
5類系統推薦演算法,非常好使,非常全
◆ ◆ ◆
序言
最近因為PAC平臺自動化的需求,開始探坑推薦系統。這個乍一聽去樂趣無窮的課題,對於演算法大神們來說是這樣的:

而對於剛接觸這個領域的我來說,是這樣的:

在深坑外圍徘徊了一週後,我整理了一些推薦系統的基本概念以及一些有代表性的簡單的演算法,作為初探總結,也希望能拋磚引玉,給同樣想入坑的夥伴們提供一些思路。
◆ ◆ ◆
什麼是推薦系統
1. 什麼是推薦系統?
推薦系統是啥?
如果你是個多年電商(剁手)黨,你會說是這個:
如果你是名充滿文藝細胞的音樂發燒友,你會答這個:
如果你是位活躍在各大社交平臺的點贊狂魔,你會答這個:
沒錯,猜你喜歡、個性歌單、熱點微博,這些都是推薦系統的輸出內容。從這些我們就可以總結出,推薦系統到底是做什麼的。
目的1. 幫助使用者找到想要的商品(新聞/音樂/……),發掘長尾
幫使用者找到想要的東西,談何容易。商品茫茫多,甚至是我們自己,也經常點開淘寶,面對眼花繚亂的打折活動不知道要買啥。在經濟學中,有一個著名理論叫長尾理論(The Long Tail)。
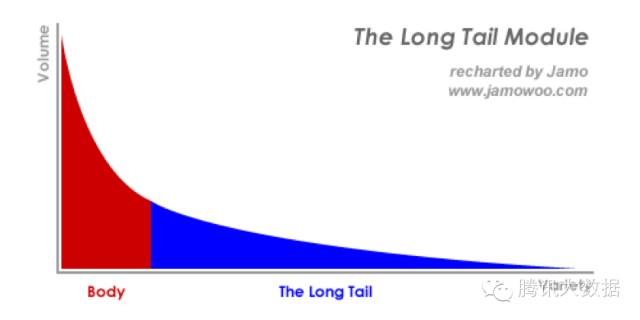
套用在網際網路領域中,指的就是最熱的那一小部分資源將得到絕大部分的關注,而剩下的很大一部分資源卻鮮少有人問津。這不僅造成了資源利用上的浪費,也讓很多口味偏小眾的使用者無法找到自己感興趣的內容。
目的2. 降低資訊過載
網際網路時代資訊量已然處於爆炸狀態,若是將所有內容都放在網站首頁上使用者是無從閱讀的,資訊的利用率將會十分低下。因此我們需要推薦系統來幫助使用者過濾掉低價值的資訊。
目的3. 提高站點的點選率/轉化率
好的推薦系統能讓使用者更頻繁地訪問一個站點,並且總是能為使用者找到他想要購買的商品或者閱讀的內容。
目的4. 加深對使用者的瞭解,為使用者提供定製化服務
可以想見,每當系統成功推薦了一個使用者感興趣的內容後,我們對該使用者的興趣愛好等維度上的形象是越來越清晰的。當我們能夠精確描繪出每個使用者的形象之後,就可以為他們定製一系列服務,讓擁有各種需求的使用者都能在我們的平臺上得到滿足。
◆ ◆ ◆
推薦演算法
演算法是什麼?我們可以把它簡化為一個函式。函式接受若干個引數,輸出一個返回值。
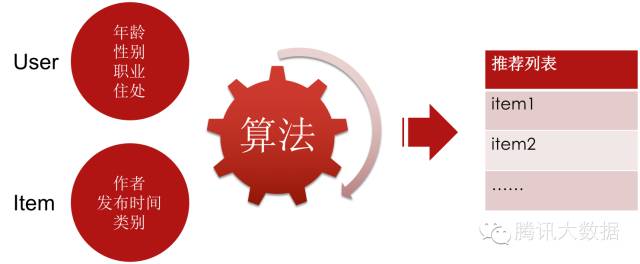
演算法如上圖,輸入引數是使用者和item的各種屬性和特徵,包括年齡、性別、地域、商品的類別、釋出時間等等。經過推薦演算法處理後,返回一個按照使用者喜好度排序的item列表。
推薦演算法大致可以分為以下幾類[1]:
-
基於流行度的演算法
-
協同過濾演算法
-
基於內容的演算法
-
基於模型的演算法
-
混合演算法
2.1 基於流行度的演算法
基於流行度的演算法非常簡單粗暴,類似於各大新聞、微博熱榜等,根據PV、UV、日均PV或分享率等資料來按某種熱度排序來推薦給使用者。

這種演算法的優點是簡單,適用於剛註冊的新使用者。缺點也很明顯,它無法針對使用者提供個性化的推薦。基於這種演算法也可做一些優化,比如加入使用者分群的流行度排序,例如把熱榜上的體育內容優先推薦給體育迷,把政要熱文推給熱愛談論政治的使用者。
2.2 協同過濾演算法
協同過濾演算法(Collaborative Filtering, CF)是很常用的一種演算法,在很多電商網站上都有用到。CF演算法包括基於使用者的CF(User-based CF)和基於物品的CF(Item-based CF)。
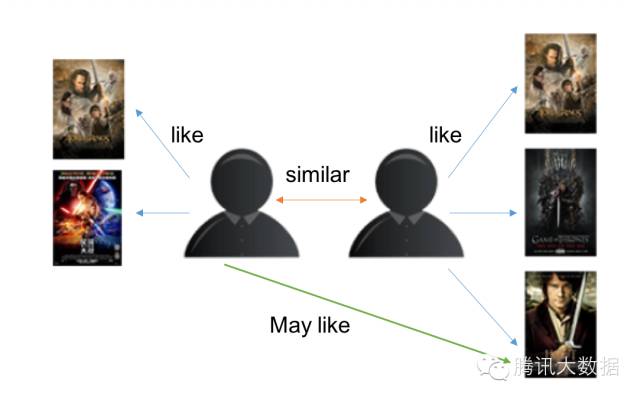
基於使用者的CF原理如下:
-
分析各個使用者對item的評價(通過瀏覽記錄、購買記錄等);
-
依據使用者對item的評價計算得出所有使用者之間的相似度;
-
選出與當前使用者最相似的N個使用者;
-
將這N個使用者評價最高並且當前使用者又沒有瀏覽過的item推薦給當前使用者。
示意圖如下:
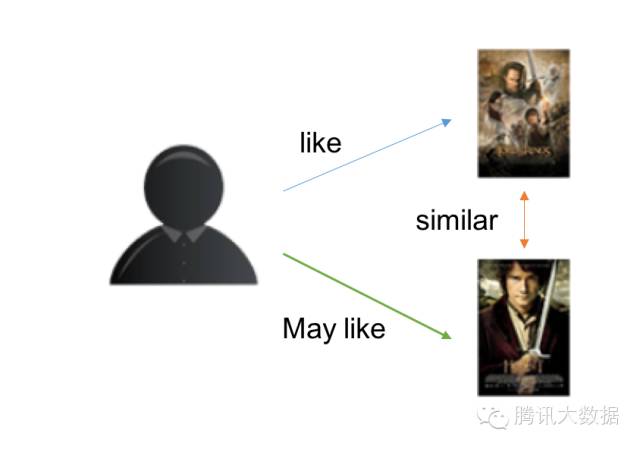
基於物品的CF原理大同小異,只是主體在於物品:
-
分析各個使用者對item的瀏覽記錄。
-
依據瀏覽記錄分析得出所有item之間的相似度;
-
對於當前使用者評價高的item,找出與之相似度最高的N個item;
-
將這N個item推薦給使用者。
示意圖如下:
舉個栗子,基於使用者的CF演算法大致的計算流程如下:
首先我們根據網站的記錄計算出一個使用者與item的關聯矩陣,如下:
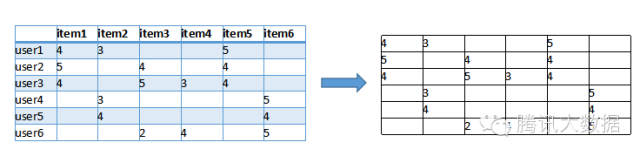
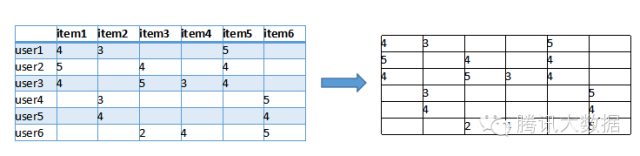
圖中,行是不同的使用者,列是所有物品,(x, y)的值則是x使用者對y物品的評分(喜好程度)。我們可以把每一行視為一個使用者對物品偏好的向量,然後計算每兩個使用者之間的向量距離,這裡我們用餘弦相似度來算:
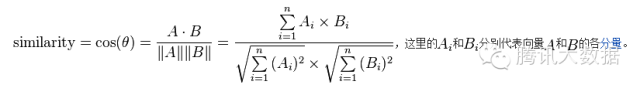
然後得出使用者向量之間相似度如下,其中值越接近1表示這兩個使用者越相似:
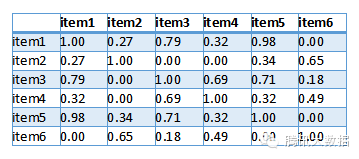
最後,我們要為使用者1推薦物品,則找出與使用者1相似度最高的N名使用者(設N=2)評價的物品,去掉使用者1評價過的物品,則是推薦結果。
基於物品的CF計算方式大致相同,只是關聯矩陣變為了item和item之間的關係,若使用者同時瀏覽過item1和item2,則(1,1)的值為1,最後計算出所有item之間的關聯關係如下:

我們可以看到,CF演算法確實簡單,而且很多時候推薦也是很準確的。然而它也存在一些問題:
-
依賴於準確的使用者評分;
-
在計算的過程中,那些大熱的物品會有更大的機率被推薦給使用者;
-
冷啟動問題。當有一名新使用者或者新物品進入系統時,推薦將無從依據;
-
在一些item生存週期短(如新聞、廣告)的系統中,由於更新速度快,大量item不會有使用者評分,造成評分矩陣稀疏,不利於這些內容的推薦。
對於矩陣稀疏的問題,有很多方法來改進CF演算法。比如通過矩陣因子分解(如LFM),我們可以把一個nm的矩陣分解為一個nk的矩陣乘以一個k*m的矩陣,如下圖:

這裡的k可以是使用者的特徵、興趣愛好與物品屬性的一些聯絡,通過因子分解,可以找到使用者和物品之間的一些潛在關聯,從而填補之前矩陣中的缺失值。
2.3 基於內容的演算法
CF演算法看起來很好很強大,通過改進也能克服各種缺點。那麼問題來了,假如我是個《指環王》的忠實讀者,我買過一本《雙塔奇兵》,這時庫裡新進了第三部:《王者歸來》,那麼顯然我會很感興趣。然而基於之前的演算法,無論是使用者評分還是書名的檢索都不太好使,於是基於內容的推薦演算法呼之欲出。
舉個栗子,現在系統裡有一個使用者和一條新聞。通過分析使用者的行為以及新聞的文字內容,我們提取出數個關鍵字,如下圖:
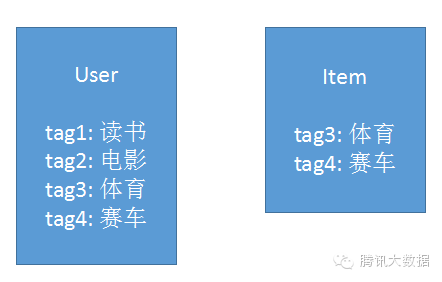
將這些關鍵字作為屬性,把使用者和新聞分解成向量,如下圖:
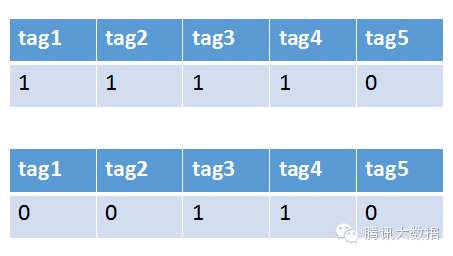
之後再計算向量距離,便可以得出該使用者和新聞的相似度了。這種方法很簡單,如果在為一名熱愛觀看英超聯賽的足球迷推薦新聞時,新聞裡同時存在關鍵字型育、足球、英超,顯然匹配前兩個詞都不如直接匹配英超來得準確,系統該如何體現出關鍵詞的這種“重要性”呢?這時我們便可以引入詞權的概念。在大量的語料庫中通過計算(比如典型的TF-IDF演算法),我們可以算出新聞中每一個關鍵詞的權重,在計算相似度時引入這個權重的影響,就可以達到更精確的效果。
sim(user, item) = 文字相似度(user, item) * 詞權
然而,經常接觸體育新聞方面資料的同學就會要提出問題了:要是使用者的興趣是足球,而新聞的關鍵詞是德甲、英超,按照上面的文字匹配方法顯然無法將他們關聯到一起。在此,我們可以引用話題聚類:
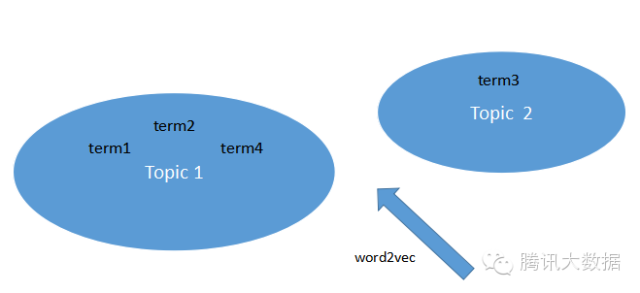
利用word2vec一類工具,可以將文字的關鍵詞聚類,然後根據topic將文字向量化。如可以將德甲、英超、西甲聚類到“足球”的topic下,將lv、Gucci聚類到“奢侈品”topic下,再根據topic為文字內容與使用者作相似度計算。
綜上,基於內容的推薦演算法能夠很好地解決冷啟動問題,並且也不會囿於熱度的限制,因為它是直接基於內容匹配的,而與瀏覽記錄無關。然而它也會存在一些弊端,比如過度專業化(over-specialisation)的問題。這種方法會一直推薦給使用者內容密切關聯的item,而失去了推薦內容的多樣性。
2.4 基於模型的演算法
基於模型的方法有很多,用到的諸如機器學習的方法也可以很深,這裡只簡單介紹下比較簡單的方法——Logistics迴歸預測。我們通過分析系統中使用者的行為和購買記錄等資料,得到如下表:
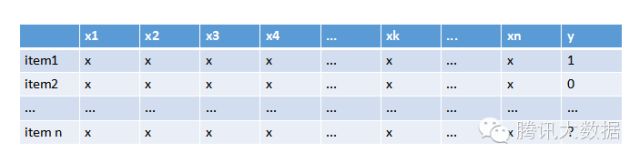
表中的行是一種物品,x1~xn是影響使用者行為的各種特徵屬性,如使用者年齡段、性別、地域、物品的價格、類別等等,y則是使用者對於該物品的喜好程度,可以是購買記錄、瀏覽、收藏等等。通過大量這類的資料,我們可以迴歸擬合出一個函式,計算出x1~xn對應的係數,這即是各特徵屬性對應的權重,權重值越大則表明該屬性對於使用者選擇商品越重要。
在擬合函式的時候我們會想到,單一的某種屬性和另一種屬性可能並不存在強關聯。比如,年齡與購買護膚品這個行為並不呈強關聯,性別與購買護膚品也不強關聯,但當我們把年齡與性別綜合在一起考慮時,它們便和購買行為產生了強關聯。比如(我只是比如),20~30歲的女性使用者更傾向於購買護膚品,這就叫交叉屬性。通過反覆測試和經驗,我們可以調整特徵屬性的組合,擬合出最準確的迴歸函式。最後得出的屬性權重如下:
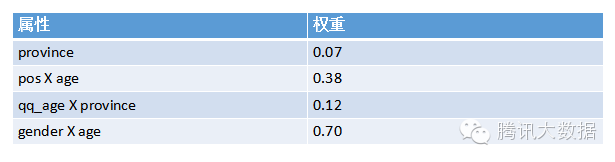
基於模型的演算法由於快速、準確,適用於實時性比較高的業務如新聞、廣告等,而若是需要這種演算法達到更好的效果,則需要人工干預反覆的進行屬性的組合和篩選,也就是常說的Feature Engineering。而由於新聞的時效性,系統也需要反覆更新線上的數學模型,以適應變化。
2.5 混合演算法
現實應用中,其實很少有直接用某種演算法來做推薦的系統。在一些大的網站如Netflix,就是融合了數十種演算法的推薦系統。我們可以通過給不同演算法的結果加權重來綜合結果,或者是在不同的計算環節中運用不同的演算法來混合,達到更貼合自己業務的目的。
2.6 結果列表
在演算法最後得出推薦結果之後,我們往往還需要對結果進行處理。比如當推薦的內容裡包含敏感詞彙、涉及使用者隱私的內容等等,就需要系統將其篩除;若數次推薦後用戶依然對某個item毫無興趣,我們就需要將這個item降低權重,調整排序;另外,有時系統還要考慮話題多樣性的問題,同樣要在不同話題中篩選內容。
◆ ◆ ◆
推薦結果評估
當推薦演算法完成後,怎樣來評估這個演算法的效果?CTR(點選率)、CVR(轉化率)、停留時間等都是很直觀的資料。在完成演算法後,可以通過線下計算演算法的RMSE(均方根誤差)或者線上進行ABTest來對比效果。
◆ ◆ ◆
改進策略
使用者畫像是最近經常被提及的一個名詞,引入使用者畫像可以為推薦系統帶來很多改進的餘地,比如:
-
打通公司各大業務平臺,通過獲取其他平臺的使用者資料,徹底解決冷啟動問題;
-
在不同裝置上同步使用者資料,包括QQID、裝置號、手機號等;
-
豐富使用者的人口屬性,包括年齡、職業、地域等;
-
更完善的使用者興趣狀態,方便生成使用者標籤和匹配內容。
另外,公司的優勢——社交平臺也是一個很好利用的地方。利用使用者的社交網路,可以很方便地通過使用者的好友、興趣群的成員等更快捷地找到相似使用者以及使用者可能感興趣的內容,提高推薦的準確度。
◆ ◆ ◆
總結
隨著大資料和機器學習的火熱,推薦系統也將愈發成熟,需要學習的地方還有很多,坑還有很深,希望有志的同學共勉~