
zookeeper中的一致性協議zab
關於一致性協議
說起分散式一致性協議的始祖,就不得不提到larmport大師發表的< The Part-Time Parliament>論文,但在這個論文中描述的paxos演算法很長時間只停留在理論階段,在實際的工程中又出現了很多的變種。Zookeeper的ZAB,Viewstamped Replication(VR),raft,multi-paxos,這些都可以被稱之為Leader-based一致性協議。不同的是,multi-paxos leader是作為對經典paxos的優化而提出,通過選擇一個proposer作為leader降低多個proposer引起衝突的頻率,合併階段一從而將一次決議的平均訊息代價縮小到最優的兩次,實際上就算有多個leader存在,演算法還是安全的,只是退化為經典的paxos演算法。而經典的paxos,從一個提案被提出到被接受分為兩個階段,第一個階段去詢問值,第二階段根據詢問的結果提出值。這兩個階段是無法分割的,兩個階段的每個細節都是精心設計的,相互關聯,共同保障了協議的一致性。而VR,ZAB,Raft這些強調合法leader的唯一性協議,它們直接從leader的角度描述協議的流程,也從leader的角度出發論證正確性。但是實際上它們使用了和Paxos完全一樣的原理來保證協議的安全性,當同時存在多個節點同時嘗試成為leader或者不知一個節點認為自己時leader時,本質上它們和經典Paxos中多個proposer並存的情形沒什麼不同。
演算法描述
和raft一樣,zab中的角色也分別負責三個主要的職能,發起提議的leader,投標表決以及參加競選的follower和沒有任何投票及選舉權的learner。與raft不同的是,zab用的是epoch和count的組合來唯一表示一個entry, 而raft用的是term和index的組合來確定一個entry,其中epoch和count的組合被稱作zxid。
在 ZAB 協議的事務編號 Zxid 設計中,Zxid 是一個 64 位的數字,其中低 32 位是一個簡單的單調遞增的計數器,針對客戶端每一個事務請求,計數器加 1;而高 32 位則代表 Leader 週期 epoch 的編號,每個當選產生一個新的 Leader 伺服器,就會從這個 Leader 伺服器上取出其本地日誌中最大事務的ZXID,並從中讀取 epoch 值,然後加 1,以此作為新的 epoch,並將低 32 位從 0 開始計數。
選舉階段
在這個階段,zab協議可配置多種leader election演算法,包括basic paxos的選舉演算法以及Fast Leader Election。
這個階段結束之後,獲得大多數選票的follower將成為準leader,這時候它還不是leader不能履行leader的職責,隨後的同步階段過後,他才能真正的履行leader的職責。
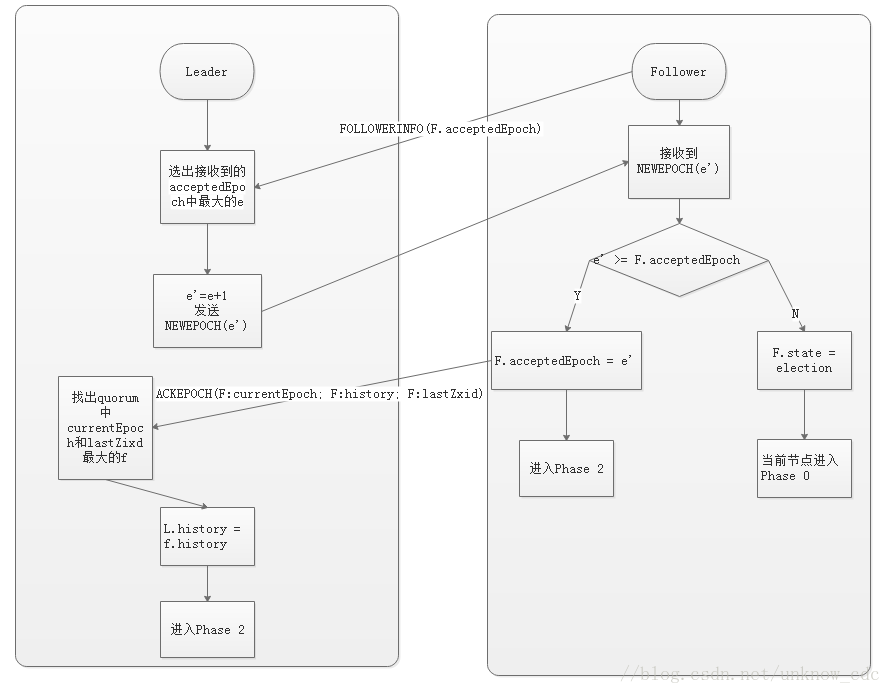
發現階段
在這個階段,followers 跟準 leader 進行通訊,同步 followers 最近接收的事務提議。這個一階段的主要目的是發現當前大多數節點接收的最新提議,並且準 leader 生成新的 epoch,讓 followers 接受,更新它們的 acceptedEpoch
一個 follower 只會連線一個 leader,如果有一個節點 f 認為另一個 follower p 是 leader,f 在嘗試連線 p 時會被拒絕,f 被拒絕之後,就會進入 Phase 0。
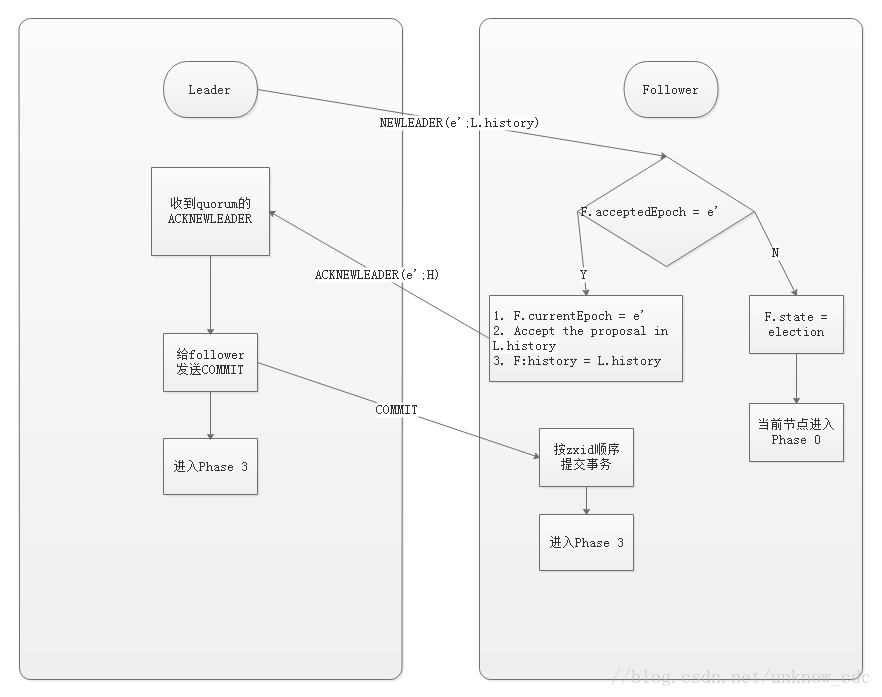
同步階段
同步階段主要是利用 leader 前一階段獲得的最新提議歷史,同步叢集中所有的副本。只有當 quorum 都同步完成,準 leader 才會成為真正的 leader。follower 只會接收 zxid 比自己的 lastZxid 大的提議。
廣播階段
Broadcast模式使用二階段提交,但是簡化了協議,不需要abort。follower要麼ack,要麼拋棄Leader,因為zookeeper保證了每次只有一個Leader。另外也不需要等待所有Server的ACK,只需要一個quorum應答就可以了。
到了這個階段,Zookeeper 叢集才能正式對外提供事務服務,並且 leader 可以進行訊息廣播。同時如果有新的節點加入,還需要對新節點進行同步。
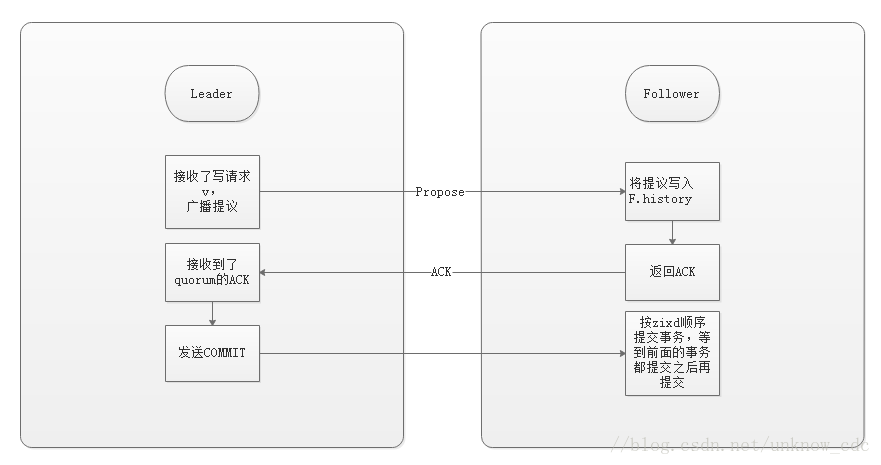
值得注意的是,ZAB 提交事務並不像 2PC 一樣需要全部 follower 都 ACK,只需要得到 quorum (超過半數的節點)的 ACK 就可以了。
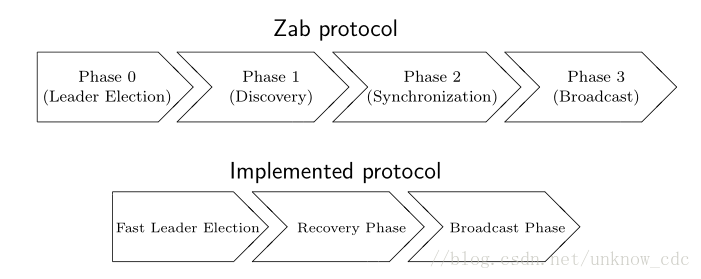
回覆階段
在工程實現中通常會把發現階段與同步階段合併成一個恢復階段
一致性保證
- 全域性有序:如果訊息 a 在訊息 b 之前被投遞,那麼在任何一臺伺服器,訊息 a都會在訊息 b 之前被投遞。
- 因果有序:如果訊息 a 在訊息 b 之前發生(a 導致了 b),並被一起傳送,則 a 始終在 b 之前被執行。
VS Raft
raft的基於日誌複製的狀態機,對日誌的要求是連續的,而zab則是由multi paxos延伸出來的,允許有日誌空洞,所以zab對網路抖動的容忍性更高。
zab選舉leader的過程非常嚴格,開始要經歷準leader階段,同步階段之後才能開始真正的履行leader的職責。而相比於raft,raft的leader選舉則相對寬鬆,所以在leader從宕機到重新加入叢集的過程中,raft的情況要相對複雜得多。
關於心跳,raft只是單向的從leader到follower,在follower超時之後轉變為candidate發起競選,而zab實現了雙向的資料流動,zab通過leader及follower都可以轉變為candidate發出競選。