
Kafka訊息佇列原理總結
最近在測試kafka的讀寫效能,所以借這個機會了解了kafka的一些設計原理,既然作為分散式系統,我們還是按照分散式的套路進行分析。
Kafka的邏輯資料模型:
生產者傳送資料給服務端時,構造的是ProducerRecord<Integer, String>(String topic, Integer key,String value)物件併發送,從這個建構函式可以看到,kafka的表面邏輯資料模型是key-value。當然api再發送前還會在這個基礎上加入若干校驗資訊,不過這個對使用者而言是透明的。
Kafka的分發策略:
跟很多分散式多備份系統類似,kafka的基本網路結構如下:
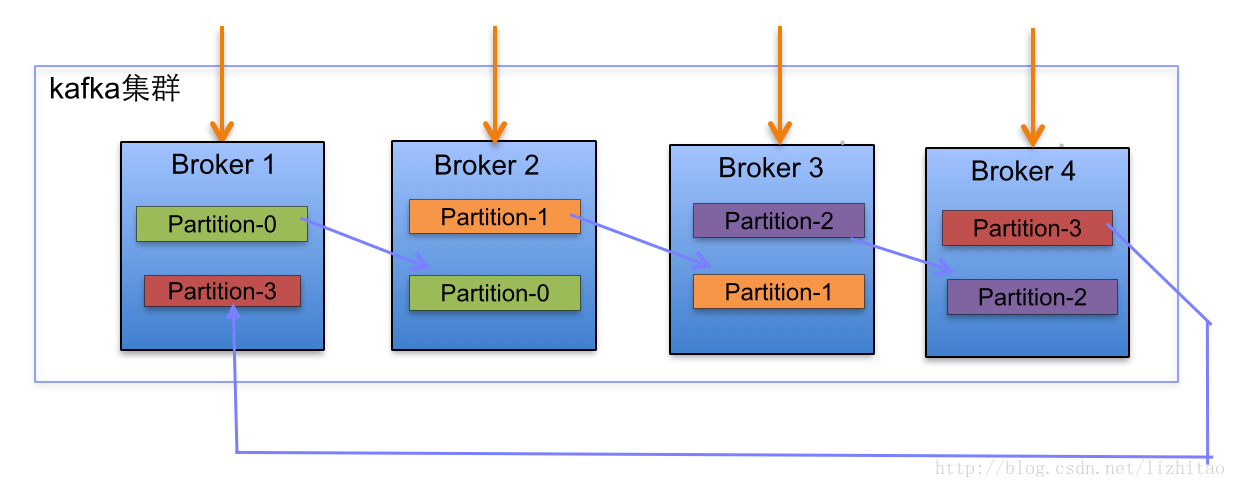
一個節點(Broker)中存有不同partition的備份,一個parittion存在多份備份儲存在不同節點上並且選舉出一個作為leader跟客戶端互動,一個topic擁有多個parittion。
預設的kafka分發演算法是hash(key)%numPartitions,簡單來就是雜湊再取模。當然這個演算法可以自定義,只要重寫相關介面。如上圖在一個四臺主機上建立了一個有兩個備份,四個分割槽partion的話題topic,但生產者需要傳送某個key-value物件到訊息佇列裡面時,建立連線時通過訪問zookeeper,獲取到一份leader partion列表(Broker1. Partition-0, Broker2. Partition1, Broker3. Partition-2, Broker4.Partition-3),再根據分發演算法計算出這個物件應該要傳送到哪個leader partion中。
Kafka的物理儲存模型和查詢資料的設計:
Kafka的物理儲存模型比較簡單,在kafka的物理持久化的儲存中有分Segment的概念,每個Segment有兩種型別的檔案:索引檔案***.index和日誌檔案(資料檔案)***.log。兩者的命名規則都是以這個Segment的第一條的訊息邏輯偏移量作為檔名。索引是稀疏索引,目的在於減少索引檔案的資料量,其檔案的內容是key-value結構,key是訊息的偏移量offeset(就是一個自增的序列號),value是對應的log檔案的實際物理磁碟偏移量。
值得一提的是,跟其他正常分散式不一樣,kafka並不支援根據給定的key查詢該key對應的value值的能力,某種意義而言,邏輯資料模型中的key只是用來實現分發計算用的,所以使用kafka查詢資料只能以指定訊息的偏移量的放鬆實現。
整個查詢過程:當要查詢offset=888及後續的訊息時,kafka先到該節點上找到對應的Segment。通過該Segment的index檔案上用二分查詢的方法找到最接近offset=888的紀錄,比如886,然後找到886對應的物理磁碟偏移量999,這樣就從log的磁碟偏移量找起,連續遍歷了兩個訊息後就能找到888這個訊息的資料(log檔案中保留了每條訊息的邏輯偏移量,長度和資料)。
Kafka的持久化策略設計:
Kafka的持久化設計是非常有特色的,和其他分散式系統不同,它沒有自己維護一套快取機制,而是直接使用了作業系統的檔案系統(作業系統的檔案系統自帶pagecache)。這樣的好處是減少了一次記憶體拷貝的消耗。其他分散式系統比如cassandra,自己在服務端維護了一份資料緩衝記憶體塊datacache,當需要持久化時再呼叫作業系統的檔案系統寫入到檔案中,這樣就多了一次datacache到pagecache的拷貝消耗。這樣的話,kafka的持久化管理關鍵是管理檔案系統的pagecache的刷盤。
由於kafka採用了這種特別的持久化策略,所以在kafka中並沒有其他分散式系統的重做日誌。所以kafka在出現故障後的資料恢復策略有自己的一套:首先,kafka會通過配置檔案配置pagecache定時或者定量刷盤的頻率以保證即使出現故障也能把丟失的資料降低到最少。其次,pageche本身是作業系統管理維護的,跟kafka自身的服務程序沒有關係,如果是kafka本身掛了的話,重啟後還是能訪問到pageche中的資料的。最後如果很不幸是kafka所在的一個節點的主機掛掉的話,那麼重啟主機和kafka後也可以從其他備份節點重新同步丟失的資料。
Kafka高效能的和持久化策略關係非常密切,這部分內容,也是整個kafka設計的精髓所在:
傳統的觀念認為磁碟的讀寫是非常低效的,所以一般系統都會自己管理一塊記憶體datacache充當磁碟的快取,只有需要的時候才去和磁碟互動。但是實際上,磁碟的低效的原因不在於磁碟io,而在於磁頭的隨機定址。如果資料是順序讀寫的話(也就是一次磁頭定址,連續io),其實速度是非常快的((Raid-5,7200rpm):順序 I/O: 600MB/s)。而在傳統的設計中雖然加入了記憶體作為快取,但是為了保證資料的安全性還是得提供一份重做日誌(每次的修改操作都要記錄在重做日誌redo.log中,以保證記憶體丟失後能根據重做日誌進行恢復),並且當datacache裡面的資料達到一定容量時重新整理到磁碟的data檔案中。但是kafka並沒有使用這套常規設計,並沒有自己維護一套datacache而是另闢蹊徑,直接使用作業系統中的檔案系統,並利用檔案系統原有的pagecache作為資料快取。減少了datacache到pagecache的拷貝消耗。並且順序地進行磁碟io,這樣大大提高了kafka寫資料時持久化的效率。對於kafka的讀資料這塊,kafka也使用了Sendfile技術來提高讀的效率,傳統的讀方案是讀取磁碟的資料到pagecache中,然後從pagecache拷貝一份到使用者程序的datacache中,datacache再拷貝到核心的socket快取區中,最後從socket快取區拷貝資料到網絡卡中傳送。而Sendfile技術跳過了使用者程序的datacache這一環節,直接讀取磁碟的資料到pagecache中,然後從pagecache拷貝一份到socket快取區中,最後從socket快取區拷貝資料到網絡卡中傳送。整個過程減少了兩次拷貝消耗。
Kafka的節點間的資料一致性策略設計:
對於任何多節點多備份的分散式系統而言,資料的一致性問題都是繞不開的難點,一般的選擇是要麼優先考慮效率,這樣可能就造成資料不一致甚至是資料丟失,要麼選擇保障資料一致性和資料安全性犧牲效率。在kafka的身上也存在這樣的矛盾。
Kafka是一種分partion,多節點多備份的分散式系統,每個partion都可以存在多份備份,每個備份在不同的節點上。多個備份中會根據zookpeer的註冊資訊通過演算法選舉出其中一份作為leader,這個leader負責和客戶端的讀寫訪問進行互動。其他備份不參與跟客戶端的互動。而是去跟leader partion互動同步資料。這樣一來就可能出現主備之間資料不一致的情況。Kafka在客戶端提供了一個配置選項props.put("acks", "all");--其中all表示生產者等待確認所有的備份資料都寫入pagecache後再返回。可以設定為0(不等待任何確認),1(leader確認)或者其他小於備份數的數字。其他備份節點會非同步去同步leader partion的資料,保持一致,當然如果在同步的過程中,leader partion出現數據丟失,那麼這部分資料將永遠丟失。
Kafka的備份和負載均衡:
Kafka的備份很明顯,上文已經說過是通過討論一致性問題已經交待清楚,至於Kafka的負載均衡,個人發現是嚴重依賴於zookeeper上的註冊資訊,通過一套演算法來選取leader partion來實現kafka多節點的負載均衡。Zookeeper中儲存了kafka幾乎一切的重要資訊,比如topic,每個topic下面的多個partion資訊,主機節點資訊(包括ip和埠),每個節點下的多個partion資訊,每個partion的主備份資訊,消費客戶端的group_id分組資訊,每個消費者資訊等。通過這一堆資訊進行演算法計算最後得出負載均衡的方案,主要體現是選出讓kafka效率效能達到最好的每個partion的leader。並且在zookeeper中註冊監視器,一旦發現上述資訊有變動則更新負載均衡方案。