
Mongodb基礎入門(3)——排序和索引
今天繼續Mongodb,簡單的記錄下其排序和索引的使用。
在Mongodb中使用sort()方法對資料進行排序。
命令格式:db.collectionName.find().sort({key:引數})
引數說明:
-1:表示降序
1:表示升序(預設)
doc集合中資料如下:
> db.doc.find({},{_id:0,goods_id:1})
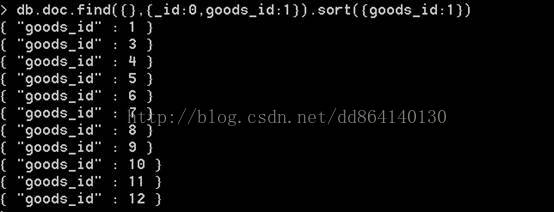
{ "goods_id" : 1 }
{ "goods_id" : 4 }
{ "goods_id" : 3 }
{ "goods_id" : 5 }
{ "goods_id" : 6 }
{ "goods_id" : 7 }
{ "goods_id" : 8 }
{ "goods_id" : 9 }
{ "goods_id" : 10 }
{ "goods_id" : 11 }
{ "goods_id" : 12 }
> db.doc.find({},{_id:0,goods_id:1}).sort({goods_id:1})
索引
1、簡介
和mysql資料類似,為了提高查詢效率,Mongodb也提供索引的支援。在Mongodb中,索引可以按照欄位進行升序/降序來建立,以便於排序。當然,Mongodb預設採用B-tree方式來索引。
按索引作用型別可分為:
1、單列索引:在單個鍵上建立索引。
2、組合索引:在多個鍵上同時建立索引,也叫多列索引。
3、文件索引:任何型別,包括文件(document)都可以作為索引。
索引的性質可以分:
1、普通索引:普通方式建立的索引。注意:Mongodb存在預設的_id的鍵,相當於主鍵。集合在建立之後,系統會自動在_id建立索引,該索引為系統預設,無法刪除。
2、唯一索引:某列為唯一索引時,不能新增重複文件。注意,如果文件不存在指定欄位時,會將該欄位預設為null,而null也會被認為重複。
3、稀疏索引:和稀疏矩陣類似,稀疏索引就是將含有某個欄位的文件進行索引,不包含該欄位的文件則進行索引。一般在小部分文件含有某列時常用。
4、雜湊索引:2.4版本新增的索引方式。相比於普通索引,其速度更快。但是無法對範圍查詢進行優化。多用於隨機性比較強的散列當中。
2、檢視索引
db.collectionName.getIndexes()
3、建立索引
A、建立普通單列索引:預設是升序索引,採用B-tree方式
db.collectionName.ensureIndex({field:1/-1})//1:升序;-1:降序
B、建立多列索引:
db.collectionName.ensureIndex({field1:1/-1,field2:1/-1})
C、建立文件索引:
A)建立普通文件索引
db.collectionName.ensureIndex({filed:1/-1})
> db.users.insert({name:"god",info:{city:"NewYork",state:"happy"}})
WriteResult({"nInserted" : 1 })
>db.users.ensureIndex({info:1})//將整個info文件作為索引
{
"createdCollectionAutomatically" : false,
"numIndexesBefore" : 1,
"numIndexesAfter" : 2,
"ok" : 1
}
>db.users.getIndexes()
[
{
"v" : 1,
"key" : {
"_id" : 1
},
"name" : "_id_",
"ns" : "test.users"
},
{
"v" : 1,
"key" : {
"info" : 1
},
"name" : "info_1",
"ns" : "test.users"
}
]
注意:在使用索引查詢的時候需要按照事先文件欄位的順序。
> db.users.find({info:{city:"NewYork",state:"happy"}})//能夠利用索引查到結果
{ "_id" :ObjectId("54a79a1bc289fc3b6fcc719a"), "name" :"god", "info" : { "city
" : "NewYork", "state" : "happy" } }
>db.users.find({info:{$gte:{city:"New York"}}})//能夠利用索引查到結果
{ "_id" :ObjectId("54a79a1bc289fc3b6fcc719a"), "name" :"god", "info" : { "city
" : "NewYork", "state" : "happy" } }
>db.users.find({info:{state:"happy",city:"New York"}})//不能利用索引查到結果
B)建立子文件索引
db.collectionName.ensureIndex({filed.subfield:1/-1})
> db.users.ensureIndex({"info.city":1})
{
"createdCollectionAutomatically" : false,
"numIndexesBefore" : 1,
"numIndexesAfter" : 2,
"ok" : 1
}
>db.users.getIndexes()
[
{
"v" : 1,
"key" : {
"_id" : 1
},
"name" : "_id_",
"ns" : "test.users"
},
{
"v" : 1,
"key" : {
"info.city" : 1
},
"name" : "info.city_1",
"ns" : "test.users"
}
]
D、建立唯一索引:可以針對多列建立唯一索引
db.collectinName.ensureIndex({filed.subfield:1/-1},{unique:true})
E、建立稀疏索引:
db.collectionName.ensureIndex({filed:1/-1},{sparse:true})
F、建立雜湊索引:可以對單個欄位或字文件建立hash索引,不能針對多個列。
db.collectionName.ensureIndex({field:”hash”})
4、刪除索引
A、刪除單個索引:
db.collectionName.dropIndex({filed:1/-1})
B、刪除所有索引:_id列的索引不會刪除。
db.collectionName.dropIndexes()
注意:在關係資料庫中,表被刪除後,索引隨之刪除。
而在Monodb中刪除集合,索引仍然存在,因此需要手動刪除索引。
5、重建索引
一個集合在經過多次修改之後,將會導致集合的檔案產生碎片。同樣索引檔案也會如此。因此可以通過索引的重建來減少索引檔案碎片,提高索引效率。和mysql中的optimize table類似。命令:db.collectionName.reIndex().
索引的管理
1、查詢所有索引:
system.indexes集合中包含了每個索引的詳細資訊,因此可以通過該命令:
db.system.indexes.find()查詢已經存在的索引.
{"v" : 1, "key" : { "_id" : 1 }, "name": "_id_", "ns" : "test.doc" }
{"v" : 1, "key" : { "_id" : 1 }, "name": "_id_", "ns" : "test.category" }
{"v" : 1, "key" : { "_id" : 1 }, "name": "_id_", "ns" : "test.tea" }
{"v" : 1, "key" : { "email" : 1 },"name" : "sparse:1", "ns" : "test.tea"}
{"v" : 1, "key" : { "_id" : 1 }, "name": "_id_", "ns" : "test.users" }
{"v" : 1, "key" : { "info.city" : 1 },"name" : "info.city_1", "ns" :"test.users" }
2、檢視查詢計劃:
為了分析查詢效能及索引,一邊獲得更多查詢方面有用的資訊,可以使用如下命令:
db.collectionName.find(查詢表示式).explain()

"cursor" :"BasicCursor"——>表示索引沒有發揮作用
"nscanned":1
——>表示查詢了多少個文件。
"n",:1 ——>表示返回的文件數量。
"millis":0 ——>表示整個查詢的耗時。
"nscannedObjects" : 11,——>理論上需要掃描多少行
3、後臺建立索引
為已有資料的文件建立索引時,為了不阻塞其他操作,同時可以在後臺建立索引,可以使用命令:db.test.ensureIndex({filed:1/-1},{"background":true})
相比阻塞建立索引而言,後臺建立索引效率較低。
注意
1、如果資料集合比較小(一般來說是4m一下),此時如果使用sort()進行排序就不需要使用索引。
2、在使用組合索引查詢時,查詢欄位的順序必須和事先建立索引時的順序保持一致。否則會出現上文提到的出現查不到的情況。