
檔案壓縮(平臺Linux & 語言C++)
阿新 • • 發佈:2019-02-10
- 哈夫曼樹:根據一系列權值,每次選出其中最小的兩個作為兩個樹節點,把這兩個節點的和作為他們的根節點並把根節點放入這個權值向量中,再次取出其中最小的兩個,構建另外的節點,這樣最後剩下一個節點就是哈夫曼樹的根節點。 哈夫曼樹特點: 權值都放在了葉子節點上; 因為每次選最小的兩個,從下到上構建哈夫曼樹,這樣,權值較大的都放到上層,較小的都放到下層。
- 哈夫曼編碼: 從根節點往下遍歷,若規定向左,則為0,反之則為1,這樣每個權值都有一個唯一的路徑,也就有一個唯一的編碼,這個編碼成為哈夫曼編碼;
- 如果把一個檔案中字元出現的次數作為權值,這樣,出現次數多的字元都被放到上層,這個字元的編碼就比較短,因為哈夫曼編碼是以二進位制位為單位,總體下來,壓縮檔案大小是小於原始檔的,從而達到壓縮的目的。
(3)主要技術:哈夫曼樹,哈夫曼編碼,堆
(4)哈夫曼編碼原理:

(5)工程框架&效率比較:
使用open/read/write系列函式完成的:
使用fopen/fread/fwrite系列函式完成的:
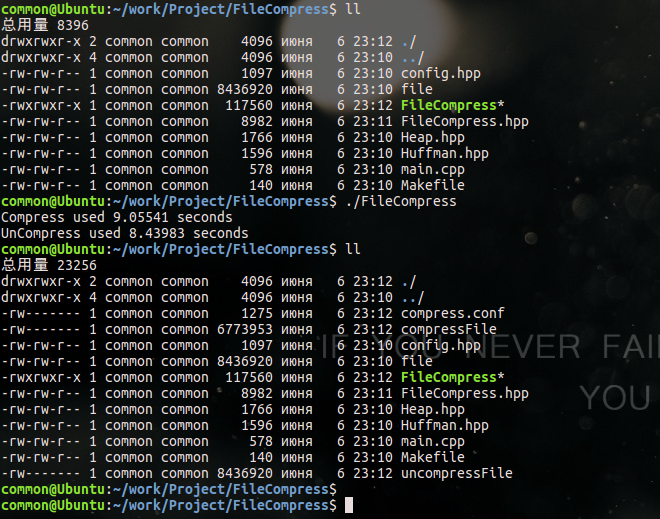
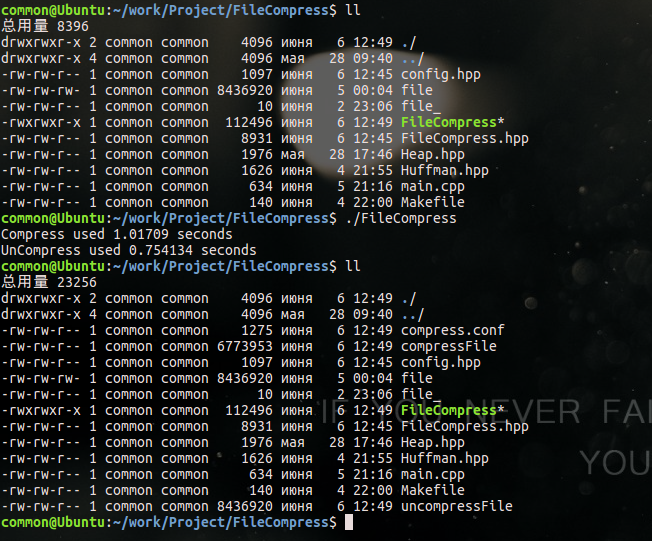
從以上兩幅圖可以看出,使用fread系列函式比使用read系列函式,效能提升了10倍,這是因為fread系列函式從某種程度優於read系列函式,這裡先不說,等文章最後給出兩者的差別。
(6)最終執行結果:
沒有定義 PRINT 巨集:
(ps: PRINT 巨集是條件編譯,是否編譯列印哈夫曼樹的函式)
定義了PRINT巨集:
(ps:列印的內容是 檔案中出現的字元+冒號+該字元在該檔案中出現的次數+換行。
這裡因為圖片太大,只截取了其中一部分,上面還有很多字元的資訊沒有顯示出來)
下面是原檔案(待壓縮檔案)和解壓縮檔案的對比:(使用了軟體Compare來比較)
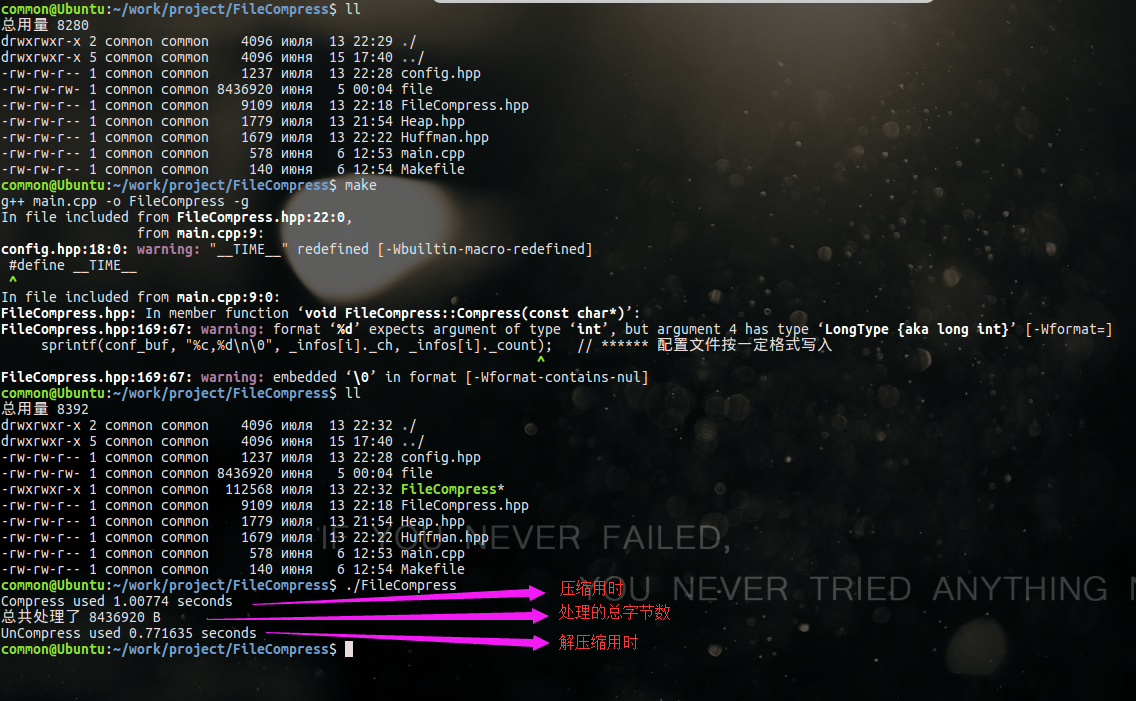
可以看出,解壓縮檔案與原檔案一模一樣,說明壓縮與解壓縮沒有問題。
附: fread系列函式與read系列函式的比較:
1. 如果程式對記憶體有限制,則用read/write比較好。 2. fopen返回檔案指標,open返回檔案描述符(整數).。 3. fopen是標準C的庫函式,操作的物件是 檔案指標,open是POSIX中定義的,是系統呼叫,操作物件是檔案描述符。 4. 前者fopen/fread的實現是靠呼叫底層的open/read來實現的。 5. fopen不能指定要建立檔案的許可權,open可以指定許可權. 6. fread可以讀一個結構. read在linux/unix中讀二進位制與普通檔案沒有區別. 7. linux/unix中任何裝置都是檔案,都可以用open,read.
最重要的一點,read是系統呼叫,呼叫該函式會陷入核心態,而程式不斷從使用者態到核心態切換,會消耗大量的CPU時間,所以對於處理約8000000 位元組的資料,fread系列函式能比read系列函式效能提升10倍。