
傳統神經網路中常用的regularization方法
1、basic choice

(1)通過一定的方式來縮小權重
![]()
(2)通過一定的方式將部分權重置為0

(3)weight-elimination regulizer
![]()

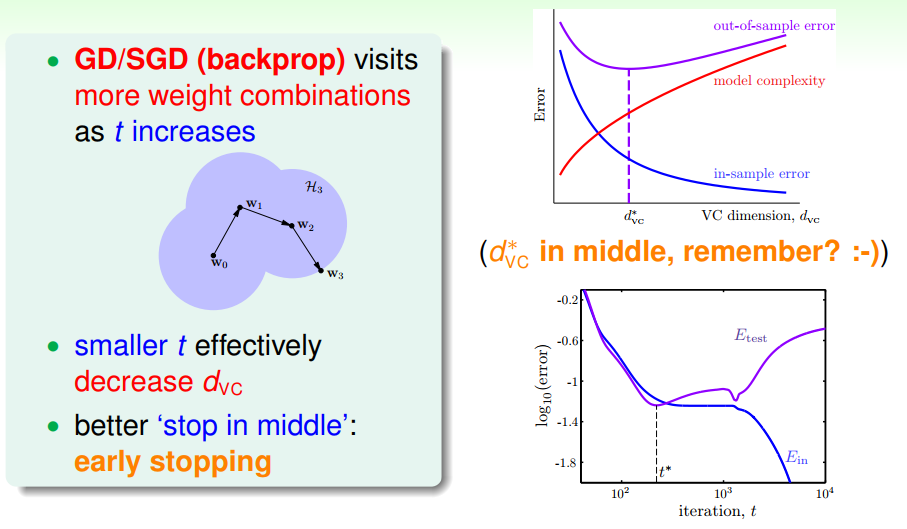
2、Early Stoppping
Early stopping方法可以控制VC dimension的大小,具體可結合validation方法來實現。
相關推薦
傳統神經網路中常用的regularization方法
1、basic choice (1)通過一定的方式來縮小權重 (2)通過一定的方式將部分權重置為0 (3)weight-elimination regulizer 2、Early Stoppping Early stopping方法可以控制VC dimension
Pytorch_第九篇_神經網路中常用的啟用函式
# 神經網路中常用的啟用函式 --- ## Introduce 理論上神經網路能夠擬合任意線性函式,其中主要的一個因素是使用了非線性啟用函式(**因為如果每一層都是線性變換,那有啥用啊,始終能夠擬合的都是線性函式啊**)。==本文主要介紹神經網路中各種常用的啟用函式。== ==以下均為個人學習筆記,若有錯
神經網路中的過擬合的原因及解決方法、泛化能力、L2正則化
過擬合:訓練好的神經網路對訓練資料以及驗證資料擬合的很好,accuracy很高,loss很低,但是在測試資料上效果很差,即出現了過擬合現象。 過擬合產生的原因: (1)資料集有噪聲 (2)訓練資料不足 (3)訓練模型過度導致模型非常複雜 解決方法: (1)降低模型
網路中常用的佇列管理方法比較
佇列管理屬於鏈路IP層的擁塞控制策略,主要是在路由器中採用排隊演算法和資料包丟棄策略。排隊演算法通過決定哪些包可以傳輸來分配頻寬,而丟棄策略通過決定哪些包被丟棄來分配快取。 1、先進先
【科普】神經網路中的隨機失活方法
## 1. Dropout 如果模型引數過多,而訓練樣本過少,容易陷入過擬合。過擬合的表現主要是:在訓練資料集上loss比較小,準確率比較高,但是在測試資料上loss比較大,準確率比較低。Dropout可以比較有效地緩解模型的過擬合問題,起到正則化的作用。 Dropout,中文是隨機失活,是一個簡單又機器
神經網路中的降維和升維方法 (tensorflow & pytorch)
大名鼎鼎的UNet和我們經常看到的編解碼器模型,他們的模型都是先將資料下采樣,也稱為特徵提取,然後再將下采樣後的特徵恢復回原來的維度。這個特徵提取的過程我們稱為“下采樣”,這個恢復的過程我們稱為“上取樣”,本文就專注於神經網路中的下采樣和上取樣來進行一次總結
String對象中常用的方法有哪些?
bsp rec val 字符串長度 方法 end 出現 小寫 轉變 1、length()字符串長度 String str="abc"; System.out.println(str.length()); //輸出3 2、charAt()截取一
String類中常用的方法(重要)
循環 類型 demo width 尋找 str2 子字符串 replace table 1.字符串與字節 public String(byte[] byte); 將全部字節變成字符串 public String (byte[] byte,int offset,in
測試工作中常用的方法
期望 action 管理 威脅 人員 rabl 定義 structure 基礎 測試工作中經常用到如下相關方法,主要包括PDCA、SWOT、6W2H、SMART、2/8法則、WBS任務分解法、時間管理。 PDCA循環法則 Plan:制定目標和計劃 Do:按照計
27 string類中常用的方法列表
nta val nds lsi con valueof 轉換 pan nbsp 1. 獲取方法 int length() 獲取字符串的長度 char charAt(int index) 獲取特定位置的字符 (角標越界) int
總結Array類型中常用的方法
包含 enc 對象 參考 http som 對數 fir 負數 Array類型應該是 ECMAScript 中最常用的類型之一了,並且它定義的數組與其他語言有著相當大的區別。數組是數據的有序集合,我們可以通過下標對指定位置的數據進行讀寫;特別的是,在 ECMAScrip
神經網路的引數優化方法
轉載自:https://www.cnblogs.com/bonelee/p/8528863.html 著名: 本文是從 Michael Nielsen的電子書Neural Network and Deep Learning的深度學習那一章的卷積神經網路的引數優化方法的
神經網路中隱層數和隱層節點數問題的討論
神經網路中隱層數和隱層節點數問題的討論 一 隱層數 一般認為,增加隱層數可以降低網路誤差(也有文獻認為不一定能有效降低),提高精度,但也使網路複雜化,從而增加了網路的訓練時間和出現“過擬合”的傾向。一般來講應設
正則表示式中常用字串方法
1,search()用於檢索字串中指定的子字串,或檢索與正則表示式相匹配的子字串,並返回子串的起始位置。search()方法不支援全域性搜尋,因為會忽略正則表示式引數的標識g,並且也忽略了regexp的lastIndex屬性,總是從字串的開始位置進行檢索,所以它會總是返回str的第一個匹配的位置。 &n
變形卷積核、可分離卷積?卷積神經網路中十大拍案叫絕的操作
大家還是去看原文好,作者的文章都不錯: https://zhuanlan.zhihu.com/p/28749411 https://www.zhihu.com/people/professor-ho/posts 一、卷積只能在同一組進行嗎?-- Group convo
2013-2018卷積神經網路中十個最重要的概念與創新
本文作者Professor ho,原文載於其知乎主頁 一、卷積只能在同一組進行嗎?– Group convolution Group convolution 分組卷積,最早在AlexNet中出現,由於當時的硬體資源有限,訓練AlexNet時卷積操作不能全部放在同一個GPU處理,因此作
JQ中常用的方法
1, $().addClass(css中定義的樣式型別) -> 給某個元素新增樣式 $().attr({src:‘test.jpg’,alt:‘test image’}) -> 給某個元素新增屬性/值,引數是map $().attr(‘src’,‘test.jpg’) ->
神經網路中訓練資料集、驗證資料集和測試資料集的區別
whats the difference between train, validation and test set, in neural networks? Answer: The training and validation sets are used during t
html及js中常用的方法(個人總結)
js內建物件 isNaN: 判斷一個元素是不是一個數字(not a number),也就是如果是一個數字返 回None,如果不是一個數字返回True. data物件的方法 getTime 1970-1-1至今的stamp(時間戳) getDate() 獲取時間中的天 getDay
神經網路中的非線性啟用函式
目錄 0. 前言 1. ReLU 整流線性單元 2. 絕對值整流線性單元 3. 滲漏整流線性單元 4. 引數化整流線性單元 5. maxout 單元 6. logistic sigmoid 單元