
Scrapy框架解讀
學習python網路爬蟲怎能不知道Scrapy這種簡單易用的框架呢?今天我就給大家解讀一下Scrapy這個框架。
Scrapy是一款優秀的開源框架,由python開發,集螢幕抓取與web抓取與一身的優秀爬蟲框架,操作簡單,拓展方便。Scrapy用途廣泛,除了可以進行網頁抓取資料外,還可以進行資料探勘,監測以及自動化測試。但在這裡我們主要講解它的爬蟲部分功能。
Scrapy框架本身是由7個部件組成,Scrapy engine,排程器(Scheduler),下載器(Downloader),Spider,Item Pipeline,下載器中介軟體(Downloader Middlewares),Spider中介軟體(Spider Middlewares)具體內容可看下面結構圖。
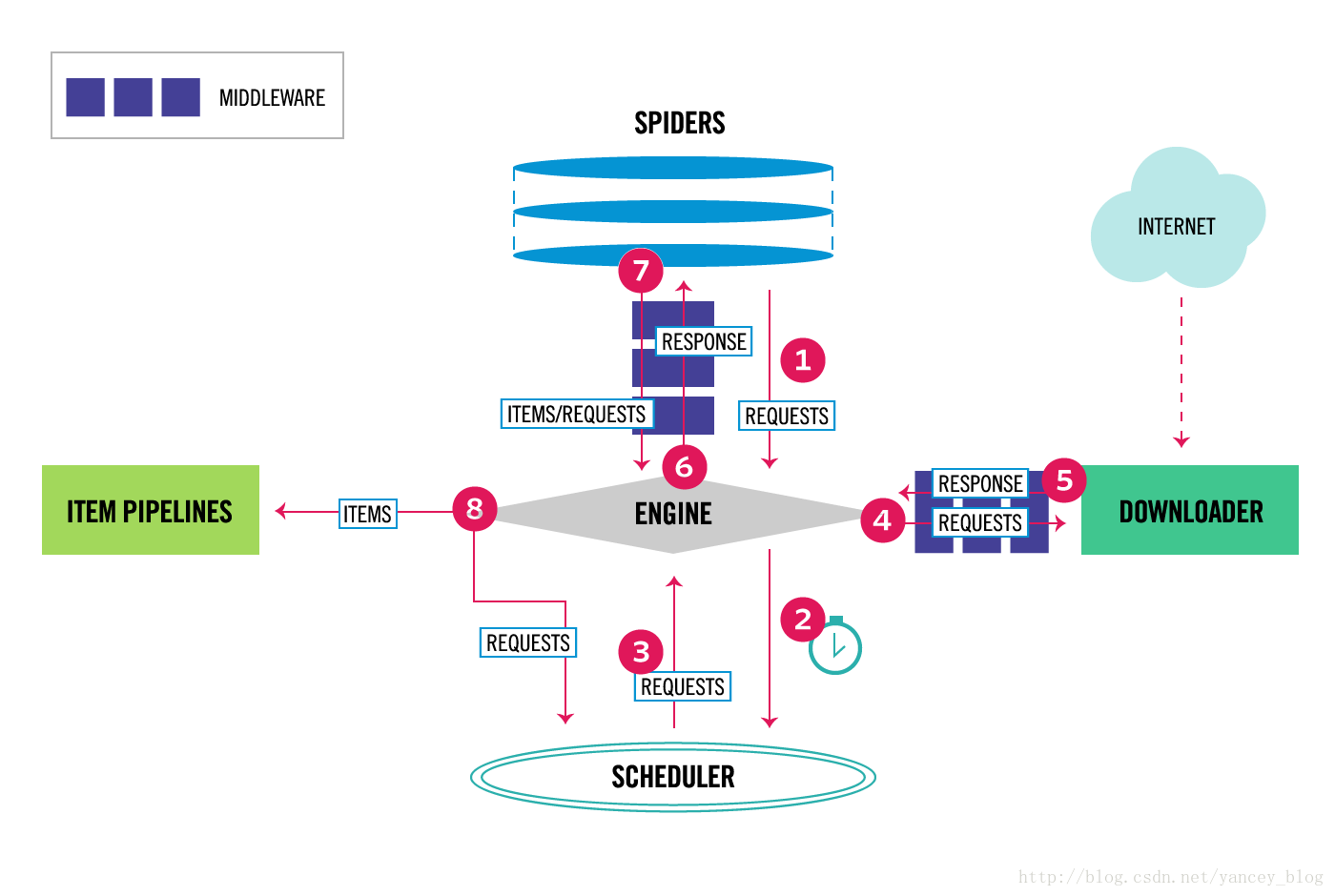
Scrapy engine顧名思義它就是這個框架的引擎,重要所在,就跟人的心臟一樣。它主要負責控制資料流在系統的所有元件中流動,並在相應動作發生時觸發事件。
排程器(Scheduler)呢主要負責從engine中接收request並將它們入隊,以便engine之後請求時傳送給engine
下載器(Downloader)則負責獲取頁面的資料並將資料返回給engine
下載器中介軟體(Downloader Middlewares):engine跟Downloader之間的特定鉤子(special hook),處理Downloader返回給engine的Response
Spider:使用者編寫的分析Response並提取Items
Spider中介軟體(Spider Middlewares):engine跟Spider之間的特定鉤子(special hook),處理Spider的輸入(response)和輸出(items及Request)
Item Pipeline:負責處理被Spider提取出來的items,進行資料儲存。
講解完Scrapy部件的具體內容後,接下來講解Scrapy 的運營操作流程
Scrapy工作流程:
1.engine開啟一個網站,獲得初始請求開始抓取
2.engine開始向排程器(Scheduler)請求
3.排程器(Scheduler)返回一個請求給engine
4.engine將請求傳送到下載器(Downloader)
5.下載器(Downloader)完成下載,將下載結果通過下載器中介軟體(Downloader Middlewares)返回給engine
6.engine將下載返回結果通過Spider中介軟體(Spider Middlewares)給Spider處理
7.Spider處理完成後,通過Spider中介軟體(Spider Middlewares)將處理後的資料items及request新請求傳送給engine
8.engine將items傳送給Item Pipeline進行資料儲存,將新請求傳送給排程器(Scheduler),排程器(Scheduler)計劃處理下一個請求抓取
9.重複過程(第三步開始),直到爬取完所有的request請求
以上九點就是Scrapy的工作流程,看起來是不是很簡單呢,下節內容再繼續深入瞭解Scrapy。
內容純屬個人理解,如果有不足之處或者錯誤之處請提示一下,謝謝。