
二叉樹--trie樹
閒來無事,寫寫部落格,總結一下trie樹;
| 演算法原理 |
首先,讓我們對trie樹來一個比較直觀的認識,下面的這個例子,大家應該都能夠理解。
下面我們有and,as,at,cn,com這些關鍵詞,那麼如何構建trie樹呢?
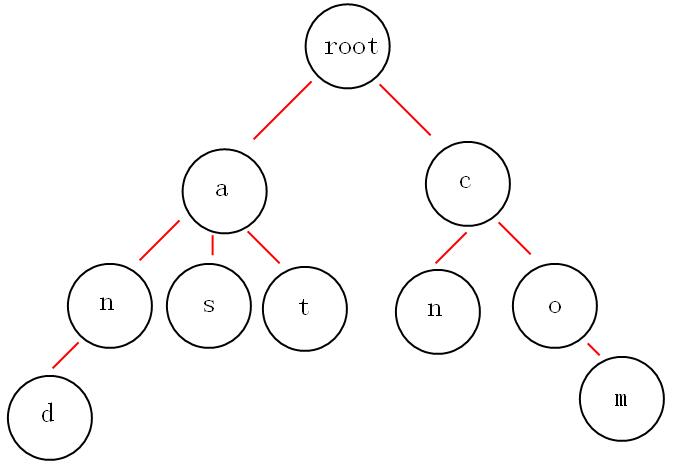
在上面這個棵樹中,樹的根節點沒有儲存任何的資料,就只是root,而將這些單詞按照相同字首,分支節點的順序進行儲存,這樣有一個好處就是,相同字首的單詞的字首我只需要儲存一次就可以了,遍歷樹的每一個“樹枝”,都會得到相對應的單詞。這就是trie樹的基本原理。
第一:根節點不包含字元,除根節點外的每一個子節點都包含一個字元。
第二:從根節點到某一節點,路徑上經過的字元連線起來,就是該節點對應的字串。
第三:每個單詞的公共字首作為一個字元節點儲存。
利用串構建一個字典樹,這個字典樹儲存了串的公共字首資訊,因此可以降低查詢操作的複雜度。
| trie的分類 |
Trie 樹, 又稱字典樹,單詞查詢樹。它來源於retrieval(檢索)中取中間四個字元構成(讀音同try)。用於儲存大量的字串以便支援快速模式匹配。主要應用在資訊檢索領域。
Trie 有三種結構: 標準trie (standard trie)、壓縮trie、字尾trie(suffix trie) 。
| 1. 標準Trie (standard trie) |
標準 Trie樹的結構 : 所有含有公共字首的字串將掛在樹中同一個結點下。實際上trie簡明的儲存了存在於串集合中的所有公共字首。 假如有這樣一個字串集合X{bear,bell,bid,bull,buy,sell,stock,stop}。它的標準Trie樹如下圖:
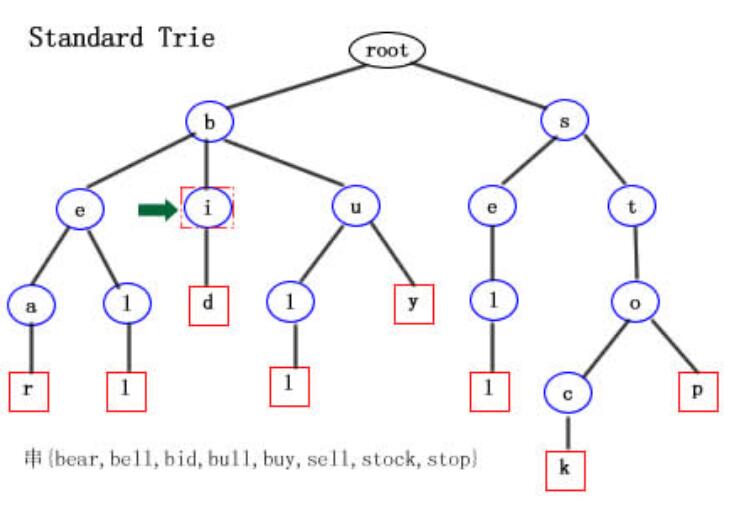
上圖(藍色圓形結點為內部結點,紅色方形結點為外部結點),我們可以很清楚的看到字串集合X構造的Trie樹結構。其中從根結點到紅色方框葉子節點所經歷的所有字元組成的串就是字串集合X中的一個串。
注意這裡有一個問題: 如果X集合中有一個串是另一個串的字首呢? 比如,X集合中加入串bi。那麼上圖的Trie樹在綠色箭頭所指的內部結點i 就應該也標記成紅色方形結點。這樣話,一棵樹的枝幹上將出現兩個連續的葉子結點(這是不合常理的)。
也就是說字串集合X中不存在一個串是另外一個串的字首 。如何滿足這個要求呢?我們可以在X中的每個串後面加入一個特殊字元$(這個字元將不會出現在字母表中)。這樣,集合X{bear$
總結:一個儲存長度為n,來自大小為d的字母表中s個串的集合X的標準trie具有性質如下:
(1) 樹中每個內部結點至多有d個子結點。
(2) 樹有s個外部結點。
(3) 樹的高度等於X中最長串的長度。
(4) 樹中的結點數為O(n)。
標準 Trie樹的查詢
對於英文單詞的查詢,我們完全可以在內部結點中建立26個元素組成的指標陣列。如果要查詢a,只需要在內部節點的指標陣列中找第0個指標即可(b=第1個指標,隨機定位)。時間複雜度為O(1)。
查詢過程:假如我們要在上面那棵Trie中查詢字串bull (b-u-l-l)。
(1) 在root結點中查詢第(‘b’-‘a’=1)號孩子指標,發現該指標不為空,則定位到第1號孩子結點處——b結點。
(2) 在b結點中查詢第(‘u’-‘a’=20)號孩子指標,發現該指標不為空,則定位到第20號孩子結點處——u結點。
(3) … 一直查詢到葉子結點出現特殊字元’$’位置,表示找到了bull字串
如果在查詢過程中終止於內部結點,則表示沒有找到待查詢字串。
效率:對於有n個英文字母的串來說,在內部結點中定位指標所需要花費O(d)時間,d為字母表的大小,英文為26。由於在上面的演算法中內部結點指標定位使用了陣列隨機儲存方式,因此時間複雜度降為了O(1)。但是如果是中文字,下面在實際應用中會提到。因此我們在這裡還是用O(d)。 查詢成功的時候恰好走了一條從根結點到葉子結點的路徑。因此時間複雜度為O(d*n)。
但是,當查詢集合X中所有字串兩兩都不共享字首時,trie中出現最壞情況。除根之外,所有內部結點都自由一個子結點。此時的查詢時間複雜度蛻化為O(d*(n^2))
標準 Trie樹的Java程式碼實現:
import java.util.ArrayList;
enum NodeKind{LN,BN};
/**
* Trie結點
*/
class TrieNode{
char key;
TrieNode[] points=null;
NodeKind kind=null;
}
/**
* Trie葉子結點
*/
class LeafNode extends TrieNode{
LeafNode(char k){
super.key=k;
super.kind=NodeKind.LN;
}
}
/**
* Trie內部結點
*/
class BranchNode extends TrieNode{
BranchNode(char k){
super.key=k;
super.kind=NodeKind.BN;
super.points=new TrieNode[27];
}
}
/**
* Trie樹
*/
public class StandardTrie {
private TrieNode root=new BranchNode(' ');
/**
* 想Tire中插入字串
*/
public void insert(String word){
//System.out.println("插入字串:"+word);
//從根結點出發
TrieNode curNode=root;
//為了滿足字串集合X中不存在一個串是另外一個串的字首
word=word+"$";
//獲取每個字元
char[] chars=word.toCharArray();
//插入
for(int i=0;i<chars.length;i++){
//System.out.println(" 插入"+chars[i]);
if(chars[i]=='$'){
curNode.points[26]=new LeafNode('$');
// System.out.println(" 插入完畢,使當前結點"+curNode.key+"的第26孩子指標指向字元:$");
}
else{
int pSize=chars[i]-'a';
if(curNode.points[pSize]==null){
curNode.points[pSize]=new BranchNode(chars[i]);
// System.out.println(" 使當前結點"+curNode.key+"的第"+pSize+"孩子指標指向字元: "+chars[i]);
curNode=curNode.points[pSize];
}
else{
// System.out.println(" 不插入,找到當前結點"+curNode.key+"的第"+pSize+"孩子指標已經指向字元: "+chars[i]);
curNode=curNode.points[pSize];
}
}
}
}
/**
* Trie的字串全字匹配
*/
public boolean fullMatch(String word){
//System.out.print("查詢字串:"+word+"/n查詢路徑:");
//從根結點出發
TrieNode curNode=root;
//獲取每個字元
char[] chars=word.toCharArray();
for(int i=0;i<chars.length;i++){
if(curNode.key=='$'){
System.out.println('&');
// System.out.println(" 【成功】");
return true;
}else{
System.out.print(chars[i]+" -> ");
int pSize=chars[i]-'a';
if(curNode.points[pSize]==null){
// System.out.println(" 【失敗】");
return false;
}else{
curNode=curNode.points[pSize];
}
}
}
// System.out.println(" 【失敗】");
return false;
}
/**
* 先根遍歷Tire樹
*/
private void preRootTraverse(TrieNode curNode){
if(curNode!=null){
System.out.print(curNode.key+" ");
if(curNode.kind==NodeKind.BN)
for(TrieNode childNode:curNode.points)
preRootTraverse(childNode);
}
}
/**
* 得到Trie根結點
*/
public TrieNode getRoot(){
return this.root;
}
/**
* 測試
*/
public static void main(String[] args) {
StandardTrie trie=new StandardTrie();
trie.insert("bear");
trie.insert("bell");
trie.insert("bid");
trie.insert("bull");
trie.insert("buy");
trie.insert("sell");
trie.insert("stock");
trie.insert("stop");
trie.preRootTraverse(trie.getRoot());
trie.fullMatch("stoops");
}
} 中文詞語的”標準Trie樹”
由於中文的字遠比英文的26個字母多的多。因此對於trie樹的內部結點,不可能用一個26的陣列來儲存指標。如果每個結點都開闢幾萬個中國字的指標空間。估計記憶體要爆了,就連磁碟也消耗很大。
一般我們採取這樣種措施:
(1) 以詞語中相同的第一個字為根組成一棵樹。這樣的話,一箇中文詞彙的集合就可以構成一片Trie森林。這片森林都儲存在磁碟上。森林的root中的字和root所在磁碟的位置都記錄在一張以Unicode碼值排序的有序字表中。字表可以存放在記憶體裡。
(2) 內部結點的指標用可變長陣列儲存。
特點:由於中文詞語很少超過4個字的,因此Trie樹的高度不長。查詢的時間主要耗費在內部結點指標的查詢。因此將這項指向字的指標按照字的Unicode碼值排序,然後載入進記憶體以後通過二分查詢能夠提高效率。
標準Trie樹的應用和優缺點
(1) 全字匹配:確定待查字串是否與集合的一個單詞完全匹配。如上程式碼fullMatch()。
(2) 字首匹配:查詢集合中與以s為字首的所有串。
注意:Trie樹的結構並不適合用來查詢子串。這一點和的PAT Tree(一種特殊的trie樹,主要用來進行字串的匹配)以及後面專門要提到的Suffix Tree的作用有很大不同。
優點: 查詢效率比與集合中的每一個字串做匹配的效率要高很多。在o(m)時間內搜尋一個長度為m的字串s是否在字典裡。
缺點:標準Trie的空間利用率不高,可能存在大量結點中只有一個子結點,這樣的結點絕對是一種浪費。正是這個原因,才迅速推動了下面所講的壓縮trie的開發。
| 壓縮trie |
冗餘結點(redundant node):如果T的一個非根內部結點v只有一個子結點,那麼我們稱v是冗餘的。
冗餘鏈(redundant link):如上標準Trie圖中,內部結點e只有一個內部子結點l,而l也只有一個葉子結點。那麼e-l-l就構成了一條冗餘鏈。
壓縮(compressed):對於冗餘鏈 v1- v2- v3- … -vn,我們可以用單邊v1-vn來替代。
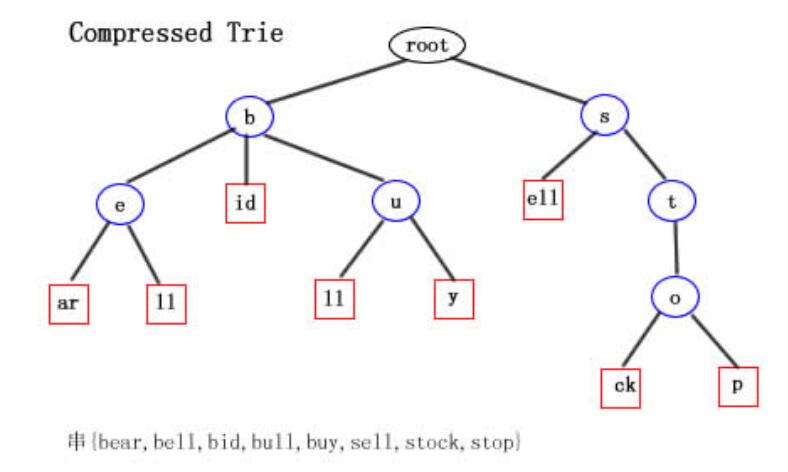
對上面標準Trie的圖壓縮之後,形成了Compressed Trie的字元表示圖如上。
壓縮Trie的性質和優勢:
與標準Trie比較,壓縮Trie的結點數與串的個數成正比了,而不是與串的總長度成正比。一棵儲存來自大小為d的字母表中的s個串的結合T的壓縮trie具有如下性質:
(1) T中的每個內部結點至少有兩個子結點,至多有d個子結點。
(2) T有s個外部結點。
(3) T中的結點數為O(s)
儲存空間從標準Trie的O(n)降低到壓縮後的O(s),其中n為集合T中總字串長度,s為T中的字串個數。
壓縮Trie的壓縮表示
上面的圖是壓縮Trie的字串表示。相比標準Trie而言,確實少了不少結點。但是細心的讀者會發現,葉子結點中的字元數量增加了,比如結點ell,那麼這種壓縮空間的效率當然會打折扣了。那麼有什麼好辦法呢,這裡我們介紹一種壓縮表示方法。即把所有結點中的字串用三元組的形式表示如下圖:
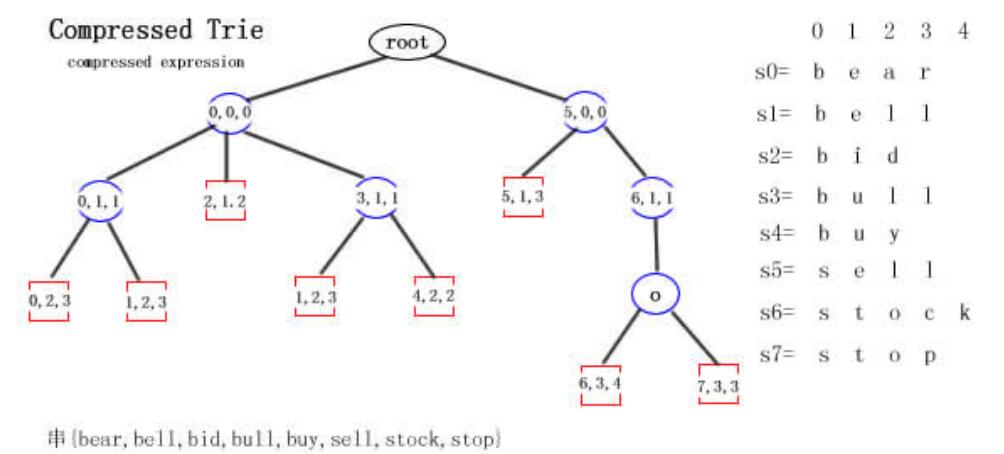
其中三元組(i,j,k)表示S[i]的從第j個位置到第k個位置間的子串。比如(5,1,3,)表示S[5][1…3]=”ell”。
這種壓縮表示的一個巨大的優點就是:無論結點需要儲存多長的字串,全部都可以用一個三元組表示,而且三元組所佔的空間是固定有限的。但是為了做到這一點,必須有一張輔助索引結構(如上圖右側s0—s7所示)。
| 字尾trie |
| 應用場景 |
正如上面所說的,中文分詞中的最大匹配方法的原理就是利用這種字典樹來進行的。
中文分詞一直都是中文自然語言處理領域的基礎研究。目前,網路上流行的很多中文分詞軟體都可以在付出較少的代價的同時,具備較高的正確率。而且不少中文分詞軟體支援Lucene擴充套件。但不管實現如何,目前而言的分詞系統絕大多數都是基於中文詞典的匹配演算法。
在這裡我想介紹一下中文分詞的一個最基礎演算法:最大匹配演算法 (Maximum Matching,以下簡稱MM演算法) 。MM演算法有兩種:一種正向最大匹配,一種逆向最大匹配。
演算法思想
正向最大匹配演算法:從左到右將待分詞文字中的幾個連續字元與詞表匹配,如果匹配上,則切分出一個詞。但這裡有一個問題:要做到最大匹配,並不是第一次匹配到就可以切分的 。我們來舉個例子:
待分詞文字: content[]={“中”,”華”,”民”,”族”,”從”,”此”,”站”,”起”,”來”,”了”,”。”}
詞表: dict[]={“中華”, “中華民族” , “從此”,”站起來”}
(1) 從content[1]開始,當掃描到content[2]的時候,發現"中華"已經在詞表dict[]中了。但還不能切分出來,因為我們不知道後面的詞語能不能組成更長的詞(最大匹配)。
(2) 繼續掃描content[3],發現"中華民"並不是dict[]中的詞。但是我們還不能確定是否前面找到的"中華"已經是最大的詞了。因為"中華民"是dict[2]的字首。
(3) 掃描content[4],發現"中華民族"是dict[]中的詞。繼續掃描下去:
(4) 當掃描content[5]的時候,發現"中華民族從"並不是詞表中的詞,也不是詞的字首。因此可以切分出前面最大的詞——"中華民族"。由此可見,最大匹配出的詞必須保證下一個掃描不是詞表中的詞或詞的字首才可以結束。
演算法實現
詞表的記憶體表示: 很顯然,匹配過程中是需要找詞字首的,因此我們不能將詞表簡單的儲存為Hash結構。在這裡我們使用Trie樹。這種結構使得查詢每一個詞的時間複雜度為O(word.length),而且可以很方便的判斷是否匹配成功或匹配到了字串的字首。
下圖是我們建立的Trie結構詞典的部分,(詞語例子:”中華”,”中華名族”,”中間”,”感召”,”感召力”,”感受”)。
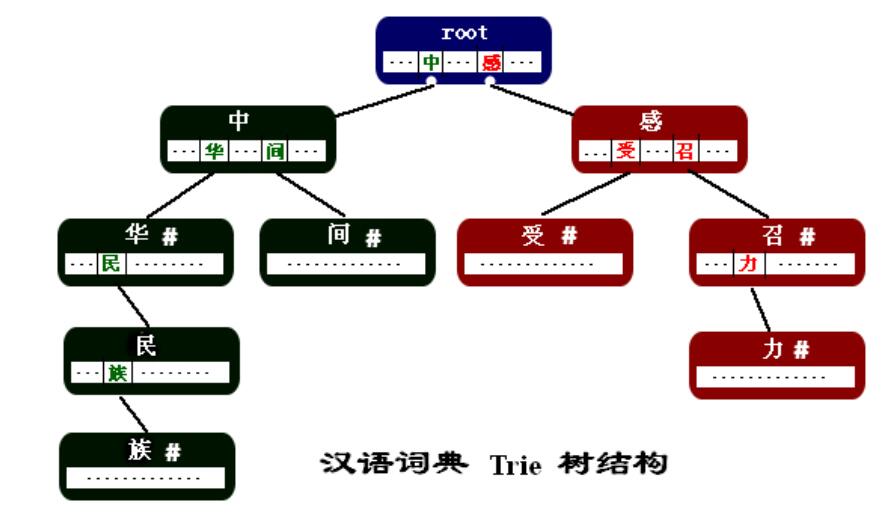
(1) 每個結點都是詞語中的一個漢字。
(2) 結點中的指標指向了該漢字在某一個詞中的下一個漢字。這些指標存放在以漢字為key的hash結構中。
(3) 結點中的”#”表示當前結點中的漢字是從根結點到該漢字結點所組成的詞的最後一個字。