
HashMap與CurrentHashMap區別
好像今天沒有什麼原始碼讀,那麼就來看看java的這兩種HashMap有啥不一樣的地方吧,在這之前先普及一下HashMap的一些基本知識:
(1)放入HashMap的元素是key-value對。
(2)底層說白了就是以前資料結構課程講過的雜湊結構。
(3)要將元素放入到hashmap中,那麼key的型別必須要實現實現hashcode方法,預設這個方法是根據物件的地址來計算的,具體我也記不太清楚了,接著還必須覆蓋物件的equal方法。
用一張圖來表示一下雜湊結構吧:

在這裡hashCode函式就是用於確定當前key應該放在hash桶裡面的位置,這裡hash桶可以看成是一個數組,最簡單的通過一些取餘的方法就能用來確認key應該擺放的位置,而equal函式則是為了與後面的元素之間判斷重複。
好了,這裡我們接下來來看看java的這兩種類庫的用法吧:
由於他們都實現了Map介面,將元素放進去的方法就是put(a,b),這裡我們先來分析比較簡單的HashMap吧:
- public V put(K key, V value) {
- if (key == null)
- return putForNullKey(value);
- int hash = hash(key); //獲取當前key的hash值
- int i = indexFor(hash, table.length); //返回在hash桶裡面的位置
- for (Entry<K,V> e = table[i]; e != null; e = e.next) { //遍歷當前hansh桶後面的元素
- Object k;
- if (e.hash == hash && ((k = e.key) == key || key.equals(k))) { //如果有相同的key,那麼需要替換value
- V oldValue = e.value;
- e.value = value;
- e.recordAccess(this);
- return oldValue; //返回以前的value
- }
- }
- modCount++;
- addEntry(hash, key, value, i); //放入entry
- returnnull;
- }
這個函式其實本身還是很簡單的,首先通過hash函式獲取當前key的hash值,不過這裡需要注意的是,對hashCode方法返回的值HashMap本身還會進行一些處理,具體什麼樣子的就不細說了,然後再呼叫indexFor方法用於確定當前key應該屬於當前Hash桶的位置,接著就是遍歷當前桶後面的連結串列了,這裡equal方法就派上用場了,這裡看到如果equal是相等的話,那麼就直接用新的value來替換原來的value就好了。。。
當然最多的情況還是,桶後面的連結串列沒有與當前的key相同的,那麼這個時候就需要呼叫addEntry方法,將要加入的key-value放入到當前的結構中了,那麼接下來來看看這個方法的定義吧:
- void addEntry(int hash, K key, V value, int bucketIndex) {
- if ((size >= threshold) && (null != table[bucketIndex])) {
- resize(2 * table.length); //相當於重新設定hash桶
- hash = (null != key) ? hash(key) : 0;
- bucketIndex = indexFor(hash, table.length);
- }
- createEntry(hash, key, value, bucketIndex); //建立新的entry,並將它加入到當前的桶後面的連結串列中
- }
其實這個方法很簡單,首先來判斷當前的桶的大小,如果覺得太小的話,那麼需要擴充當前桶的大小,這樣可以讓新增元素存放的更離散化一些,優化擦入和尋找的效率。
然後就是建立一個新的entry,用於儲存要擦入的key和value,然後再將其鏈到應該放的桶的連結串列上就好了。。
好了,到這裡位置,整個HashMap的擦入元素的過程就已經看的很清楚了,在整個這個過程中沒有看到有加鎖的過程,因此可以說明HashMap是不支援併發的,不是執行緒安全的,在併發的環境下使用會產生一些不一致的問題。。。
因此java新的concurrent類庫中就有了ConcurrentHashMap用於在併發環境中使用。。
那麼我們再來看看ConcurrentHashMap的put操作是怎麼搞的吧:
- public V put(K key, V value) {
- Segment<K,V> s;
- if (value == null)
- thrownew NullPointerException();
- int hash = hash(key); //獲取hash值
- int j = (hash >>> segmentShift) & segmentMask;
- if ((s = (Segment<K,V>)UNSAFE.getObject // nonvolatile; recheck
- (segments, (j << SSHIFT) + SBASE)) == null) // in ensureSegment //用於獲取相應的片段
- s = ensureSegment(j); //這裡表示沒有這個片段,那麼需要建立這個片段
- return s.put(key, hash, value, false); //這裡就有分段加鎖的策略
- }
這裡剛開始跟HashMap都差不太多吧,無非是先獲取當前key的hash值,但是接下來進行的工作就不太一樣了,這裡就有了一個分段的概念:
ConcurrentHashMap將整個Hash桶進行了分段,也就是將這個大的陣列分成了幾個小的片段,而且每個小的片段上面都有鎖存在,那麼在擦入元素的時候就需要先找到應該插入到哪一個片段,然後再在這個片段上面進行擦入,而且這裡還需要獲取鎖。。。。
那我們來看看這個segment的put方法吧:
- final V put(K key, int hash, V value, boolean onlyIfAbsent) {
- //這裡的鎖是計數鎖,同一個鎖可以被同一個執行緒獲取多次,但是不能被不同的執行緒獲取
- HashEntry<K,V> node = tryLock() ? null : //如果獲取了當前的segment的鎖,那麼node為null,待會自己分配就好了
- scanAndLockForPut(key, hash, value); //如果沒有加上鎖,那麼等吧,有可能的話還要分配entry,反正有時間幹嘛不多做一些事情
- V oldValue;
- try {
- //這裡表示已經獲取了鎖,那麼將在相應的位置放入entry
- HashEntry<K,V>[] tab = table;
- int index = (tab.length - 1) & hash;
- HashEntry<K,V> first = entryAt(tab, index); //找到存放entry的桶,然後獲取第一個entry
- for (HashEntry<K,V> e = first;;) { //從當前的第一個元素開始
- if (e != null) {
- K k;
- if ((k = e.key) == key ||
- (e.hash == hash && key.equals(k))) { //如果key相等,那麼直接替換元素
- oldValue = e.value;
- if (!onlyIfAbsent) {
- e.value = value;
- ++modCount;
- }
- break;
- }
- e = e.next;
- }
- else {
- if (node != null)
- node.setNext(first);
- else
- node = new HashEntry<K,V>(hash, key, value, first);
- int c = count + 1;
- if (c > threshold && tab.length < MAXIMUM_CAPACITY)
- //如果元素太多了,那麼需要重新調整當前的hash結構,讓桶變多一些,這樣元素放的更離散一些
- rehash(node);
- else
- setEntryAt(tab, index, node);
- ++modCount;
- count = c;
- oldValue = null;
- break;
- }
- }
- } finally {
- unlock(); //這裡必須要在finally裡面釋放已經獲取的鎖,這樣才能保證鎖一定會被釋放
- }
- return oldValue;
- }
其實在這裡ConcurrentHashMap和HashMap的區別就已經很明顯了:
(1)ConcurrentHashMap對整個桶陣列進行了分段,而HashMap則沒有
(2)ConcurrentHashMap在每一個分段上都用鎖進行保護,從而讓鎖的粒度更精細一些,併發效能更好,而HashMap沒有鎖機制,不是執行緒安全的。。。
最後用一張圖來表來說明一下ConcurrentHashMap吧:
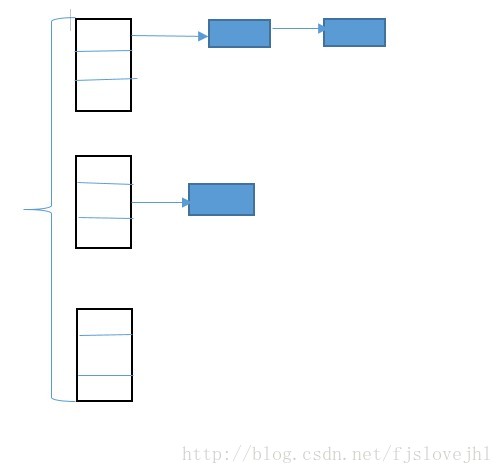
最後,在併發的情況下,要麼使用concurrent類庫中提供的容器,要麼就需要自己來管理資料的同步問題了。。。