
基於Python3.6編寫的jieba分片語件+Scikit-Learn庫+樸素貝葉斯演算法小型中文自動分類程式
實驗主題:大規模數字化(中文)資訊資源資訊組織所包含的基本流程以及各個環節執行的任務。
本文所採用的分類及程式框架主要參考了這篇部落格基本流程:
如下圖所示,和資訊資源資訊組織的基本流程類似,大規模數字化(中文)資訊資源組織的基本流程也如下:1資訊資源的預處理、2資訊外部特徵描述、3資訊內部特徵標引、4資訊資源的分類、5得到序化的資訊資源
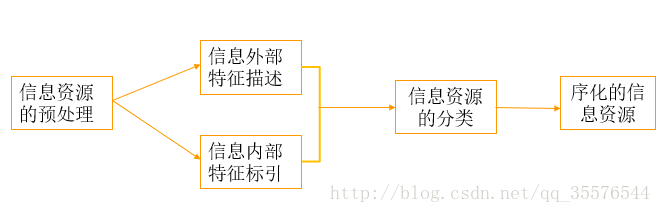
圖1
1.1在資訊資源預處理環節,首先要選擇處理文字的範圍,建立分類文字語料庫:訓練集語料(已經分好類的文字資源)和測試集語料(待分類的文字語料)。其次要轉化文字格式,使用Python的lxml庫去除html標籤。最後監測句子邊界,標記句子的結束。
1.2在資訊外部特徵描述環節,大規模數字化資訊資源資訊組織關注的不多,主要是對資訊資源的內容、外部表現形式和物質形態(媒體型別、格式)的特徵進行分析、描述、選擇和記錄的過程。資訊外部特徵序化的最終結果就是書目。
1.3在資訊內部特徵標引環節,指在分析資訊內容基礎上,用某種語言和識別符號把資訊的主題概念及其具有檢索意義的特徵標示出來,作為資訊分析與檢索的基礎。而資訊內部特徵序化的結果就是代表主體概念的標引詞集合。數字化資訊組織更注重通過細粒度資訊內容特徵的語義邏輯和統計概率關係。技術上對應文字自動分類中建立向量空間模型和TF/IDF權重矩陣環節,也就是資訊資源的自動標引。
1.4在資訊資源分類環節,注重基於語料庫的統計分類體系,在資料探勘領域稱作文件自動分類,主要任務是從文件資料集中提取描述文件的模型,並把資料集中的每個文件歸入到某個已知的文件類中。常用的有樸素貝葉斯分類器和KNN分類器,在深度學習裡還有卷積神經網路分類法。
1.5最後便得到了序化好的資訊資源,接下來根據目的的不同有兩種組織方法,一是基於資源(知識)導航、另一種是搜尋引擎。大規模數字化(中文)資訊資源資訊組織主要是一種基於搜尋引擎的資訊組織,序化好的資訊資源為數字圖書館搜尋引擎建立倒排索引打下基礎。

圖22程式檔案的目錄層次結構
功能說明:
(1) html_demo.py程式對文字進行預處理,即用lxml去除html標籤。
(2) corpus_segment.py程式利用jieba分詞庫對訓練集和測試集分詞。
(3) corpus2Bunch.py程式利用的是Scikit-Learn庫中的Bunch資料結構將訓練集和測試集語料庫表示為變數,分別儲存在train_word_bag
(4) TFIDF_space.py程式用於構建TF-IDF詞向量空間,將訓練集資料轉換為TF-IDF詞向量空間中的例項(去掉停用詞),儲存在train_word_bag/tfdifspace.dat,形成權重矩陣; 同時採用同樣的訓練步驟載入訓練集詞袋,將測試集產生的詞向量對映到訓練集詞袋的詞典中,生成向量空間模型檔案test_word_bag/testspace.dat。
(5) NBayes_Predict.py程式採用多項式貝葉斯演算法進行預測文字分類。
1.分詞程式程式碼#!/usr/bin/env python
# -*- coding: UTF-8 -*-
import sys
import os
from importlib import reload
import jieba
# 配置utf-8輸出環境
reload(sys)
# 儲存至檔案
def savefile(savepath, content):
with open(savepath, "w", encoding='utf-8', errors='ignore') as fp:
fp.write(content)
# 讀取檔案
def readfile(path):
with open(path, "r") as fp:
content = fp.read()
return content
def corpus_segment(corpus_path, seg_path):
# 獲取每個目錄(類別)下所有的檔案
for mydir in catelist:
class_path = corpus_path + mydir + "/" # 拼出分類子目錄的路徑如:train_corpus/art/
seg_dir = seg_path + mydir + "/" # 拼出分詞後存貯的對應目錄路徑如:train_corpus_seg/art/
if not os.path.exists(seg_dir): # 是否存在分詞目錄,如果沒有則建立該目錄
os.makedirs(seg_dir)
file_list = os.listdir(class_path) # 獲取未分詞語料庫中某一類別中的所有文字
for file_path in file_list: # 遍歷類別目錄下的所有檔案
fullname = class_path + file_path # 拼出檔名全路徑如:train_corpus/art/21.txt
content = readfile(fullname) # 讀取檔案內容
content = content.replace("\r\n", "") # 刪除換行
content = content.replace(" ", "")#刪除空行、多餘的空格
content_seg = jieba.cut(content) # 為檔案內容分詞
savefile(seg_dir + file_path, " ".join(content_seg)) # 將處理後的檔案儲存到分詞後語料目錄
print ("中文語料分詞結束!!!")
if __name__=="__main__":
#對訓練集進行分詞
corpus_path = "C:/Users/JAdpp/Desktop/資料集/trainingdataset/" # 未分詞分類語料庫路徑
seg_path = "C:/Users/JAdpp/Desktop/資料集/outdataset1/" # 分詞後分類語料庫路徑
corpus_segment(corpus_path, seg_path)2.用Bunch資料結構將訓練集和測試集轉化為變數的程式程式碼
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
import sys
from importlib import reload
reload(sys)
import os#python內建的包,用於進行檔案目錄操作,我們將會用到os.listdir函式
import pickle#匯入 pickle包
from sklearn.datasets.base import Bunch
def _readfile(path):
with open(path, "rb") as fp:
content = fp.read()
return content
def corpus2Bunch(wordbag_path,seg_path):
catelist = os.listdir(seg_path)# 獲取seg_path下的所有子目錄,也就是分類資訊
#建立一個Bunch例項
bunch = Bunch(target_name=[], label=[], filenames=[], contents=[])
bunch.target_name.extend(catelist)
# 獲取每個目錄下所有的檔案
for mydir in catelist:
class_path = seg_path + mydir + "/" # 拼出分類子目錄的路徑
file_list = os.listdir(class_path) # 獲取class_path下的所有檔案
for file_path in file_list: # 遍歷類別目錄下檔案
fullname = class_path + file_path # 拼出檔名全路徑
bunch.label.append(mydir)
bunch.filenames.append(fullname)
bunch.contents.append(_readfile(fullname)) # 讀取檔案內容
# 將bunch儲存到wordbag_path路徑中
with open(wordbag_path, "wb") as file_obj:
pickle.dump(bunch, file_obj)
print("構建文字物件結束!!!")
if __name__ == "__main__":
#對訓練集進行Bunch化操作:
wordbag_path = "train_word_bag/train_set.dat" # Bunch儲存路徑
seg_path = "C:/Users/JAdpp/Desktop/資料集/outdataset1/" # 分詞後分類語料庫路徑
corpus2Bunch(wordbag_path, seg_path)
# 對測試集進行Bunch化操作:
wordbag_path = "test_word_bag/test_set.dat" # Bunch儲存路徑
seg_path = "C:/Users/JAdpp/Desktop/資料集/experimentdataset/" # 分詞後分類語料庫路徑
corpus2Bunch(wordbag_path, seg_path)3.建TF-IDF詞向量空間,將訓練集和測試集資料轉換為TF-IDF詞向量空間中的例項(去掉停用詞)程式程式碼
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
import codecs
import sys
from importlib import reload
reload(sys)
from sklearn.datasets.base import Bunch
import pickle
from sklearn.feature_extraction.text import TfidfVectorizer
def _readfile(path):
with open(path, "rb") as fp:
content = fp.read()
return content
def _readbunchobj(path):
with open(path, "rb") as file_obj:
bunch = pickle.load(file_obj)
return bunch
def _writebunchobj(path, bunchobj):
with open(path, "wb") as file_obj:
pickle.dump(bunchobj, file_obj)
def vector_space(stopword_path,bunch_path,space_path,train_tfidf_path=None):
stpwrdlst = _readfile(stopword_path).splitlines()
bunch = _readbunchobj(bunch_path)
tfidfspace = Bunch(target_name=bunch.target_name, label=bunch.label, filenames=bunch.filenames, tdm=[], vocabulary={})
if train_tfidf_path is not None:
trainbunch = _readbunchobj(train_tfidf_path)
tfidfspace.vocabulary = trainbunch.vocabulary
vectorizer = TfidfVectorizer(stop_words=stpwrdlst, sublinear_tf=True, max_df=0.5,vocabulary=trainbunch.vocabulary)
tfidfspace.tdm = vectorizer.fit_transform(bunch.contents)
else:
vectorizer = TfidfVectorizer(stop_words=stpwrdlst, sublinear_tf=True, max_df=0.5)
tfidfspace.tdm = vectorizer.fit_transform(bunch.contents)
tfidfspace.vocabulary = vectorizer.vocabulary_
_writebunchobj(space_path, tfidfspace)
print("if-idf詞向量空間例項建立成功!!!")
if __name__ == '__main__':
stopword_path = "train_word_bag/hlt_stop_words.txt"
bunch_path = "train_word_bag/train_set.dat"
space_path = "train_word_bag/tfdifspace.dat"
vector_space(stopword_path,bunch_path,space_path)
bunch_path = "test_word_bag/test_set.dat"
space_path = "test_word_bag/testspace.dat"
train_tfidf_path="train_word_bag/tfdifspace.dat"
vector_space(stopword_path,bunch_path,space_path,train_tfidf_path)4.用多項式貝葉斯演算法預測測試集文字分類情況
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
import sys
from importlib import reload
reload(sys)
import pickle
from sklearn.naive_bayes import MultinomialNB # 匯入多項式貝葉斯演算法
# 讀取bunch物件
def _readbunchobj(path):
with open(path, "rb") as file_obj:
bunch = pickle.load(file_obj)
return bunch
# 匯入訓練集
trainpath = "train_word_bag/tfdifspace.dat"
train_set = _readbunchobj(trainpath)
# 匯入測試集
testpath = "test_word_bag/testspace.dat"
test_set = _readbunchobj(testpath)
# 訓練分類器:輸入詞袋向量和分類標籤,alpha:0.001 alpha越小,迭代次數越多,精度越高
clf = MultinomialNB(alpha=0.001).fit(train_set.tdm, train_set.label)
# 預測分類結果
predicted = clf.predict(test_set.tdm)
for flabel,file_name,expct_cate in zip(test_set.label,test_set.filenames,predicted):
if flabel != expct_cate:
print(file_name,": 實際類別:",flabel," -->預測類別:",expct_cate)
print("預測完畢!!!")
# 計算分類精度:
from sklearn import metrics
def metrics_result(actual, predict):
print('精度:{0:.3f}'.format(metrics.precision_score(actual, predict,average='weighted')))
print('召回:{0:0.3f}'.format(metrics.recall_score(actual, predict,average='weighted')))
print('f1-score:{0:.3f}'.format(metrics.f1_score(actual, predict,average='weighted')))
metrics_result(test_set.label, predicted)5.分類結果
C:/Users/JAdpp/Desktop/資料集/experimentdataset/experimentdataset/file01.txt : 實際類別: experimentdataset -->預測類別: class5
C:/Users/JAdpp/Desktop/資料集/experimentdataset/experimentdataset/file02.txt : 實際類別: experimentdataset -->預測類別: class7
C:/Users/JAdpp/Desktop/資料集/experimentdataset/experimentdataset/file03.txt : 實際類別: experimentdataset -->預測類別: class1
C:/Users/JAdpp/Desktop/資料集/experimentdataset/experimentdataset/file04.txt : 實際類別: experimentdataset -->預測類別: class7
C:/Users/JAdpp/Desktop/資料集/experimentdataset/experimentdataset/file05.txt : 實際類別: experimentdataset -->預測類別: class4
C:/Users/JAdpp/Desktop/資料集/experimentdataset/experimentdataset/file06.txt : 實際類別: experimentdataset -->預測類別: class3
C:/Users/JAdpp/Desktop/資料集/experimentdataset/experimentdataset/file07.txt : 實際類別: experimentdataset -->預測類別: class2
C:/Users/JAdpp/Desktop/資料集/experimentdataset/experimentdataset/file08.txt : 實際類別: experimentdataset -->預測類別: class6
C:/Users/JAdpp/Desktop/資料集/experimentdataset/experimentdataset/file09.txt : 實際類別: experimentdataset -->預測類別: class8
C:/Users/JAdpp/Desktop/資料集/experimentdataset/experimentdataset/file10.txt : 實際類別: experimentdataset -->預測類別: class4
C:/Users/JAdpp/Desktop/資料集/experimentdataset/experimentdataset/file11.txt : 實際類別: experimentdataset -->預測類別: class6
C:/Users/JAdpp/Desktop/資料集/experimentdataset/experimentdataset/file12.txt : 實際類別: experimentdataset -->預測類別: class4
C:/Users/JAdpp/Desktop/資料集/experimentdataset/experimentdataset/file13.txt : 實際類別: experimentdataset -->預測類別: class1
C:/Users/JAdpp/Desktop/資料集/experimentdataset/experimentdataset/file14.txt : 實際類別: experimentdataset -->預測類別: class2
C:/Users/JAdpp/Desktop/資料集/experimentdataset/experimentdataset/file15.txt : 實際類別: experimentdataset -->預測類別: class5
C:/Users/JAdpp/Desktop/資料集/experimentdataset/experimentdataset/file16.txt : 實際類別: experimentdataset -->預測類別: class4
C:/Users/JAdpp/Desktop/資料集/experimentdataset/experimentdataset/file17.txt : 實際類別: experimentdataset -->預測類別: class1
C:/Users/JAdpp/Desktop/資料集/experimentdataset/experimentdataset/file18.txt : 實際類別: experimentdataset -->預測類別: class2
C:/Users/JAdpp/Desktop/資料集/experimentdataset/experimentdataset/file19.txt : 實際類別: experimentdataset -->預測類別: class8
C:/Users/JAdpp/Desktop/資料集/experimentdataset/experimentdataset/file20.txt : 實際類別: experimentdataset -->預測類別: class7
C:/Users/JAdpp/Desktop/資料集/experimentdataset/experimentdataset/file21.txt : 實際類別: experimentdataset -->預測類別: class2
C:/Users/JAdpp/Desktop/資料集/experimentdataset/experimentdataset/file22.txt : 實際類別: experimentdataset -->預測類別: class3
C:/Users/JAdpp/Desktop/資料集/experimentdataset/experimentdataset/file23.txt : 實際類別: experimentdataset -->預測類別: class7
C:/Users/JAdpp/Desktop/資料集/experimentdataset/experimentdataset/file24.txt : 實際類別: experimentdataset -->預測類別: class2
C:/Users/JAdpp/Desktop/資料集/experimentdataset/experimentdataset/file25.txt : 實際類別: experimentdataset -->預測類別: class6
C:/Users/JAdpp/Desktop/資料集/experimentdataset/experimentdataset/file26.txt : 實際類別: experimentdataset -->預測類別: class3
C:/Users/JAdpp/Desktop/資料集/experimentdataset/experimentdataset/file27.txt : 實際類別: experimentdataset -->預測類別: class8
C:/Users/JAdpp/Desktop/資料集/experimentdataset/experimentdataset/file28.txt : 實際類別: experimentdataset -->預測類別: class5
C:/Users/JAdpp/Desktop/資料集/experimentdataset/experimentdataset/file29.txt : 實際類別: experimentdataset -->預測類別: class1
C:/Users/JAdpp/Desktop/資料集/experimentdataset/experimentdataset/file30.txt : 實際類別: experimentdataset -->預測類別: class8
C:/Users/JAdpp/Desktop/資料集/experimentdataset/experimentdataset/file31.txt : 實際類別: experimentdataset -->預測類別: class8
C:/Users/JAdpp/Desktop/資料集/experimentdataset/experimentdataset/file32.txt : 實際類別: experimentdataset -->預測類別: class6
C:/Users/JAdpp/Desktop/資料集/experimentdataset/experimentdataset/file33.txt : 實際類別: experimentdataset -->預測類別: class4
C:/Users/JAdpp/Desktop/資料集/experimentdataset/experimentdataset/file34.txt : 實際類別: experimentdataset -->預測類別: class1
C:/Users/JAdpp/Desktop/資料集/experimentdataset/experimentdataset/file35.txt : 實際類別: experimentdataset -->預測類別: class2
C:/Users/JAdpp/Desktop/資料集/experimentdataset/experimentdataset/file36.txt : 實際類別: experimentdataset -->預測類別: class7
C:/Users/JAdpp/Desktop/資料集/experimentdataset/experimentdataset/file37.txt : 實際類別: experimentdataset -->預測類別: class8
C:/Users/JAdpp/Desktop/資料集/experimentdataset/experimentdataset/file38.txt : 實際類別: experimentdataset -->預測類別: class7
C:/Users/JAdpp/Desktop/資料集/experimentdataset/experimentdataset/file39.txt : 實際類別: experimentdataset -->預測類別: class4
C:/Users/JAdpp/Desktop/資料集/experimentdataset/experimentdataset/file40.txt : 實際類別: experimentdataset -->預測類別: class3
C:/Users/JAdpp/Desktop/資料集/experimentdataset/experimentdataset/file41.txt : 實際類別: experimentdataset -->預測類別: class2
C:/Users/JAdpp/Desktop/資料集/experimentdataset/experimentdataset/file42.txt : 實際類別: experimentdataset -->預測類別: class6
C:/Users/JAdpp/Desktop/資料集/experimentdataset/experimentdataset/file43.txt : 實際類別: experimentdataset -->預測類別: class3
C:/Users/JAdpp/Desktop/資料集/experimentdataset/experimentdataset/file44.txt : 實際類別: experimentdataset -->預測類別: class6
C:/Users/JAdpp/Desktop/資料集/experimentdataset/experimentdataset/file45.txt : 實際類別: experimentdataset -->預測類別: class2
C:/Users/JAdpp/Desktop/資料集/experimentdataset/experimentdataset/file46.txt : 實際類別: experimentdataset -->預測類別: class8
C:/Users/JAdpp/Desktop/資料集/experimentdataset/experimentdataset/file47.txt : 實際類別: experimentdataset -->預測類別: class3
C:/Users/JAdpp/Desktop/資料集/experimentdataset/experimentdataset/file48.txt : 實際類別: experimentdataset -->預測類別: class8
C:/Users/JAdpp/Desktop/資料集/experimentdataset/experimentdataset/file49.txt : 實際類別: experimentdataset -->預測類別: class5
C:/Users/JAdpp/Desktop/資料集/experimentdataset/experimentdataset/file50.txt : 實際類別: experimentdataset -->預測類別: class3
C:/Users/JAdpp/Desktop/資料集/experimentdataset/experimentdataset/file51.txt : 實際類別: experimentdataset -->預測類別: class6
C:/Users/JAdpp/Desktop/資料集/experimentdataset/experimentdataset/file52.txt : 實際類別: experimentdataset -->預測類別: class4
C:/Users/JAdpp/Desktop/資料集/experimentdataset/experimentdataset/file53.txt : 實際類別: experimentdataset -->預測類別: class2
C:/Users/JAdpp/Desktop/資料集/experimentdataset/experimentdataset/file54.txt : 實際類別: experimentdataset -->預測類別: class1
C:/Users/JAdpp/Desktop/資料集/experimentdataset/experimentdataset/file55.txt : 實際類別: experimentdataset -->預測類別: class7
C:/Users/JAdpp/Desktop/資料集/experimentdataset/experimentdataset/file56.txt : 實際類別: experimentdataset -->預測類別: class5
C:/Users/JAdpp/Desktop/資料集/experimentdataset/experimentdataset/file57.txt : 實際類別: experimentdataset -->預測類別: class8
C:/Users/JAdpp/Desktop/資料集/experimentdataset/experimentdataset/file58.txt : 實際類別: experimentdataset -->預測類別: class1
C:/Users/JAdpp/Desktop/資料集/experimentdataset/experimentdataset/file59.txt : 實際類別: experimentdataset -->預測類別: class6
C:/Users/JAdpp/Desktop/資料集/experimentdataset/experimentdataset/file60.txt : 實際類別: experimentdataset -->預測類別: class4
C:/Users/JAdpp/Desktop/資料集/experimentdataset/experimentdataset/file61.txt : 實際類別: experimentdataset -->預測類別: class2
C:/Users/JAdpp/Desktop/資料集/experimentdataset/experimentdataset/file62.txt : 實際類別: experimentdataset -->預測類別: class6
C:/Users/JAdpp/Desktop/資料集/experimentdataset/experimentdataset/file63.txt : 實際類別: experimentdataset -->預測類別: class3
C:/Users/JAdpp/Desktop/資料集/experimentdataset/experimentdataset/file64.txt : 實際類別: experimentdataset -->預測類別: class5
C:/Users/JAdpp/Desktop/資料集/experimentdataset/experimentdataset/file65.txt : 實際類別: experimentdataset -->預測類別: class4
C:/Users/JAdpp/Desktop/資料集/experimentdataset/experimentdataset/file66.txt : 實際類別: experimentdataset -->預測類別: class5
C:/Users/JAdpp/Desktop/資料集/experimentdataset/experimentdataset/file67.txt : 實際類別: experimentdataset -->預測類別: class4
C:/Users/JAdpp/Desktop/資料集/experimentdataset/experimentdataset/file68.txt : 實際類別: experimentdataset -->預測類別: class1
C:/Users/JAdpp/Desktop/資料集/experimentdataset/experimentdataset/file69.txt : 實際類別: experimentdataset -->預測類別: class6
C:/Users/JAdpp/Desktop/資料集/experimentdataset/experimentdataset/file70.txt : 實際類別: experimentdataset -->預測類別: class7
預測完畢!!!總結:
遇到的問題主要有Python2.7和Python3的語法問題,舉例來說,參考程式碼由於是Python2.7編寫的,所以在設定utf-8 unicode環境時需要寫“sys.setdefaultencoding('utf-8')”程式碼,而在Python3字串預設編碼unicode,所以sys.setdefaultencoding也不存在了,需要刪除這行。還有print在Python3以後由語句變成了函式,所以需要加上括號。分詞環節參考了jieba元件作者在github上的官方教程和說明文件,Scikit-Learn庫則參考了官方的技術文件。程式執行成功,但遺留一個小bug,在於由於資料集結構問題,訓練集和測試集分類數不同,所以不能評估分類評估結果,召回率、準確率和F-Score。
下一篇會出構建搜尋引擎的實現原理。