
python自然語言處理 第二章(上)
阿新 • • 發佈:2019-02-11
古騰堡語料庫
布朗語料庫import nltk nltk.corpus.gutenberg.fileids() Out[78]: [u'austen-emma.txt', u'austen-persuasion.txt', u'austen-sense.txt', u'bible-kjv.txt', u'blake-poems.txt', u'bryant-stories.txt', u'burgess-busterbrown.txt', u'carroll-alice.txt', u'chesterton-ball.txt', u'chesterton-brown.txt', u'chesterton-thursday.txt', u'edgeworth-parents.txt', u'melville-moby_dick.txt', u'milton-paradise.txt', u'shakespeare-caesar.txt', u'shakespeare-hamlet.txt', u'shakespeare-macbeth.txt', u'whitman-leaves.txt'] # 挑選第一個簡·奧斯丁的《愛瑪》,並賦予一個簡短的名字emma emma = nltk.corpus.gutenberg.words('austen-emma.txt') len(emma) Out[81]: 192427 # 另一種輸入方式 from nltk.corpus import gutenberg gutenberg.fileids() Out[84]: [u'austen-emma.txt', u'austen-persuasion.txt', u'austen-sense.txt', u'bible-kjv.txt', u'blake-poems.txt', u'bryant-stories.txt', u'burgess-busterbrown.txt', u'carroll-alice.txt', u'chesterton-ball.txt', u'chesterton-brown.txt', u'chesterton-thursday.txt', u'edgeworth-parents.txt', u'melville-moby_dick.txt', u'milton-paradise.txt', u'shakespeare-caesar.txt', u'shakespeare-hamlet.txt', u'shakespeare-macbeth.txt', u'whitman-leaves.txt'] emma = gutenberg.words('austen-emma.txt') # 通過遍歷前面列出的gutenberg檔案識別符號連結串列相應的fileid,計算統計每個文字 for fileid in gutenberg.fileids(): num_chars = len(gutenberg.raw(fileid)) # 文字中出現的詞彙個數,包括詞之間的空格 num_words = len(gutenberg.words(fileid)) num_sents = len(gutenberg.sents(fileid)) # 把文字劃分為句子,每個句子是一個詞連結串列 num_vocab = len(set([w.lower() for w in gutenberg.words(fileid)])) print int(num_chars/num_words),int(num_words/num_sents),int(num_words/num_vocab),fileid 4 24 26 austen-emma.txt 4 26 16 austen-persuasion.txt 4 28 22 austen-sense.txt 4 33 79 bible-kjv.txt 4 19 5 blake-poems.txt 4 19 14 bryant-stories.txt 4 17 12 burgess-busterbrown.txt 4 20 12 carroll-alice.txt 4 20 11 chesterton-ball.txt 4 22 11 chesterton-brown.txt 4 18 10 chesterton-thursday.txt 4 20 24 edgeworth-parents.txt 4 25 15 melville-moby_dick.txt 4 52 10 milton-paradise.txt 4 11 8 shakespeare-caesar.txt 4 12 7 shakespeare-hamlet.txt 4 12 6 shakespeare-macbeth.txt 4 36 12 whitman-leaves.txt # 得到三個統計量:平均詞長、平均句子長度、文字中每個詞出現的平均次數 macbeth_sentences = gutenberg.sents('shakespeare-macbeth.txt') macbeth_sentences ]: [[u'[', u'The', u'Tragedie', u'of', u'Macbeth', u'by', u'William', u'Shakespeare', u'1603', u']'], [u'Actus', u'Primus', u'.'], ...] macbeth_sentences[1037] Out[90]: [u'Good', u'night', u',', u'and', u'better', u'health', u'Attend', u'his', u'Maiesty'] longest_len = max([len(s) for s in macbeth_sentences]) [s for s in macbeth_sentences if len(s) == longest_len] Out[92]: [[u'Doubtfull', u'it', u'stood', u',', u'As', u'two', u'spent', u'Swimmers', u',', u'that', u'doe', u'cling', u'together', u',', u'And', u'choake', u'their', u'Art', u':', u'The', u'mercilesse', u'Macdonwald', u'(', u'Worthie', u'to', u'be', u'a', u'Rebell', u',', u'for', u'to', u'that', u'The', u'multiplying', u'Villanies', u'of', u'Nature', u'Doe', u'swarme', u'vpon', u'him', u')', u'from', u'the', u'Westerne', u'Isles', u'Of', u'Kernes', u'and', u'Gallowgrosses', u'is', u'supply', u"'", u'd', u',', u'And', u'Fortune', u'on', u'his', u'damned', u'Quarry', u'smiling', u',', u'Shew', u"'", u'd', u'like', u'a', u'Rebells', u'Whore', u':', u'but', u'all', u"'", u's', u'too', u'weake', u':', u'For', u'braue', u'Macbeth', u'(', u'well', u'hee', u'deserues', u'that', u'Name', u')', u'Disdayning', u'Fortune', u',', u'with', u'his', u'brandisht', u'Steele', u',', u'Which', u'smoak', u"'", u'd', u'with', u'bloody', u'execution', u'(', u'Like', u'Valours', u'Minion', u')', u'caru', u"'", u'd', u'out', u'his', u'passage', u',', u'Till', u'hee', u'fac', u"'", u'd', u'the', u'Slaue', u':', u'Which', u'neu', u"'", u'r', u'shooke', u'hands', u',', u'nor', u'bad', u'farwell', u'to', u'him', u',', u'Till', u'he', u'vnseam', u"'", u'd', u'him', u'from', u'the', u'Naue', u'toth', u"'", u'Chops', u',', u'And', u'fix', u"'", u'd', u'his', u'Head', u'vpon', u'our', u'Battlements']] # 網路和聊天文字 from nltk.corpus import webtext for fileid in webtext.fileids(): print fileid,webtext.raw(fileid)[:50] firefox.txt Cookie Manager: "Don't allow sites that set remove grail.txt SCENE 1: [wind] [clop clop clop] KING ARTHUR: Who overheard.txt White guy: So, do you have any plans for this even pirates.txt PIRATES OF THE CARRIBEAN: DEAD MAN'S CHEST, by Ted singles.txt 25 SEXY MALE, seeks attrac older single lady, for wine.txt Lovely delicate, fragrant Rhone wine. Polished lea
from nltk.corpus import brown brown.categories() Out[97]: [u'adventure', u'belles_lettres', u'editorial', u'fiction', u'government', u'hobbies', u'humor', u'learned', u'lore', u'mystery', u'news', u'religion', u'reviews', u'romance', u'science_fiction'] brown.words(categories = 'news') Out[98]: [u'The', u'Fulton', u'County', u'Grand', u'Jury', ...] brown.words(fileids = ['cg22']) Out[99]: [u'Does', u'our', u'society', u'have', u'a', ...] brown.words(categories = ['new', 'editorial', 'reviews']) Out[100]: [u'Assembly', u'session', u'brought', u'much', u'good', ...] #比較不同文體中的情態動詞用法,第一步產生特定的文體計數 news_text = brown.words(categories = 'news') fdist = nltk.FreqDist([w.lower() for w in news_text]) modals = ['can', 'could', 'may', 'might', 'must', 'will'] for m in modals: print m+':',fdist[m] In can: 94[106]: could: 87 may: 93 might: 38 must: 53 will: 389 >>> import nltk >>> from nltk.corpus import brown >>> cfd = nltk.ConditionalFreqDist((genre, word) for genre in brown.categories() for word in brown.words(categories = genre)) >>> genres = ['news', 'religion', 'hobbies', 'science_fiction', 'romance', 'humor'] >>> modals = ['can', 'could', 'may', 'might', 'must', 'will'] >>> cfd.tabulate(conditions=genres, samples=modals) can could may might must will news 93 86 66 38 50 389 religion 82 59 78 12 54 71 hobbies 268 58 131 22 83 264 science_fiction 16 49 4 12 8 16 romance 74 193 11 51 45 43 humor 16 30 8 8 9 13 >>> cfd.plot(conditions=genres, samples=modals)
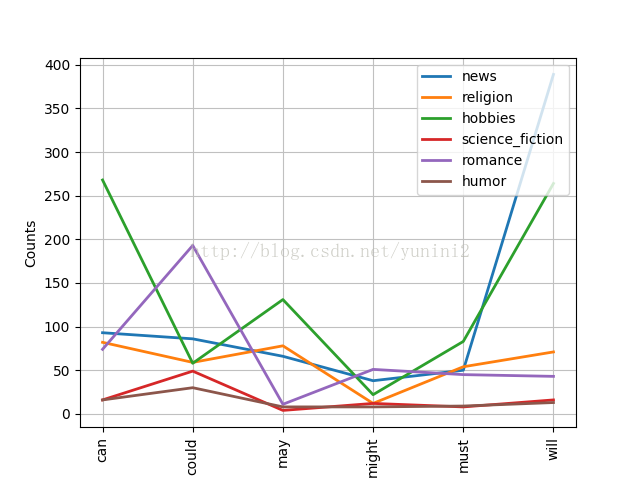
路透社語義庫
就職演說語料庫#路透社語料庫 from nltk.corpus import reuters reuters.fileids()# 包含10788個新聞文件,共計130萬字 reuters.categories()# 90個主題,分為訓練和測試 reuters.categories('training/9865') Out[128]: [u'barley', u'corn', u'grain', u'wheat'] reuters.categories('training/9865') Out[128]: [u'barley', u'corn', u'grain', u'wheat'] reuters.categories(['training/9865', 'training/9880']) Out[129]: [u'barley', u'corn', u'grain', u'money-fx', u'wheat'] reuters.fileids('barley') Out[130]: [u'test/15618', u'test/15649', u'test/15676', u'test/15728', u'test/15871', u'test/15875', u'test/15952', u'test/17767', u'test/17769', u'test/18024', u'test/18263', u'test/18908', u'test/19275', u'test/19668', u'training/10175', u'training/1067', u'training/11208', u'training/11316', u'training/11885', u'training/12428', u'training/13099', u'training/13744', u'training/13795', u'training/13852', u'training/13856', u'training/1652', u'training/1970', u'training/2044', u'training/2171', u'training/2172', u'training/2191', u'training/2217', u'training/2232', u'training/3132', u'training/3324', u'training/395', u'training/4280', u'training/4296', u'training/5', u'training/501', u'training/5467', u'training/5610', u'training/5640', u'training/6626', u'training/7205', u'training/7579', u'training/8213', u'training/8257', u'training/8759', u'training/9865', u'training/9958'] reuters.fileids(['barley','corn']) Out[131]: [u'test/14832', u'test/14858', u'test/15033', u'test/15043', u'test/15106', u'test/15287', u'test/15341', u'test/15618', u'test/15648', u'test/15649', u'test/15676', u'test/15686', u'test/15720', u'test/15728', u'test/15845', u'test/15856', u'test/15860', u'test/15863', u'test/15871', u'test/15875', u'test/15877', u'test/15890', u'test/15904', u'test/15906', u'test/15910', u'test/15911', u'test/15917', u'test/15952', u'test/15999', u'test/16012', u'test/16071', u'test/16099', u'test/16147', u'test/16525', u'test/16624', u'test/16751', u'test/16765', u'test/17503', u'test/17509', u'test/17722', u'test/17767', u'test/17769', u'test/18024', u'test/18035', u'test/18263', u'test/18482', u'test/18614', u'test/18908', u'test/18954', u'test/18973', u'test/19165', u'test/19275', u'test/19668', u'test/19721', u'test/19821', u'test/20018', u'test/20366', u'test/20637', u'test/20645', u'test/20649', u'test/20723', u'test/20763', u'test/21091', u'test/21243', u'test/21493', u'training/10120', u'training/10139', u'training/10172', u'training/10175', u'training/10319', u'training/10339', u'training/10487', u'training/10489', u'training/10519', u'training/1067', u'training/10701', u'training/10882', u'training/10956', u'training/11012', u'training/11085', u'training/11091', u'training/11208', u'training/11269', u'training/1131', u'training/11316', u'training/11392', u'training/11436', u'training/11607', u'training/11612', u'training/11729', u'training/11739', u'training/11769', u'training/11885', u'training/11936', u'training/11939', u'training/11964', u'training/12002', u'training/12052', u'training/12055', u'training/1215', u'training/12160', u'training/12311', u'training/12323', u'training/12372', u'training/12417', u'training/12428', u'training/12436', u'training/12500', u'training/12583', u'training/12587', u'training/1268', u'training/1273', u'training/12872', u'training/13099', u'training/13173', u'training/13179', u'training/1369', u'training/13744', u'training/13795', u'training/1385', u'training/13852', u'training/13856', u'training/1395', u'training/1399', u'training/14483', u'training/1582', u'training/1652', u'training/1777', u'training/1843', u'training/193', u'training/1952', u'training/197', u'training/1970', u'training/2044', u'training/2171', u'training/2172', u'training/2183', u'training/2191', u'training/2217', u'training/2232', u'training/2264', u'training/235', u'training/2382', u'training/2436', u'training/2456', u'training/2595', u'training/2599', u'training/2617', u'training/2727', u'training/2741', u'training/2749', u'training/2777', u'training/2848', u'training/2913', u'training/2922', u'training/2947', u'training/3132', u'training/3138', u'training/3191', u'training/327', u'training/3282', u'training/3299', u'training/3306', u'training/3324', u'training/3330', u'training/3337', u'training/3358', u'training/3401', u'training/3429', u'training/3847', u'training/3855', u'training/3881', u'training/3949', u'training/395', u'training/3979', u'training/3981', u'training/4047', u'training/4133', u'training/4280', u'training/4289', u'training/4296', u'training/4382', u'training/4490', u'training/4599', u'training/4825', u'training/4905', u'training/4939', u'training/4988', u'training/5', u'training/5003', u'training/501', u'training/5017', u'training/5033', u'training/5109', u'training/516', u'training/5185', u'training/5338', u'training/5467', u'training/5518', u'training/5531', u'training/5606', u'training/5610', u'training/5636', u'training/5637', u'training/5640', u'training/57', u'training/5847', u'training/5933', u'training/6', u'training/6142', u'training/6221', u'training/6236', u'training/6239', u'training/6259', u'training/6269', u'training/6386', u'training/6585', u'training/6588', u'training/6626', u'training/6735', u'training/6890', u'training/6897', u'training/694', u'training/7062', u'training/7205', u'training/7215', u'training/7336', u'training/7387', u'training/7389', u'training/7390', u'training/7395', u'training/7579', u'training/7700', u'training/7792', u'training/7917', u'training/7934', u'training/7943', u'training/8004', u'training/8140', u'training/8161', u'training/8166', u'training/8213', u'training/8257', u'training/8273', u'training/8400', u'training/8443', u'training/8446', u'training/8535', u'training/855', u'training/8759', u'training/8941', u'training/8983', u'training/8993', u'training/9058', u'training/9093', u'training/9094', u'training/934', u'training/9470', u'training/9521', u'training/9667', u'training/97', u'training/9865', u'training/9958', u'training/9989'] reuters.words('training/9865')[:10] Out[132]: [u'FRENCH', u'FREE', u'MARKET', u'CEREAL', u'EXPORT', u'BIDS', u'DETAILED', u'French', u'operators', u'have']
#就職演說語料庫
from nltk.corpus import inaugural
inaugural.fileids()# 包含55個文字,每個文字是一個總統的演講
[fileid[:4] for fileid in inaugural.fileids()]# 提取前4個字元為年份
#將詞彙轉成小寫,用startwith()檢驗是否從目標詞彙america或citizen開始
cdf = nltk.ConditionalFreqDist(
(target,fileid[:4])
for fileid in inaugural.fileids()
for w in inaugural.words(fileid)
for target in ['america', 'citizen']
if w.lower().startswith(target)
)
cdf.plot()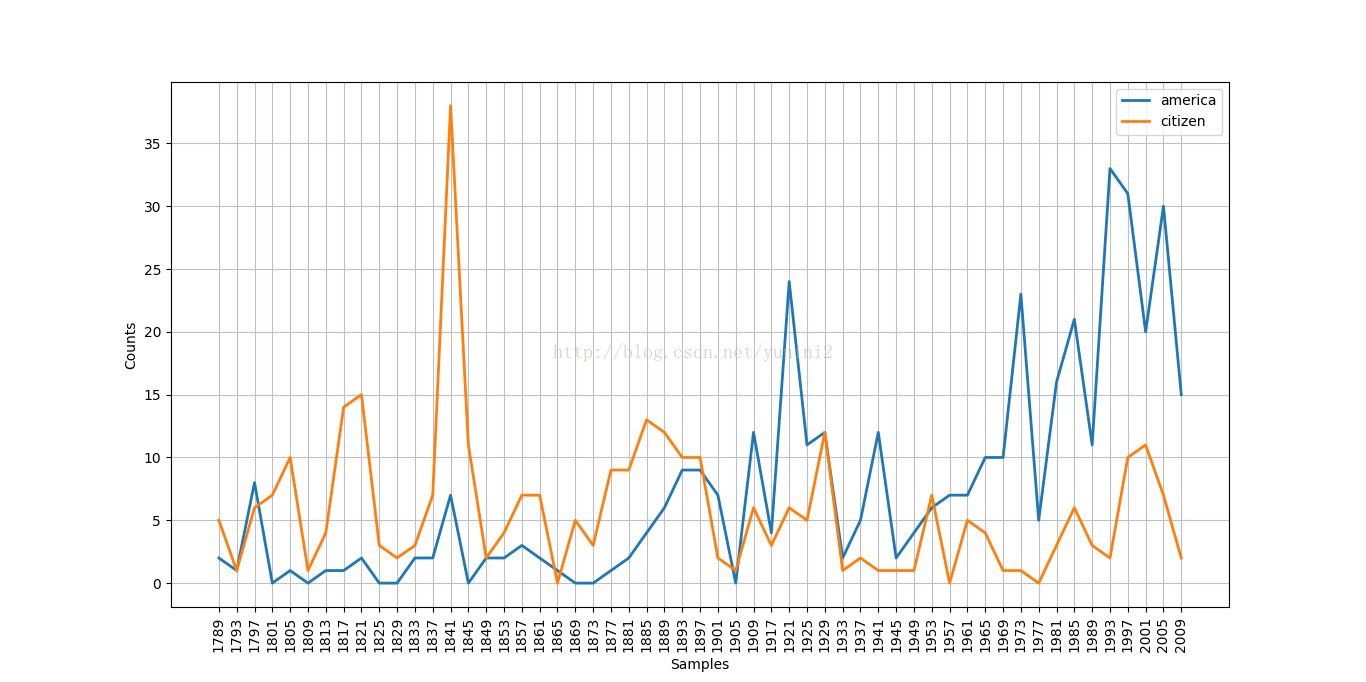
標註文字語料庫。。。。
其他語料庫。。。
載入自己的語料庫【不明白為什麼中文出不來啊!!!!!!!!!!!!!!!!!!!!!!!】
from nltk.corpus import PlaintextCorpusReader
corpus_root = r'e:\myyuliaoku'
file_pattern = r'.*\.txt'
wordlists = PlaintextCorpusReader(corpus_root, file_pattern)
wordlists.fileids()
wordlists.raw('laojiumenciku.txt')
words = wordlists.words()
words[:20]
nltk.FreqDist(wordlists.words("laojiumenciku.txt")).plot()# 不明白為什麼中文出不來,txt文件編碼已經改為utf-8
len(wordlists.sents())
from nltk.corpus import BracketParseCorpusReader
corpus_root = r'e:\myyuliaoku'
file_pattern = r'.*\.txt'
ptb = BracketParseCorpusReader(corpus_root, file_pattern,encoding = 'UTF-8') #初始化讀取器:語料庫目錄和要載入檔案的格式,預設utf8格式的編碼
ptb.fileids() #至此,可以看到目錄下的所有檔名,例如C000008/1001.txt,則成功了
ptb.raw("laojiumenciku.txt")