zookeeper中的ZAB協議
ZAB協議用途
ZAB(Zookeeper Atomic Broadcast) 協議是為分散式協調服務zookeeper專門設計的一種支援崩潰恢復的原子廣播協議。在zookeeper中,主要依賴ZAB協議來實現分散式資料一致性,基於該協議,zookeeper實現了一種主備模式的系統架構來保持叢集中各個副本之間的資料一致性。
ZAB協議介紹
ZAB協議包含兩種基本模式,分別是:
1》崩潰恢復之資料恢復
2》訊息廣播之原子廣播
當整個叢集正在啟動時,或者當leader節點出現網路中斷、崩潰等情況時,ZAB協議就會進入恢復模式並選舉產生新的leader,當leader伺服器選舉出來後,並且叢集中有過半的機器和該leader節點完成資料同步後(同步指的是資料同步,用來保證叢集中過半的機器能夠和leader伺服器的資料狀態保持一致),ZAB協議就會退出恢復模式。
當叢集中已經有過半的Follower節點完成了和Leader狀態同步以後,那麼整個叢集就進入了訊息廣播模式。這個時候,在Leader節點正常工作時,啟動一臺新的伺服器加入到叢集,那這個伺服器會直接進入資料恢復模式,和leader節點進行資料同步。同步完成後即可正常對外提供非事務請求的處理。
訊息廣播(原子廣播)
訊息廣播實際上是一個簡化版的2PC提交過程。
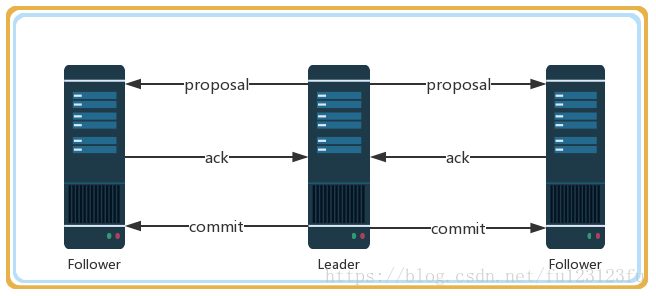
過程:
1》leader接收到訊息請求後,將訊息賦予一個全域性唯一的64位自增id,叫:zxid,通過zxid的大小比較就可以實現因果有序這個特徵。
2》leader為每個follower準備了一個FIFO佇列(通過TCP協議來實現,以實現全域性有序這一個特點)將帶有zxid的訊息作為一個提案(proposal)分發給所有的 follower。
3》當follower接收到proposal,先把proposal寫到磁碟,寫入成功以後再向leader回覆一個ack。
4》當leader接收到合法數量(超過半數節點)的ack後,leader就會向這些follower傳送commit命令,同時會在本地執行該訊息。
5》當follower收到訊息的commit命令以後,會提交該訊息。
崩潰恢復(資料恢復)
ZAB協議的這個基於原子廣播協議的訊息廣播過程,在正常情況下是沒有任何問題的,但是一旦Leader節點崩潰,或者由於網路問題導致Leader伺服器失去了過半的Follower節點的聯絡(leader失去與過半follower節點聯絡,可能是leader節點和 follower節點之間產生了網路分割槽,那麼此時的leader不再是合法的leader了),那麼就會進入到崩潰恢復模式。在ZAB協議中,為了保證程式的正確執行,整個恢復過程結束後需要選舉出一個新的Leader。
為了使leader掛了後系統能正常工作,需要解決以下兩個問題:
1》已經被處理的訊息不能丟失
當leader收到合法數量follower的ack後,就向各個follower廣播commit命令,同時也會在本地執行commit並向連線的客戶端返回「成功」。但是如果各個follower在收到commit命令前leader就掛了,導致剩下的伺服器並沒有執行到這條訊息。
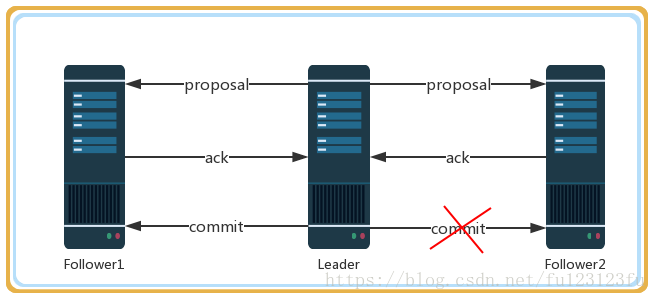
leader對事務訊息發起commit操作,該訊息在follower1上執行了,但是follower2還沒有收到commit,leader就已經掛了,而實際上客戶端已經收到該事務訊息處理成功的回執了。所以在zab協議下需要保證所有機器都要執行這個事務訊息,必須滿足已經被處理的訊息不能丟失。
2》被丟棄的訊息不能再次出現
當leader接收到訊息請求生成proposal後就掛了,其他follower並沒有收到此proposal,因此經過恢復模式重新選了leader後,這條訊息是被跳過的。 此時,之前掛了的leader重新啟動並註冊成了follower,他保留了被跳過訊息的proposal狀態,與整個系統的狀態是不一致的,需要將其刪除。(leader都換代了,所以以前leader的proposal失效了)
針對崩潰恢復的兩種情況分析
ZAB協議需要滿足上面兩種情況,就必須要設計一個leader選舉演算法,能夠確保已經被leader提交的事務Proposal能夠提交、同時丟棄已經被跳過的事務Proposal。
針對這個要求:
如果leader選舉演算法能夠保證新選舉出來的Leader伺服器擁有叢集中所有機器最高編號(ZXID 最大)的事務Proposal,那麼就可以保證這個新選舉出來的leader一定具有已經提交的提案。因為所有提案被commit之前必須有超過半數的follower ack,即必須有超過半數節點的伺服器的事務日誌上有該提案的proposal,因此只要有合法數量的節點正常工作,就必然有一個節點儲存了所有被commit訊息的proposal狀態。
另外一個,zxid是64位,高32位是epoch編號,每經過一次Leader選舉產生一個新的leader,新的leader會將epoch號+1,低32位是訊息計數器,每接收到一條訊息這個值+1,新leader選舉後這個值重置為0。這樣設計的好處在於老的leader掛了以後重啟,它不會被選舉為leader,因此此時它的zxid肯定小於當前新的leader。當老的leader作為follower接入新的leader後,新的leader會讓它將所有的擁有舊的epoch號的未被commit的proposal清除。
關於ZXID
zxid,也就是事務id,為了保證事務的順序一致性,zookeeper採用了遞增的事務id號(zxid)來標識事務。所有的提議(proposal)都在被提出的時候加上了zxid,實際中zxid是一個64位的數字,它高32位是epoch(ZAB協議通過epoch編號來區分Leader週期變化的策略)用來標識leader關係是否改變,每次一個leader被選出來,它都會有一個新的epoch=(原來的epoch+1),標識當前屬於那個leader的統治時期。低32位用於遞增計數。
epoch:可以理解為當前叢集所處的年代或者週期,每個leader就像皇帝,都有自己的年號,所以每次改朝換代,leader變更之後,都會在前一個年代的基礎上加1。這樣就算舊的leader崩潰恢復之後,也沒有人聽他的了,因為follower只聽從當前年代的leader的命令。
測試epoch的變化
要測試epoch的變化可以做一個簡單的實驗:
1》啟動一個zookeeper叢集。
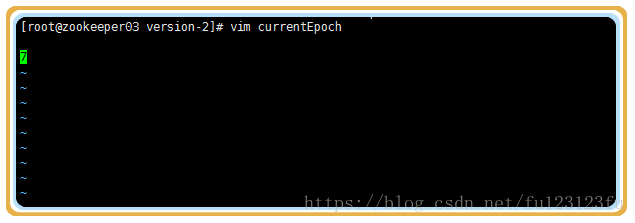
2》在 /tmp/zookeeper/VERSION-2 路徑下會看到一個currentEpoch檔案,檔案中顯示的是當前的epoch。
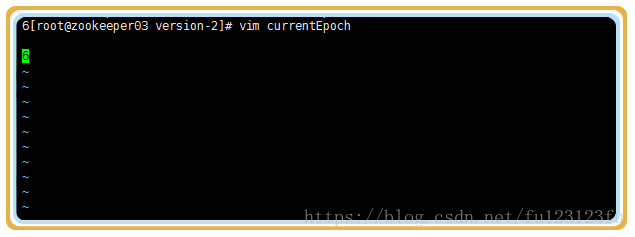
3》把leader節點停機,這個時候在看currentEpoch會發生變化。 隨著每次選舉新的leader,epoch都會發生變化。
1>先找到leader節點
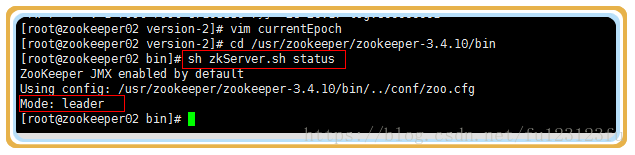
2>停止leader節點的服務

3>檢視當前epoch號的變化(epoch號由原來的6變為7)