
工程中常用的特徵選擇方法
當資料預處理完成後,我們需要選擇有意義的特徵輸入機器學習的演算法和模型進行訓練。
為什麼?
(1)降低維度,選擇重要的特徵,避免維度災難,降低計算成本
(2)去除不相關的冗餘特徵(噪聲)來降低學習的難度,去除噪聲的干擾,留下關鍵因素,提高預測精度
(3)獲得更多有物理意義的,有價值的特徵
不同模型有不同的特徵適用型別?
(1)lr模型適用於擬合離散特徵(見附錄)
(2)gbdt模型適用於擬合連續數值特徵
(3)一般說來,特徵具有較大的方差說明蘊含較多資訊,也是比較有價值的特徵
通常來說,從兩個方面考慮來選擇特徵:
特徵是否發散:如果一個特徵不發散,例如方差接近於0,也就是說樣本在這個特徵上基本上沒有差異,這個特徵對於樣本的區分並沒有什麼用。
特徵與目標的相關性:這點比較顯見,與目標相關性高的特徵,應當優選選擇。除方差法外,本文介紹的其他方法均從相關性考慮。
根據特徵選擇的形式又可以將特徵選擇方法分為3種:
- Filter:過濾法,按照發散性或者相關性對各個特徵進行評分,設定閾值或者待選擇閾值的個數,選擇特徵。通過該方法選出來的特徵與具體的預測模型沒有關係,因此具有更好的泛化能力。
- Wrapper:包裝法,根據目標函式(通常是預測效果評分),每次選擇若干特徵,或者排除若干特徵。圍繞一定的預測模型,預測模型的估計誤差一定程度上反映了特徵的有用性。
- Embedded:整合法,先使用某些機器學習的演算法和模型進行訓練,得到各個特徵的權值係數,根據係數從大到小選擇特徵。

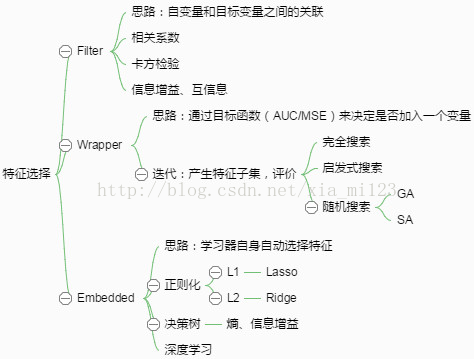
Filter
- 方差選擇法
使用方差選擇法,先要計算各個特徵的方差,然後根據閾值,選擇方差大於閾值的特徵。
- 相關係數法
使用相關係數法,先要計算各個特徵對目標值的相關係數以及相關係數的P值,選擇top N。
- 互資訊法
經典的互資訊也是評價定性自變數對定性因變數的相關性的,互資訊計算公式如下:
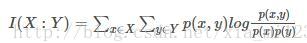
同理,選擇互資訊排列靠前的特徵作為最終的選取特徵。
- 皮爾遜相關係數法(只衡量特徵和目標變數之間的線性關係)
- 卡方檢驗
Wrapper經典的卡方檢驗是檢驗定性自變數對定性因變數的相關性。假設自變數有N種取值,因變數有M種取值,考慮自變數等於i且因變數等於j的樣本頻數的觀察值與期望的差距,構建統計量:
這個統計量的含義簡而言之就是自變數對因變數的相關性。選擇卡方值排在前面的K個特徵作為最終的特徵選擇。
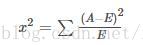
Embedded
- 遞迴特徵消除法
遞迴消除特徵法使用一個基模型來進行多輪訓練,每輪訓練後,消除若干權值係數的特徵,再基於新的特徵集進行下一輪訓練。
- 基於懲罰項的特徵選擇法
使用帶懲罰項的基模型,除了篩選出特徵外,同時也進行了降維。由於L1範數有篩選特徵的作用,因此,訓練的過程中,如果使用了L1範數作為懲罰項,可以起到特徵篩選的效果。
- 基於樹模型的特徵選擇法
訓練能夠對特徵打分的預選模型:GBDT、RandomForest和Logistic Regression等都能對模型的特徵打分,通過打分獲得相關性後再訓練最終模型。
不管是scikit-learn還是mllib,其中的隨機森林和gbdt演算法都是基於決策樹演算法,一般的,都是使用了cart樹演算法,通過gini指數來計算特徵的重要性的。
比如scikit-learn的sklearn.feature_selection.SelectFromModel可以實現根據特徵重要性分支進行特徵的轉換。在spark 2.0之後,mllib的決策樹演算法都引入了計算特徵重要性的方法featureImportances,而隨機森林演算法(RandomForestRegressionModel和RandomForestClassificationModel類)和gbdt演算法(GBTClassificationModel和GBTRegressionModel類)均利用決策樹演算法中計算特徵不純度和特徵重要性的方法來得到所使用模型的特徵重要性。