
05 MapReduce應用案例03
阿新 • • 發佈:2019-02-10
8、PageRank
Page-rank源於Google,用於衡量特定網頁相對於搜尋引擎索引中的其他網頁而言的重要程度。
Page-rank實現了將連結價值概念作為排名因素。
演算法原理
– 入鏈 == 投票
• Page-rank 讓連結來“ 投票 “ ,到一個頁面的超連結相當於對該頁投一票。
– 入鏈數量
• 如果一個頁面節點接收到的其他網頁指向的入鏈數量越多,那麼這個頁面越重要。
– 入鏈質量
• 指向頁面A的入鏈質量不同,質量高的頁面會通過連結向其他頁面傳遞更多的權重。所以越是質量高的頁面指向頁面A ,則頁面
A 越重要。
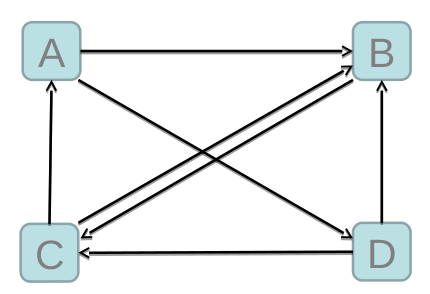
– 初始值
• 每個頁面設定相同的PR值
• Google的page-rank演算法給每個頁面的PR初始值為1。
– 迭代遞迴計算(收斂)
• Google不斷的重複計算每個頁面的Page-rank。那麼經過不斷的重複計算,這些頁面的PR值會趨向於穩定,也就是收斂的狀態。
• 在具體企業應用中怎麼樣確定收斂標準?
– 1、每個頁面的PR值和上一次計算的PR相等
– 2、設定一個差值指標(0.0001 )。當所有頁面和上一次計算的PR差值平均小於該標準時,則收斂。
– 3、設定一個百分比(99% ),當99%的頁面和上一次計算的PR相等
– 修正Page-rank計算公式
• 由於存在一些出鏈為0,也就是那些不連結任何其他網頁的網,也稱為孤立網頁,使得很多網頁不能被訪問到。因此需要對Page-rank公式進行修正,即在簡單公式的基礎上增加了阻尼係數(damping factor ) q , q 一般取值q=0.85。
– 完整Page-rank計算公式

import java.io.IOException; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.input.KeyValueTextInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class PageRankRun { public static enum MyCounter{ counter } public static class PRMapper extends Mapper<Text, Text, Text, Text>{ //webname:weight linkout1 linkout2 linkoutn //webname weight:linkout1 linkout2 linkoutn //linkout1 weight //linkout2 weight //linkoutn weight @Override protected void map(Text key, Text value, Context context) throws IOException, InterruptedException { String[] links = value.toString().split(" "); int num = links.length; String[] pageRank = key.toString().split(":"); context.write(new Text(pageRank[0]), new Text(pageRank[1] + ":" + value.toString())); double weight = Double.parseDouble(pageRank[1].trim()); for(String s : links) context.write(new Text(s), new Text(weight/num + "")); } } public static class PRReducer extends Reducer<Text, Text, Text, Text>{ @Override protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException { String links = ""; double oldPR = 0; int totalWebNum = context.getConfiguration().getInt("totalWebNum", 1); double newPR = (1-0.85)/totalWebNum; for(Text t : values){ String[] s = t.toString().trim().split(":"); if (s.length > 1){ links = s[1].trim(); oldPR = Double.parseDouble(s[0]); }else{ newPR += Double.parseDouble(s[0])*0.85; } } int i = (int)Math.abs((oldPR - newPR)*10000); context.getCounter(MyCounter.counter).increment(i); context.write(new Text(key.toString() + ":" + newPR), new Text(links)); } } public static void main(String[] args) throws Exception{ Configuration conf = new Configuration(); conf.setInt("totalWebNum", 4); boolean flag = true; double limit = 0.0001; while(true){ Job job = Job.getInstance(conf); job.setJarByClass(PageRankRun.class); job.setInputFormatClass(KeyValueTextInputFormat.class); job.setMapperClass(PRMapper.class); job.setReducerClass(PRReducer.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(Text.class); Path in; Path out; if (flag){ in = new Path("/home/jinzhao/mrtest/input"); out = new Path("/home/jinzhao/mrtest/output"); flag = false; }else{ out = new Path("/home/jinzhao/mrtest/input"); in = new Path("/home/jinzhao/mrtest/output"); flag = true; } FileInputFormat.setInputPaths(job, in); FileSystem fs = FileSystem.get(conf); if (fs.exists(out)) fs.delete(out, true); FileOutputFormat.setOutputPath(job, out); if (job.waitForCompletion(true)){ long sum= job.getCounters().findCounter(MyCounter.counter).getValue(); double avgd= sum*1.0/(conf.getInt("totalWebNum", 1)*10000); if(avgd < limit){ fs.delete(in, true); break; } } } } }