的工作流程如下圖4:
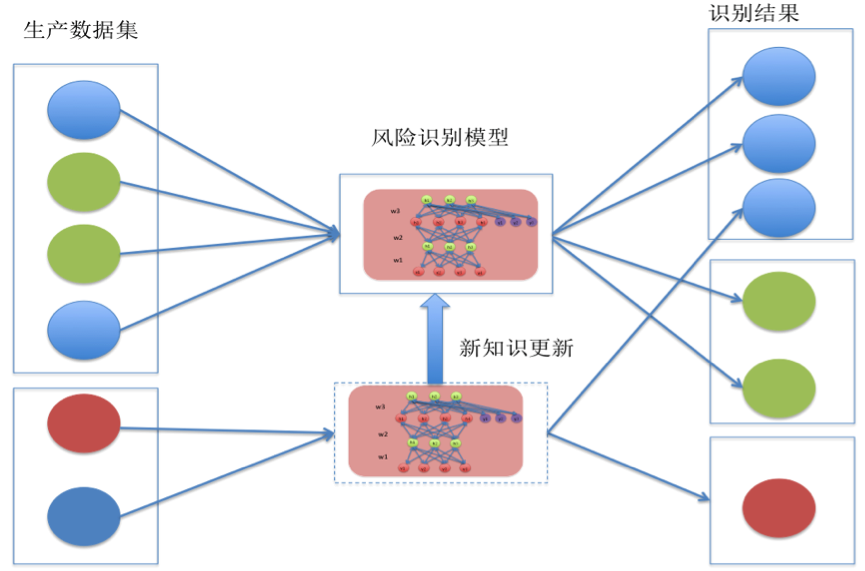
(圖4)
參考資料:
趙英俊
2016、1、19