推薦演算法CB
推薦方法
• 基於內容Content Based
• 基於協同Collaboration Filtering– User Based CF
– Item Based CF
基於內容(ContentBased)
• 引入Item屬性的Content Based推薦

使用者進入優酷檢視某電影,進入該電影的播放頁面,周圍會有相關item推薦比如廣告、相似電影、演員相關、花絮之內的
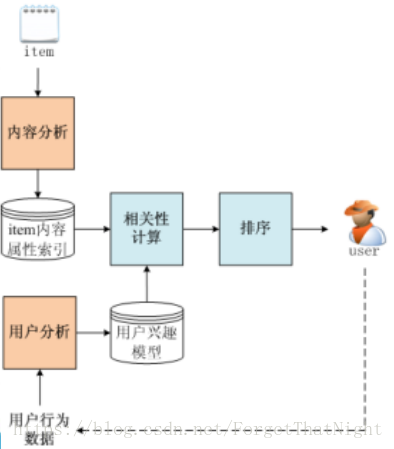
內容分析:
比如某item的正排表--根據名字等元資料進行中文分詞得到關鍵詞(不是標籤,可以通過關鍵詞得到,有時候標籤和關鍵詞不一樣,但更能表現出item的特性)及其權重

當然也可以對其他的元資料進行中文分詞得到正排表,比如name/title、desc、影評、導演、主題、年代、地域、標籤
item內容屬性索引:
做倒排表,然後放進NOSql裡面去
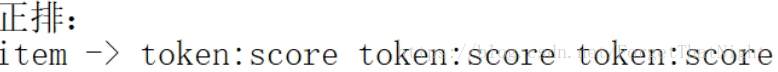
倒排表
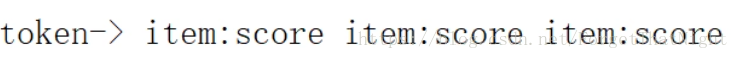
使用者瀏覽資料
相關性計算、排序
user點選了某item(站在資料探勘工程師的角度就是等於元資料資訊),然後推薦系統根據itemA找到其他的item1、item2、item3。但是這種方案比較耗時。
兩種方案
(1):itemA->元資料資訊->內容分析(關鍵詞)->關鍵詞提取token1、token2、token3->通過倒排表查詢得到最終的top(N)->item1、item2
(2):item-item矩陣查詢得到,提前拿到網站所有的item,得到所有正排表和倒排表,加權去重。如果遇到新增的item,如圖所示,一般都是通過storm或者spark streamming等實時流處理框架來進行處理,併入庫。紅色為倒排表--需要實時合併、更新,合併、更新倒排表token時要注意新舊排序與權重的比較
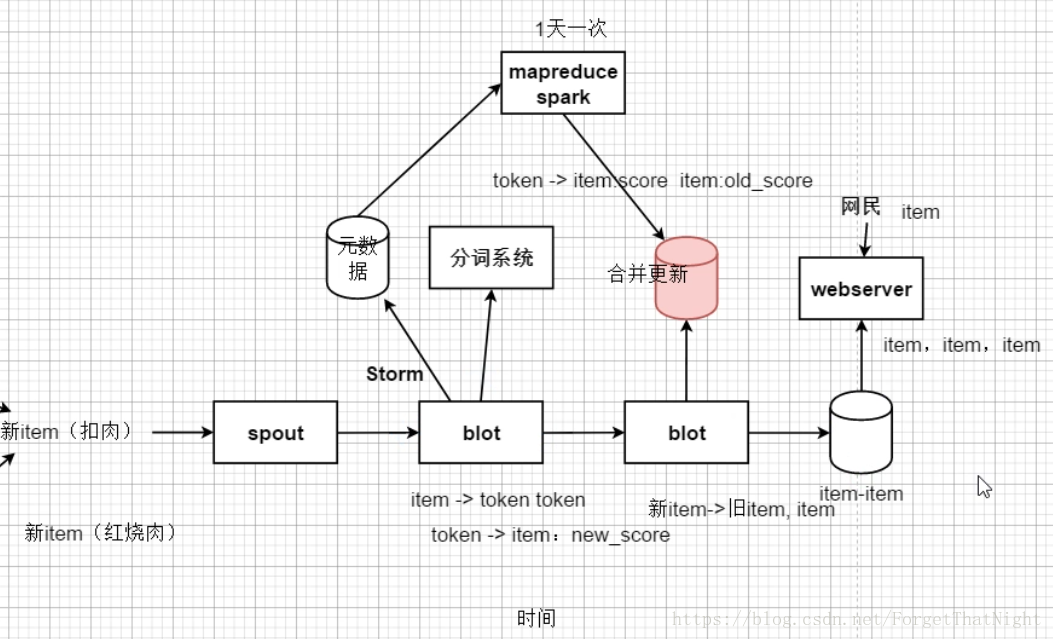
以token為紐帶進行關聯,所以解釋性很強,相關性很強,但是缺點也很明顯,比如張三和李四同時進來點選這一個item,但是以後推薦的卻是同一套東西,然後每個人的喜好都是有區別的。因此,要改進該推薦系統,只能引入使用者畫像。
引入User屬性的Content Based推薦

user使用者畫像表

對最近一週看的電影item1 item2 item3做一個正排表

當用戶點選了item4時,從NOSQL中取出user-item和item list資訊,通過token進行推薦,同時注意更新token和權重。所以引入user屬性的推薦方案有兩種。(1)通過user item和item list進行推薦;(2)通過使用者畫像(user:token:score...)和token(item,item...)列表進行推薦
則需要對使用者user推薦怎樣的個性化列表?
舉個簡單的小例子
我們已知道
• 使用者u1喜歡的電影是A,B,C
• 使用者u2喜歡的電影是A, C, E, F
• 使用者u3喜歡的電影是B,D
我們需要解決的問題是:決定對u1是不是應該推薦F這部電影
基於內容的做法:要分析F的特徵和u1所喜歡的A、B、C的特徵,需要知道的資訊是A(戰爭片),B(戰爭片),C(劇情片),如果F(戰爭片),那麼F很大程度上可以推薦給u1,這是基於內容的做法,你需要對item進行特徵建立和建模。
• “Ferrari” is a car
• John Doe may like “Ferrari”
• 面向使用者興趣的新聞推薦(Item2User)

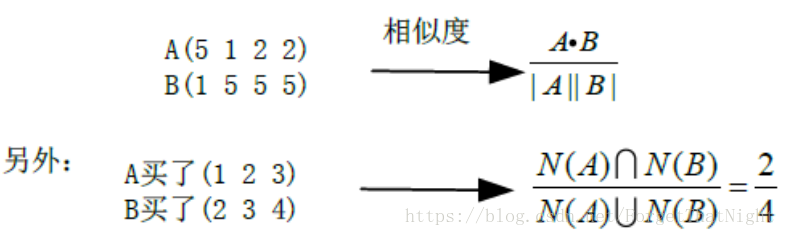
• 例子:通過相似度得到item與item,user與user之間的score,然後按照由高到低排序