
Hadoop-2.8.4版本 分散式叢集搭建
Hadoop分散式叢集搭建
- 建立虛擬機器(用VmWare工具,centos6)
- 克隆三臺機器
master
slaver1
slaver2
- 分別在每臺機器上安裝jdk >= 1.7版本
vim /etc/profile

四、同步三臺虛擬機器的時間(時間同步)每臺機器都要做同樣的操作
1、yum install ntp
2、輸入“cp /usr/share/zoneinfo/Asia/Shanghai /etc/localtime”
3、輸入“ntpdate pool.ntp.org”
注意:如果電腦可以上網,但是虛擬機器不可以上網,可以如下操作
編輯 vim /etc/resolv.conf
新增如下兩行指令
nameserver 202.106.0.20
nameserver 8.8.8.8
- 設定主機名
10.1.13.103(IP號) 設定這臺機器的主機名為master
10.1.13.104(IP號) 設定這臺機器的主機名為slaver1
10.1.13.105(IP號) 設定這臺機器的主機名為slaver2
在10.1.13.103(IP號)機器上執行如下操作
- adduser master
- passwd master 提示輸入密碼和再次確定
- 修改主機名 vim /etc/sysconfig/network

- 給master使用者root許可權
chmod +w /etc/sudoers
vim /etc/sudoers

- 重啟虛擬機器,選擇master使用者登入
注意:另外兩臺機器也做同上的操作(名字分別為slaver1和slaver2)
- 修改主機對映(三臺機器都是一樣的操作)
- vim /etc/hosts
把hosts中的內容都刪除,然後新增如下

- 配置靜態ip
1、vim /etc/udev/rules.d/70**-net.rules

改完的效果

2、vim /etc/sysconfig/network-scripts/ifcfg-eth0
原來的樣子

修改後的樣子
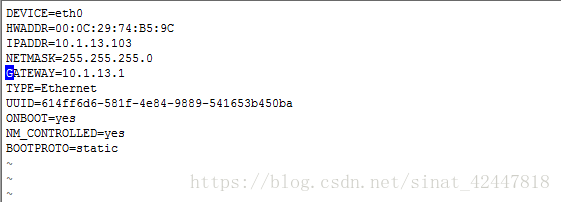
- 重啟網絡卡
service network restart
成功後,提示如下

- 剩下的兩臺機器,做同上操作(ip和mac地址是不一樣)
- 配置三臺機器之間的免密登入(必須在主機master上操作)
ssh-keygen -t rsa 然後四個回車
ssh-copy-id master 提示輸入密碼
ssh-copy-id slaver1 提示輸入密碼
ssh-copy-id slaver2 提示輸入密碼
測試: ssh slaver1 就不需要輸入密碼 然後在exit到當前使用者,可以執行下一次測試
- 下載hadoop壓縮包,解壓(以下的所有操作都在主機上 進行) 溫馨提示:最好在官網下載,src的原始碼,然後在自己的機器上編譯,這樣就不會出現找不到jar包的異常
- 把hadoop解壓到/usr/local/目錄下
tar -zxvf hadoop-2.8.4.tar.gz -C /usr/local
- 把hadoop-2.8.4改名為hadoop
進入到/usr/local/下執行
mv hadoop-2.8.4 hadoop
- 配置hadoop環境變數(也在主機下執行)
vim /etc/profile

立即讓配置檔案生效
source /etc/profile
此時,可以直接使用hadoop指令了
eg: hadoop version

- 關閉防火牆(三臺機器都要關閉)
service iptables status
service iptables stop(臨時關閉,不需要重啟虛擬機器)
chkconfig iptables off(永久關閉,需要重啟機器生效)
- 修改主機的配置檔案
進入到/uer/local/hadoop資料夾
然後mkdir namenode
mkdir datanode
mkdir tmp
進入到 /usr/loacal/hadoop/etc/hadoop檔案然後如下編輯
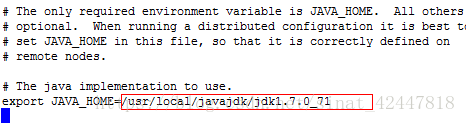
1、vim hadoop-env.sh
原來

該後
2、vim core-site.xml
在configuretion中新增
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/tmp</value>
</property>
效果

3、vim hdfs-site.xml
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:50090</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>/usr/local/hadoop/namenode</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>/usr/local/hadoop/datanode</value>
</property>
效果

4、vim mapred-site.xml(沒有mapred-site.xml但是有一個 mapred-site.xml.template
5、我們可以把名字改一下就可以了)
- mv mapred-site.xml.template mapred-site.xml
- vim mapred-site.xml 然後新增
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
效果

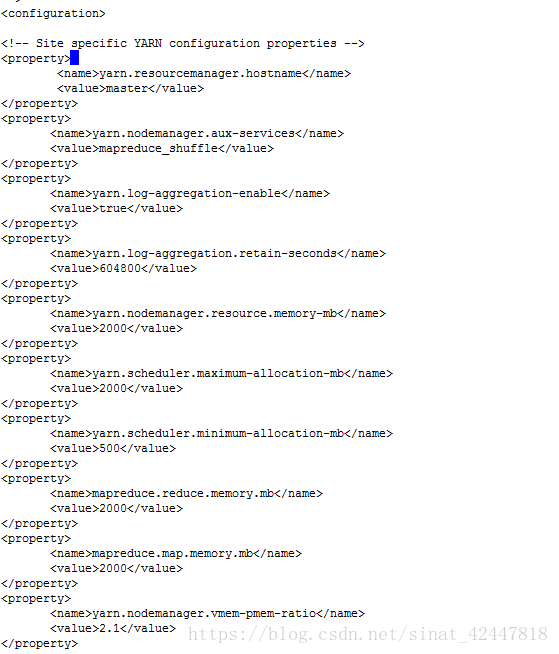
6、yarm-site.xml
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>2000</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>2000</value>
</property>
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>500</value>
</property>
<property>
<name>mapreduce.reduce.memory.mb</name>
<value>2000</value>
</property>
<property>
<name>mapreduce.map.memory.mb</name>
<value>2000</value>
</property>
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>2.1</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>hadoop1:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>hadoop1:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>hadoop1:8031</value>
</property>
效果

7、slaver
vim slavers
master
slaver1
slaver2
效果

- 下發配置檔案到分機上
下發hadoop到分機
- scp -r /usr/local/hadoop [email protected]:/usr/local/
- scp -r /usr/local/hadoop [email protected]:/usr/local/
下發環境變數配置檔案到分機
- scp -r /etc/profile [email protected]:/etc/
- scp -r /etc/profile [email protected]:/etc/
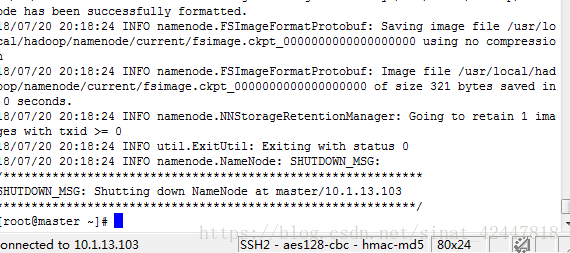
- 第一次執行的時候在主機下格式化namenode
hadoop namenode -format
格式化成功
- 啟動hadoop叢集
- start-all.sh
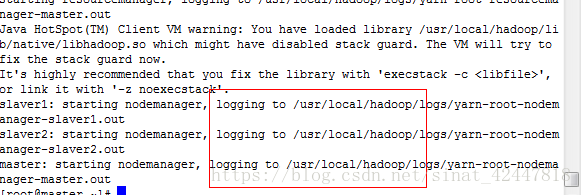
- 關閉叢集
- stop-all.sh
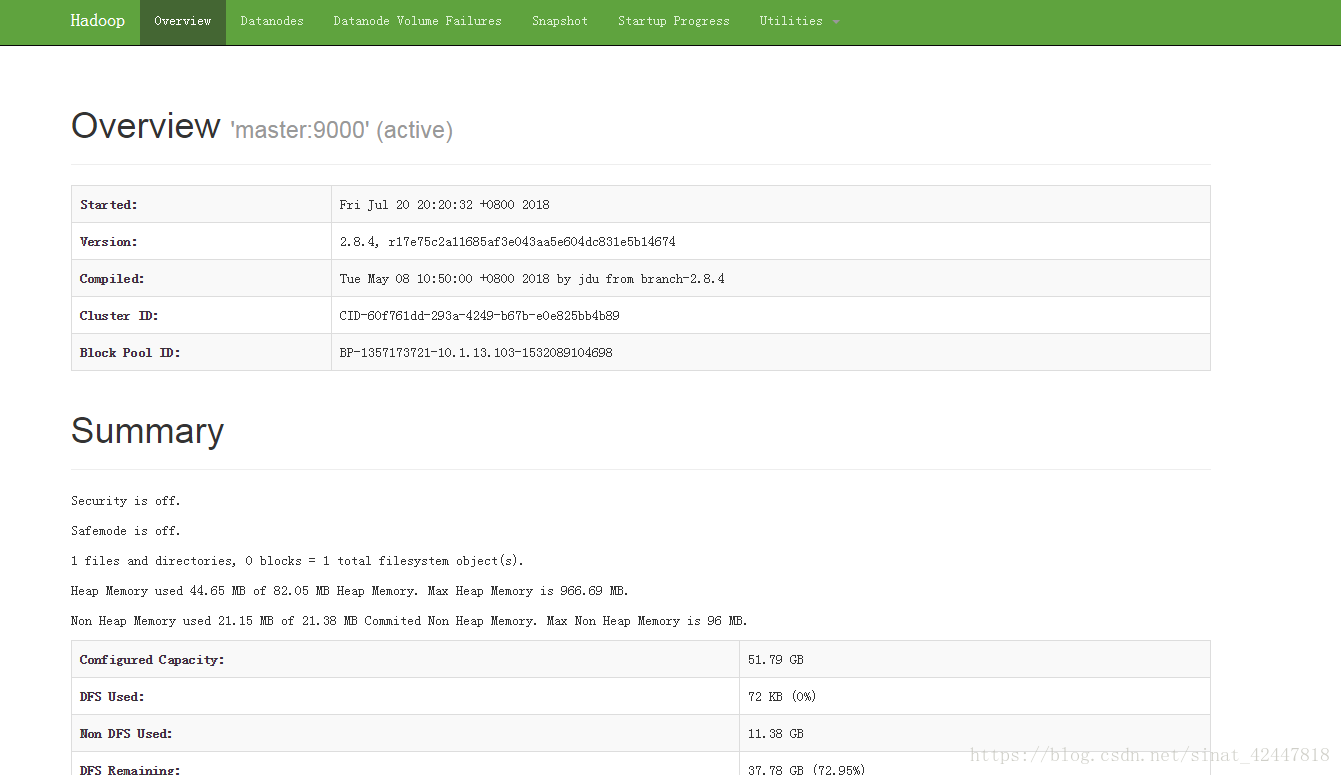
- 測試叢集是否可用
- 訪問10.1.13.103:50070
- 訪問10.1.13.103:8088

- 測試mapreduce來實現對pi的計算
- 進入到/usr/local/hoaddop/shared/hadoop/mapreduce
2、執行
hadoop jar hadoop-mapreduce-examples-2.8.4.jar pi 20 50
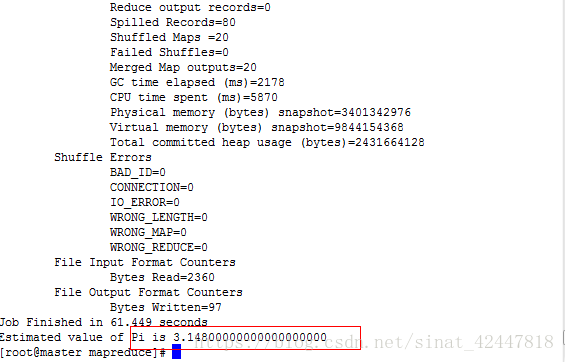
恭喜你成功了:如果你遇到如下問題
1、啟動時提示檔案不是安全的,可以做如下操作
到hadoop的bin目錄下
執行:./hadoop dfsadmin -safemode leave命令。
如果輸入hadoop沒有提示,那麼可以執行 source /etc/profile
相關推薦
Hadoop-2.8.4版本 分散式叢集搭建
Hadoop分散式叢集搭建 建立虛擬機器(用VmWare工具,centos6) 克隆三臺機器 master slaver1 slaver2 分別在每臺機器上安裝jdk >= 1.7版本 vim /etc/profile 四、同步三臺虛擬機器的時間(時間
Hadoop-2.8.0之分散式叢集(HA架構)搭建
1、安裝前準備 ①、叢集規劃: 主機名稱 使用者 主機IP 安裝軟體 執行程序 centos71 hzq 192.168.1.201 jdk、hadoop NameNode、DFSZKFailoverController(zkfc
centos7+hadoop 2.8 的多節點叢集搭建
1、叢集IP 192.168.2.218 hadoop-slave-1 192.168.2.4 hadoop-master 2、java 選用自帶的java 1.7.0. openjdk 關於java版本和hadoop版本的搭配可以參考hadoop官方wiki htt
hadoop-2.6.5偽分散式叢集搭建
本次搭建的偽分散式hadoop叢集所使用的作業系統是紅帽5,64位系統。 所以,需要注意以下幾點: 1、jdk和hadoop安裝包也應該是64位的 2、64位的jdk是從檔名可以直接看出,例如:jdk-8u172-linux-x64.tar.gz 3、而
Hadoop 2.6.4 完全分散式環境搭建
一、安裝linux 環境 OS Linux:CentOS 6.6 64bit 記憶體 1.5-2GB 硬碟 15-20GB 二、安裝JDK 及修改hostname 1、修改hostname [[email protected] ~]# vi /etc/s
Hadoop cdh版本分散式叢集搭建圖文教程
有很多想學習大資料的朋友,但苦於找不到系統的學習資料,搭建一個hadoop叢集都要耽擱很多時間。下面我給大家一個搭建大資料的圖文教程。教程中需要用到的軟體和資料我已經準備好了,下面是分享連結,直接下載即可。 連結:http://pan.baidu.com/s/1c1PW
在Ubuntu 上搭建hadoop-2.6.0-cdh分散式叢集
1 虛擬機器配置 序號 作業系統 CPU/core 記憶體/GB 硬碟/GB IP地址 主機名 1 Ubuntu 2 3 20 192.168.0.122 master 2 Ubuntu 1 2 20 192.168.0.123 slave
Hadoop-3.1.1完全分散式叢集搭建
一、工作準備 1.虛擬機器 安裝Vmware 安裝CentOs虛擬機器三臺 master 192.168.33.101 slave1 192.168.33.102 slave2 192.168.33.103 2.虛擬機器配置
hadoop-2.7.4-翻譯文件-分散式叢集搭建
安裝簡介 安裝Hadoop叢集通常需要在叢集中的所有機器上進行統一安裝,或者通過適合目標作業系統的打包系統進行安裝。 安裝的要點是對不同的節點分配不同的功能。 其他服務(例如Web App Proxy Server和MapReduce作業歷史記錄伺服器)通常根據負載在專用硬體或共享裝置上
Hadoop分散式叢集搭建方法(Version: java 1.8+CentOS 6.3)
夏天小廚 前言 大資料這個概念,說的通俗點就是對海量資料的處理分析。據不完全統計,世界百分之九十的資料都由近幾年產生,且不說海量資料的ETL,單從資料的儲存和資料展現的實時性,傳統的單機就已經無法滿足實際場景的需要例如很多OLAP系統。由此引出了Hadoop,Hadoop
Hadoop-2.8.0實踐——搭建Hadoop叢集
在本地測試hadoop成功後,我們在多臺主機上搭建hadoop叢集,用於處理大規模資料… 一、準備工作 1.1 系統環境 三臺 Ubuntu 16.04 64位筆記本(一臺作為Master節點,另外兩臺作為Slave節點) 1.2 建立使用者 建立使用者,併為其
Centos7 實現Hadoop-2.9.1分散式叢集搭建和部署(三臺機器)
一、準備三臺虛擬機器hadoop 192.168.131.128 localhost131 192.168.131.131 localhost134 192.168.131.134(以上是我的三臺虛擬機器的hostname 和 ip)hadoop 是 master 的 hos
Linux鞏固記錄(3) hadoop 2.7.4 環境搭建
修改 spa efault ram 是否 ado rmi down pan 由於要近期使用hadoop等進行相關任務執行,操作linux時候就多了 以前只在linux上配置J2EE項目執行環境,無非配置下jdk,部署tomcat,再通過docker或者jenkins自動部署
Linux上安裝Hadoop集群(CentOS7+hadoop-2.8.0)--------hadoop環境的搭建
html -a 總結 全分布式 .html oop details clas HR Linux上安裝Hadoop集群(CentOS7+hadoop-2.8.0)------https://blog.csdn.net/pucao_cug/article/details/716
Hadoop單機/偽分散式叢集搭建(新手向)
此文已由作者朱笑笑授權網易雲社群釋出。 歡迎訪問網易雲社群,瞭解更多網易技術產品運營經驗。 本文主要參照官網的安裝步驟實現了Hadoop偽分散式叢集的搭建,希望能夠為初識Hadoop的小夥伴帶來借鑑意義。 環境: (1)系統環境:CentOS 7.3.1611 64位 (2)J
Hadoop 分散式叢集搭建
1 修改配置檔案 1.1 hadoop-env.sh export JAVA_HOME=/usr/apps/jdk1.8.0_181-amd64 1.2 core-site.xml <property> <name>fs.def
zookeeper-3.4.10分散式叢集環境搭建
初始叢集狀態 機器名 IP 作用 linux系統 master 192.168.218.133 CentOS-6.9-x86_64-bin-D
大資料之Hadoop學習(環境配置)——Hadoop偽分散式叢集搭建
title: Hadoop偽分散式叢集搭建 date: 2018-11-14 15:17:20 tags: Hadoop categories: 大資料 點選檢視我的部落格: Josonlee’s Blog 文章目錄 前言準備 偽分
史上最簡單詳細的Hadoop完全分散式叢集搭建
一.安裝虛擬機器環境 Vmware12中文官方版 連結:https://pan.baidu.com/s/1IGKVfaOtcFMFXNLHUQp41w 提取碼:6rep 啟用祕鑰:MA491-6NL5Q-AZAM0-ZH0N2-AAJ5A 這個安裝就十分的簡單了,只需要不斷點選下
Hadoop-2.8.5的HA集群搭建
適配 bin tom proto format 切換 enabled 完成 數字 一、Hadoop HA 機制的學習 1.1、Hadoop 2.X 的架構圖 2.x版本中,HDFS架構解決了單點故障問題,即引入雙NameNode架構,同時借助共享存儲