
cnn 卷積神經網路各層介紹和典型神經網路
轉載:https://blog.csdn.net/cxmscb/article/details/71023576
原部落格附帶tensorflow cnn實現
一、CNN的引入
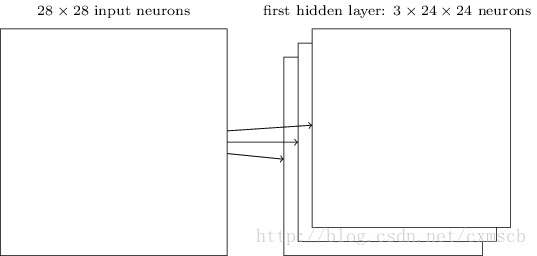
在人工的全連線神經網路中,每相鄰兩層之間的每個神經元之間都是有邊相連的。當輸入層的特徵維度變得很高時,這時全連線網路需要訓練的引數就會增大很多,計算速度就會變得很慢,例如一張黑白的 28×28
的手寫數字圖片,輸入層的神經元就有784個,如下圖所示:

若在中間只使用一層隱藏層,引數 w
就有 784×15=11760 多個;若輸入的是28×28 帶有顏色的RGB格式的手寫數字圖片,輸入神經元就有28×28×3=2352個…… 。這很容易看出使用全連線神經網路處理影象中的需要訓練引數過多的問題。
而在卷積神經網路(Convolutional Neural Network,CNN)中,卷積層的神經元只與前一層的部分神經元節點相連,即它的神經元間的連線是非全連線的,且同一層中某些神經元之間的連線的權重 w
和偏移 b是共享的(即相同的),這樣大量地減少了需要訓練引數的數量。
卷積神經網路CNN的結構一般包含這幾個層:
- 輸入層:用於資料的輸入
- 卷積層:使用卷積核進行特徵提取和特徵對映
- 激勵層:由於卷積也是一種線性運算,因此需要增加非線性對映
- 池化層:進行下采樣,對特徵圖稀疏處理,減少資料運算量。
- 全連線層:通常在CNN的尾部進行重新擬合,減少特徵資訊的損失
- 輸出層:用於輸出結果
當然中間還可以使用一些其他的功能層:
- 歸一化層(Batch Normalization):在CNN中對特徵的歸一化
- 切分層:對某些(圖片)資料的進行分割槽域的單獨學習
- 融合層:對獨立進行特徵學習的分支進行融合
二、CNN的層次結構
輸入層:
在CNN的輸入層中,(圖片)資料輸入的格式 與 全連線神經網路的輸入格式(一維向量)不太一樣。CNN的輸入層的輸入格式保留了圖片本身的結構。
對於黑白的 28×28
的圖片,CNN的輸入是一個 28×28的的二維神經元,如下圖所示:
而對於RGB格式的28×28
圖片,CNN的輸入則是一個 3×28×28 的三維神經元(RGB中的每一個顏色通道都有一個 28×28的矩陣),如下圖所示:

卷積層:
在卷積層中有幾個重要的概念:
- local receptive fields(感受視野)
- shared weights(共享權值)
假設輸入的是一個 28×28
的的二維神經元,我們定義5×5 的 一個 local receptive fields(感受視野),即 隱藏層的神經元與輸入層的5×5個神經元相連,這個5*5的區域就稱之為Local Receptive Fields,如下圖所示:

可類似看作:隱藏層中的神經元 具有一個固定大小的感受視野去感受上一層的部分特徵。在全連線神經網路中,隱藏層中的神經元的感受視野足夠大乃至可以看到上一層的所有特徵。
而在卷積神經網路中,隱藏層中的神經元的感受視野比較小,只能看到上一次的部分特徵,上一層的其他特徵可以通過平移感受視野來得到同一層的其他神經元,由同一層其他神經元來看:

設移動的步長為1:從左到右掃描,每次移動 1 格,掃描完之後,再向下移動一格,再次從左到右掃描。
具體過程如動圖所示:
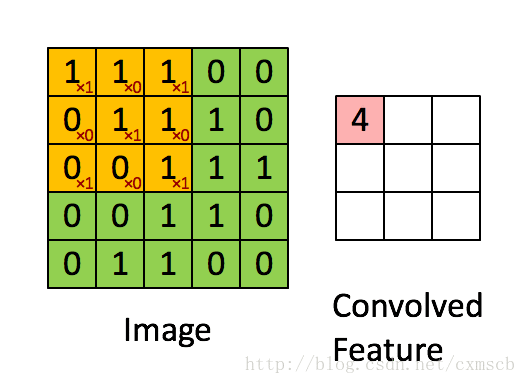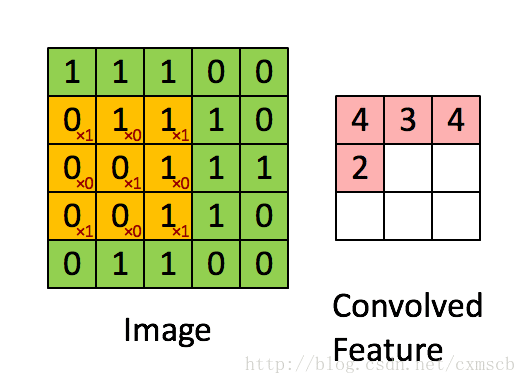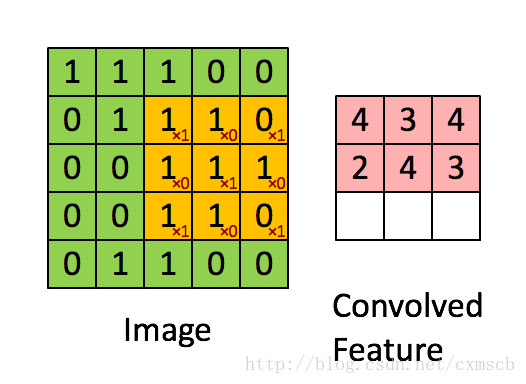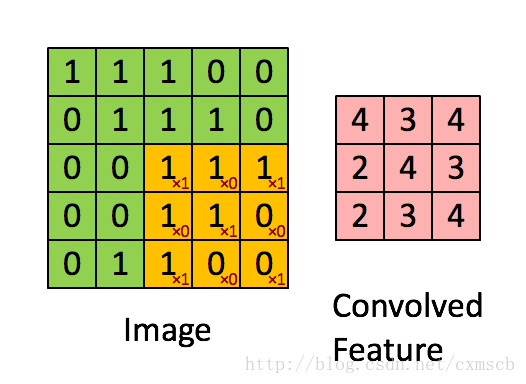

可看出 卷積層的神經元是隻與前一層的部分神經元節點相連,每一條相連的線對應一個權重 w
。
一個感受視野帶有一個卷積核,我們將 感受視野 中的權重 w
矩陣稱為 卷積核 ;將感受視野對輸入的掃描間隔稱為步長(stride);當步長比較大時(stride>1),為了掃描到邊緣的一些特徵,感受視野可能會“出界”,這時需要對邊界擴充(pad),邊界擴充可以設為 0或 其他值。步長 和 邊界擴充值的大小由使用者來定義。
卷積核的大小由使用者來定義,即定義的感受視野的大小;卷積核的權重矩陣的值,便是卷積神經網路的引數,為了有一個偏移項 ,卷積核可附帶一個偏移項 b
,它們的初值可以隨機來生成,可通過訓練進行變化。
因此 感受視野 掃描時可以計算出下一層神經元的值為:
b+∑i=04∑j=04wijxij對下一層的所有神經元來說,它們從不同的位置去探測了上一層神經元的特徵。
我們將通過 一個帶有卷積核的感受視野 掃描生成的下一層神經元矩陣 稱為 一個feature map (特徵對映圖),如下圖的右邊便是一個 feature map:
因此在同一個 feature map 上的神經元使用的卷積核是相同的,因此這些神經元 shared weights,共享卷積核中的權值和附帶的偏移。一個 feature map 對應 一個卷積核,若我們使用 3 個不同的卷積核,可以輸出3個feature map:(感受視野:5×5,布長stride:1)
因此在CNN的卷積層,我們需要訓練的引數大大地減少到了 (5×5+1)×3=78
個。
假設輸入的是 28×28
的RGB圖片,即輸入的是一個 3×28×28的的二維神經元,這時卷積核的大小不只用長和寬來表示,還有深度,感受視野也對應的有了深度,如下圖所示:
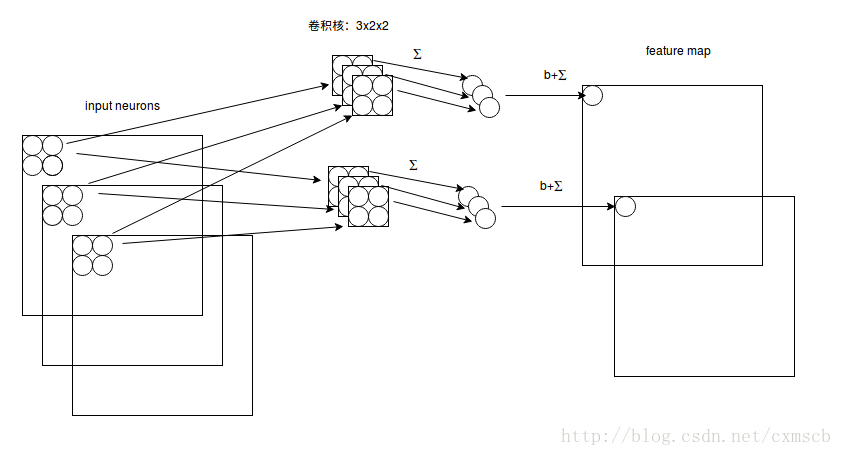
由圖可知:感受視野: 3×2×2
; 卷積核: 3×2×2 ,深度為3;下一層的神經元的值為:b+∑2d=0∑1i=0∑1j=0wdijxdij. 卷積核的深度和感受視野的深度相同,都由輸入資料來決定,長寬可由自己來設定,數目也可以由自己來設定,一個卷積核依然對應一個 feature map 。
注:“stride=1
”表示在長和寬上的移動間隔都為1,即 stridewidth=1 且 strideheight=1激勵層:
激勵層主要對卷積層的輸出進行一個非線性對映,因為卷積層的計算還是一種線性計算。使用的激勵函式一般為ReLu函式:
f(x)=max(x,0)卷積層和激勵層通常合併在一起稱為“卷積層”。
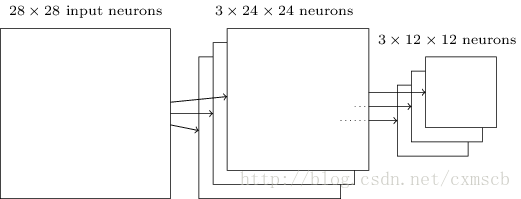
池化層:
當輸入經過卷積層時,若感受視野比較小,布長stride比較小,得到的feature map (特徵圖)還是比較大,可以通過池化層來對每一個 feature map 進行降維操作,輸出的深度還是不變的,依然為 feature map 的個數。
池化層也有一個“池化視野(filter)”來對feature map矩陣進行掃描,對“池化視野”中的矩陣值進行計算,一般有兩種計算方式:
- Max pooling:取“池化視野”矩陣中的最大值
- Average pooling:取“池化視野”矩陣中的平均值
掃描的過程中同樣地會涉及的掃描布長stride,掃描方式同卷積層一樣,先從左到右掃描,結束則向下移動布長大小,再從左到右。如下圖示例所示:
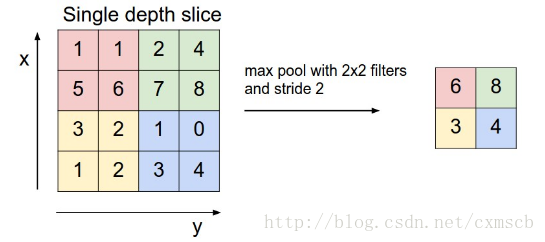
其中“池化視野”filter: 2×2
;布長stride:2。(注:“ 池化視野”為個人叫法)
最後可將 3 個 24×24
的 feature map 下采樣得到 3 個 24×24的特徵矩陣:
歸一化層:
1. Batch Normalization
Batch Normalization(批量歸一化)實現了在神經網路層的中間進行預處理的操作,即在上一層的輸入歸一化處理後再進入網路的下一層,這樣可有效地防止“梯度彌散”,加速網路訓練。
Batch Normalization具體的演算法如下圖所示:

每次訓練時,取 batch_size 大小的樣本進行訓練,在BN層中,將一個神經元看作一個特徵,batch_size 個樣本在某個特徵維度會有 batch_size 個值,然後在每個神經元 xi
維度上的進行這些樣本的均值和方差,通過公式得到 xi∧,再通過引數 γ 和 β 進行線性對映得到每個神經元對應的輸出 yi 。在BN層中,可以看出每一個神經元維度上,都會有一個引數 γ 和 β ,它們同權重w一樣可以通過訓練進行優化。
在卷積神經網路中進行批量歸一化時,一般對 未進行ReLu啟用的 feature map進行批量歸一化,輸出後再作為激勵層的輸入,可達到調整激勵函式偏導的作用。
一種做法是將 feature map 中的神經元作為特徵維度,引數 γ
和 β 的數量和則等於 2×fmapwidth×fmaplength×fmapnum,這樣做的話引數的數量會變得很多;
另一種做法是把 一個 feature map 看做一個特徵維度,一個 feature map 上的神經元共享這個 feature map的 引數 γ
和 β ,引數 γ 和 β 的數量和則等於 2×fmapnum,計算均值和方差則在batch_size個訓練樣本在每一個feature map維度上的均值和方差。
注:fmapnum
指的是一個樣本的feature map數量,feature map 跟神經元一樣也有一定的排列順序。
Batch Normalization 演算法的訓練過程和測試過程的區別:
在訓練過程中,我們每次都會將 batch_size 數目大小的訓練樣本 放入到CNN網路中進行訓練,在BN層中自然可以得到計算輸出所需要的 均值 和 方差 ;
而在測試過程中,我們往往只會向CNN網路中輸入一個測試樣本,這是在BN層計算的均值和方差會均為 0,因為只有一個樣本輸入,因此BN層的輸入也會出現很大的問題,從而導致CNN網路輸出的錯誤。所以在測試過程中,我們需要藉助訓練集中所有樣本在BN層歸一化時每個維度上的均值和方差,當然為了計算方便,我們可以在 batch_num 次訓練過程中,將每一次在BN層歸一化時每個維度上的均值和方差進行相加,最後再進行求一次均值即可。
2. Local Response Normalization
近鄰歸一化(Local Response Normalization)的歸一化方法主要發生在不同的相鄰的卷積核(經過ReLu之後)的輸出之間,即輸入是發生在不同的經過ReLu之後的 feature map 中。
LRN的公式如下:
b(i,x,y)=a(i,x,y)(k+α∑min(N−1,i+n/2)j=max(0,i−n/2)a(j,x,y)2)β其中:
a(i,x,y)
b(i,x,y) 表示 a(i,x,y) 經LRN後的輸出。
N 表示卷積核的數量,即輸入的 feature map的個數。
n 表示近鄰的卷積核(或feature map)個數,由自己來決定。
k,α,β
是超引數,由使用者自己調整或決定。
與BN的區別:BN依據mini batch的資料,近鄰歸一僅需要自己來決定,BN訓練中有學習引數;BN歸一化主要發生在不同的樣本之間,LRN歸一化主要發生在不同的卷積核的輸出之間。
切分層:
在一些應用中,需要對圖片進行切割,獨立地對某一部分割槽域進行單獨學習。這樣可以對特定部分進行通過調整 感受視野 進行力度更大的學習。
融合層:
融合層可以對切分層進行融合,也可以對不同大小的卷積核學習到的特徵進行融合。
例如在GoogleLeNet 中,使用多種解析度的卷積核對目標特徵進行學習,通過 padding 使得每一個 feature map 的長寬都一致,之後再將多個 feature map