
c++ primer 第五版學習筆記-第三章 字串、向量和陣列
本文為轉載,出處:https://blog.csdn.net/libin1105/article/details/48210261
https://blog.csdn.net/fnoi2014xtx/article/details/78152884
3.1 名稱空間using宣告
1.有了using宣告就無須專門的字首(形如名稱空間::)也能使用所需的名字了。using宣告具有如下的形式:
using namespace::name;
一旦聲明瞭上述語句,就可以直接訪問名稱空間中的名字。
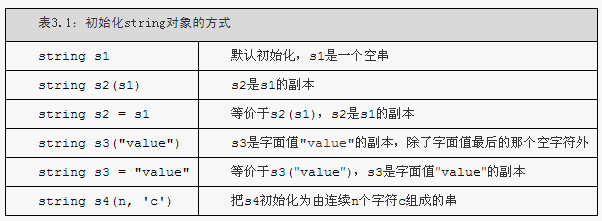
3.2 標準庫型別string
1.標準庫型別string表示可變長的字元序列,使用string型別必須首先包含string標頭檔案。作為標準庫的一部分,string定義在名稱空間std中。
2.
<span style="color: rgb(64, 70, 76); font-family: 'Open Sans', 'Helvetica Neue', Helvetica, Arial, STHeiti, 'Microsoft Yahei', sans-serif; font-size: 14px; line-height: 22.399999618530273px; background-color: rgb(253, 254, 249);">讀取未知數量的string物件</span><pre name="code" class="cpp"><pre name="code" class="cpp">#include <iostream> #include <string> using std::cin; using std::cout; using std::endl;; using std::string;<pre name="code" class="cpp"> int main() { string str; // 逐個讀取單詞,直到檔案末尾 while (cin >> str) { // 逐行讀取,保留輸入的空格:while (getline(str)) cout << str << endl; } return 0; }
std::string s;
(1)cin讀入string,從非空白字元讀到第一個空白符之前
(2)getline(cin,s)讀入換行符,但不儲存換行符,讀入失敗返回0
(3)s.size()返回的值為string::size_type型別,這是一個無符號整數,所以注意不要混用size_type與有符號整數
(4)字串字面值不能相加,string與自己、字面值可以相加(相連)
當把string物件和字元字面值,字串字面值混合在一個語句中時候,必須保證每個加法運算子(+)的兩側必須有一個是
string物件
string a(10,'c');
string b=a+"bb"+"aaa";//正確 a+字面值“bb”是string物件 3.如果使用等號(=)初始化一個變數,實際上執行的是拷貝初始化(copy initialization),編譯器把等號右側的初始值拷貝到新建立的物件中去。與之相反,如果不使用等號,則執行的是直接初始化(direct initialization)。
4.

5.有時我們希望能在最終得到的字串中保留輸入時的空白符,這時應該用getline函式代替原來的>>運算子。getline函式的引數是一個輸入流和一個string物件,函式從給定的輸入流中讀入內容,直到遇到換行符為止(注意換行符也被讀進來了),然後把所讀的內容存入到那個string物件中去(注意不存換行符)。getline只要一遇到換行符就結束讀取操作並返回結果,哪怕輸入的一開始就是換行符也是如此。如果輸入真的一開始就是換行符,那麼所得的結果是個空string。
6.相等性運算子(==和!=)分別檢驗兩個string物件相等或不相等,string物件相等意味著它們的長度相同而且所包含的字元也全都相同。關係運算符<、<=、>、>=分別檢驗一個string物件是否小於、小於等於、大於、大於等於另外一個string物件。上述這些運算子都依照(大小寫敏感的)字典順序:
1.如果兩個string物件的長度不同,而且較短string物件的每個字元都與較長string物件對應位置上的字元相同,就說較短string物件小於較長string物件。
2.如果兩個string物件在某些對應的位置上不一致,則string物件比較的結果其實是string物件中第一對相異字元比較的結果。
7.

8.如果想對string物件中的每個字元做點兒什麼操作,目前最好的辦法是使用C++11新標準提供的一種語句:範圍for(range for)語句。這種語句遍歷給定序列中的每個元素並對序列中的每個值執行某種操作,其語法形式是:
for (declaration : expression)
statement其中,expression部分是一個物件,用於表示一個序列。declaration部分負責定義一個變數,該變數將被用於訪問序列中的基礎元素。每次迭代,declaration部分的變數會被初始化為expression部分的下一個元素值。
for迴圈遍歷std::string
std::string s;
for(auto c : s)cout<<c;//只訪問s中的每個字元
for(auto &c : s)c=tolower(c);//訪問與修改s中的每個字元
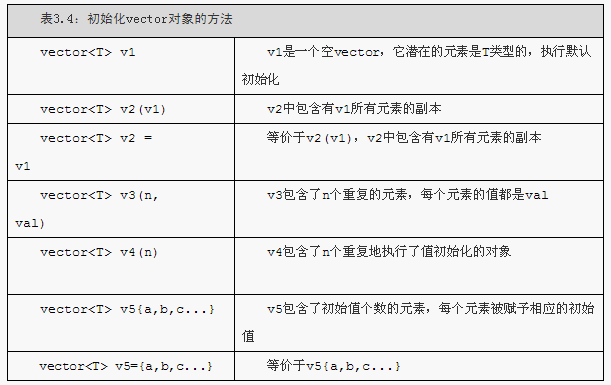
//auto可以用char代替3.3 標準庫型別vector
1.標準庫型別vector表示物件的集合,其中所有物件的型別都相同。集合中的每個物件都有一個與之對應的索引,索引用於訪問物件。因為vector"容納著"其他物件,所以它也常被稱作容器(container)。
std::vector v;
(1)不存在包含引用的vector
(2)初始元素值列表
vector<string> v1{"a","b","c"};//正確
vector<string> v2("a","b","c");//錯誤- 1
- 2
(3)初始元素數量
vector<int> v1(10);//初始10個元素,預設為0
vector<int> v2(10,1);//初始10個元素,預設為1
//{}會盡可能嘗試元素值列表,否則構造
vector<int> v3{10,1};//10,1
vector<string> v4{10,"a"};//a,a,a,a,a,a,a,a,a,a2.
3.push_back負責把一個值當成vector物件的尾元素"壓到(push)"vector物件的"尾端(back)"。例如:
vector<int> v2; // 空vector物件
for (int i = 0; i != 100; ++i)
v2.push_back(i); // 依次把整數值放到v2尾端
// 迴圈結束後v2有100個元素,值從0到99
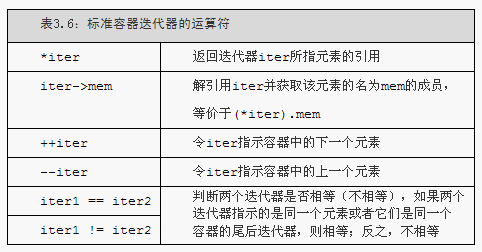
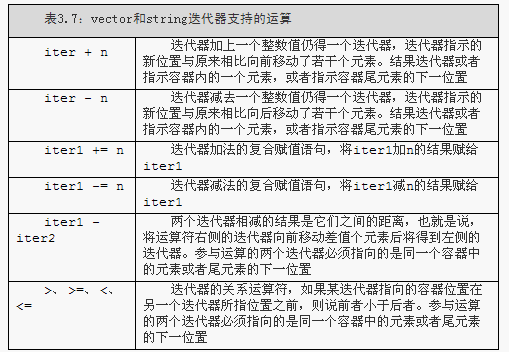
3.4 迭代器介紹
1.和指標不一樣的是,獲取迭代器不是使用取地址符,有迭代器的型別同時擁有返回迭代器的成員。比如,這些型別都擁有名為begin和end的成員,其中begin成員負責返回指向第一個元素(或第一個字元)的迭代器。
// 由編譯器決定b和e的型別;參見2.5.2節(第68頁)
// b表示v的第一個元素,e表示v尾元素的下一位置
auto b = v.begin(), e = v.end(); //b 和e的型別相同如果容器為空,則begin和end返回的是同一個迭代器,都是尾後迭代器。
2.
3.const_iterator和常量指標差不多,能讀取但不能修改它所指的元素值。相反,iterator的物件可讀可寫。如果vector物件或string物件是一個常量,只能使用const_iterator;如果vector物件或string物件不是常量,那麼既能使用iterator也能使用const_iterator。
(1)const_iterator std::vector<int>::const_iterator it只能讀,不能修改
(2)const與容器
vector<int> v;
const vector<int>cv;
auto it=cv.begin()//const_iterator
auto it2=v.cbegin();//cbegin()與cend():const_iterator4.begin和end返回的具體型別由物件是否是常量決定,如果物件是常量,begin和end返回const_iterator;如果物件不是常量,返回iterator。
cbegin和cend也分別返回指示容器第一個元素或最後元素下一位置的迭代器。有所不同的是,不論vector物件(或string物件)本身是否是常量,返回值都是const_iterator。
5.
3.5 陣列
1.陣列是一種複合型別(參見2.3節,第50頁)。陣列的宣告形如a[d],其中a是陣列的名字,d是陣列的維度。維度說明了陣列中元素的個數,因此必須大於0。陣列中元素的個數也屬於陣列型別的一部分,編譯的時候維度應該是已知的。也就是說,維度必須是一個常量表達式。unsigned n=1024;int a[n];//錯誤,n不是常量表達式
2.定義陣列的時候必須指定陣列的型別,不允許用auto關鍵字由初始值的列表推斷型別。另外和vector一樣,陣列的元素應為物件,因此不存在引用的陣列。
3.可以對陣列的元素進行列表初始化,此時允許忽略陣列的維度。如果在宣告時沒有指明維度,編譯器會根據初始值的數量計算並推測出來;相反,如果指明瞭維度,那麼初始值的總數量不應該超出指定的大小。如果維度比提供的初始值數量大,則用提供的初始值初始化靠前的元素,剩下的元素被初始化成預設值。
4.
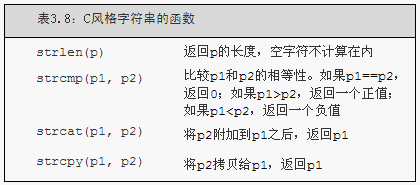
注意:if(s1<s2)比較的是指標s1與s2;s1+s2是將兩個地址相加
5.c_str函式的返回值是一個C風格的字串。也就是說,函式的返回結果是一個指標,該指標指向一個以空字元結束的字元陣列,而這個陣列所存的資料恰好與那個string物件的一樣。結果指標的型別是const char*,從而確保我們不會改變字元陣列的內容。
s.c_str():返回C風格字串的字元指標const char *,不保證一直有效
vector<int> v(begin(a),end(a)):C陣列初始化vector
int arr[]={0,1,2,3,4,5};
vector<int> vec(begin(arr),end(arr));
6.使用指標和陣列很容易出錯。一部分原因是概念上的問題:指標常用於底層操作,因此容易引發一些與煩瑣細節有關的錯誤。其他問題則源於語法錯誤,特別是宣告指標時的語法錯誤。
現代的C++程式應當儘量使用vector和迭代器,避免使用內建陣列和指標;應該儘量使用string,避免使用C風格的基於陣列的字串。
(1)字元陣列最後\0
(2)複雜陣列宣告
int *p[10];//含有10個整數指標的陣列
int (*p2)[10]=&arr;//p2指向一個含有10個整數的陣列
int (&Arr)[10]=arr;//Arr引用一個含有10個整數的陣列
int *(&ARR)[10]=p;//ARR引用一個含有10個整數指標的陣列- 1
- 2
- 3
- 4
(3)範圍for語句:for(auto a : arr)
(4)指標與陣列
int arr1={0,1,2,3};
auto arr2(arr1);//arr2:整數指標
int *p;
decltype(arr1) arr3={2,3,4,5};//arr3是一個數組
arr3=p;//錯誤!不能用整數指標給陣列賦值!- 1
- 2
- 3
- 4
- 5
- 6
陣列的頭尾指標:
#include <iterator>
int a[]={1,2,3,4};
int *s=begin(a),*t=end(a);- 1
- 2
- 3
注意:尾指標永遠不能做解引用與迭代
(5)陣列的大小是size_t型別,為無符號型別,陣列的指標作差是ptrdiff_t型別,為有符號型別,兩者均需使用標頭檔案cstddef
for(size_t i=0;i!=n;i++)a[i]++;- 1
(6)陣列的內建下標運算子是有符號型別,所以可以實現如下操作
int a[]={1,2,3,4,5,6,7,8}
int *b=&a[4];
int k=b[-2];//k==a[2]3.6 多維陣列
1.嚴格來說,C++語言中沒有多維陣列,通常所說的多維陣列其實是陣列的陣列。
2.要使用範圍for語句處理多維陣列,除了最內層的迴圈外,其他所有迴圈的控制變數都應該是引用型別。
int a[10][10];
for(auto &row : a)
for(auto &col : row)
//可修改
for(auto &row : a)
for(auto col : row)
//只讀
for(auto row : a)
for(auto col : row)
//錯誤!此時row的型別是int*!
using int_array int[10];
for(int_array *i=a; i!=a+10; i++)
for(int_array (*j)[10]=*i; j!=*i + 10; j++)
cout<<*j<<endl;//*j遍歷了a中的每一個元素