
“社交網路”分析
前言
最近國產的一部電視劇《人民的名義》突然的就火了,隨之而來的是各大Coder們的社交網路分析。針對劇本中出現的人名,事件,詞頻等以圖形化的介面展示,清晰化的顯示出了劇本的特色。
而對於CSDN的關注人和粉絲的圖形化展示,也恰好符合這一個主題(暫且這麼認為吧)。本來想做的是公共粉絲(比如哪個人既關注了A,又關注了B),但是在部落格中由於許可權的問題,獲取不到相關的資料,於是只能做下關注人和粉絲的圖形化展示了。
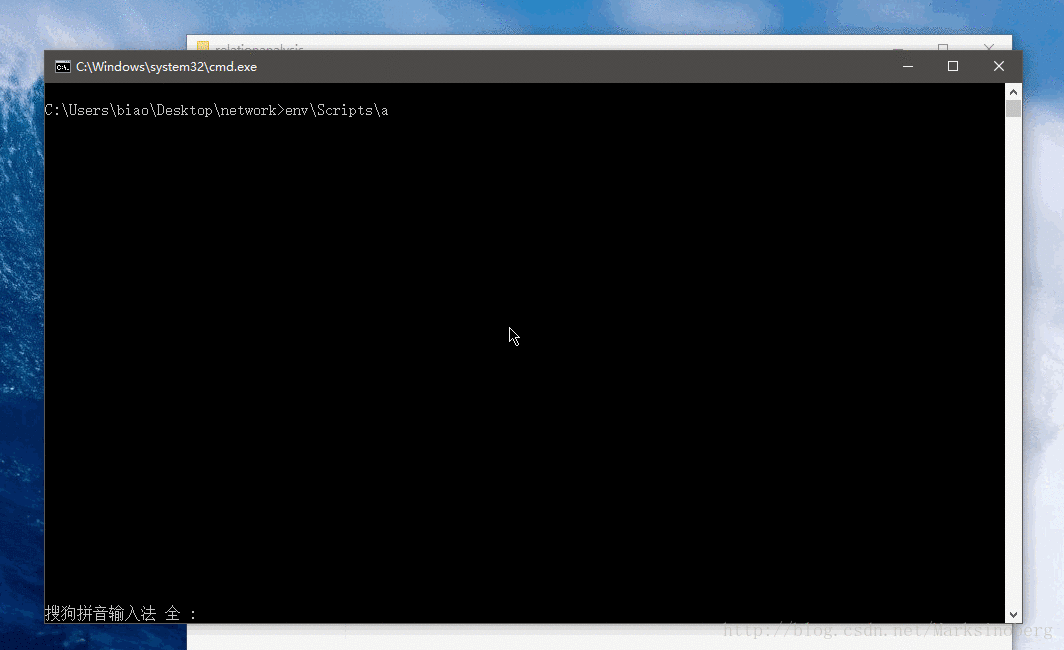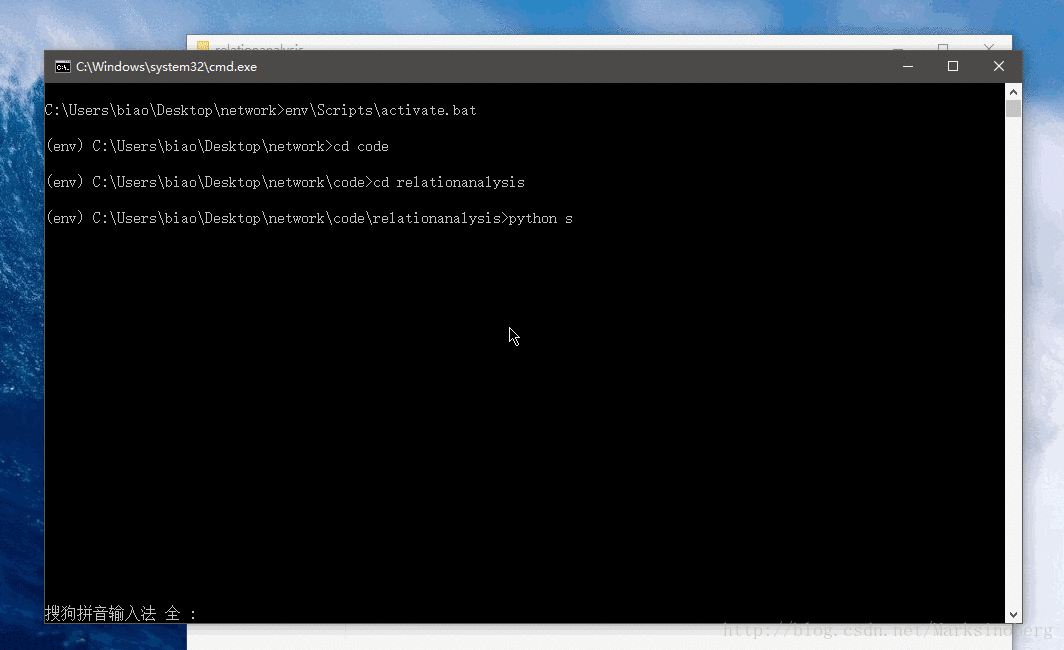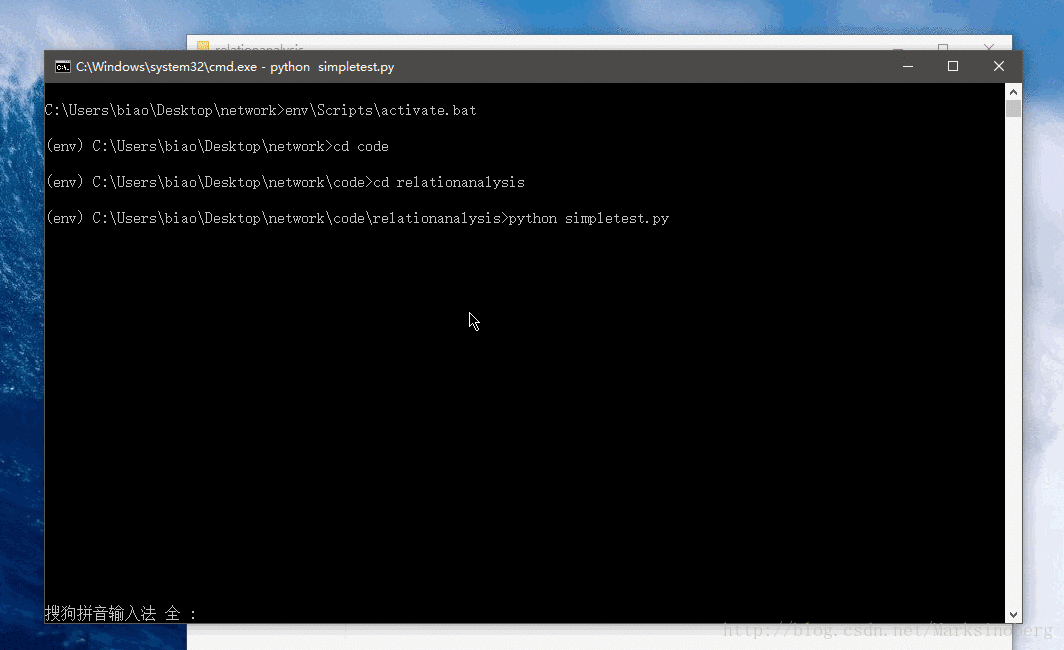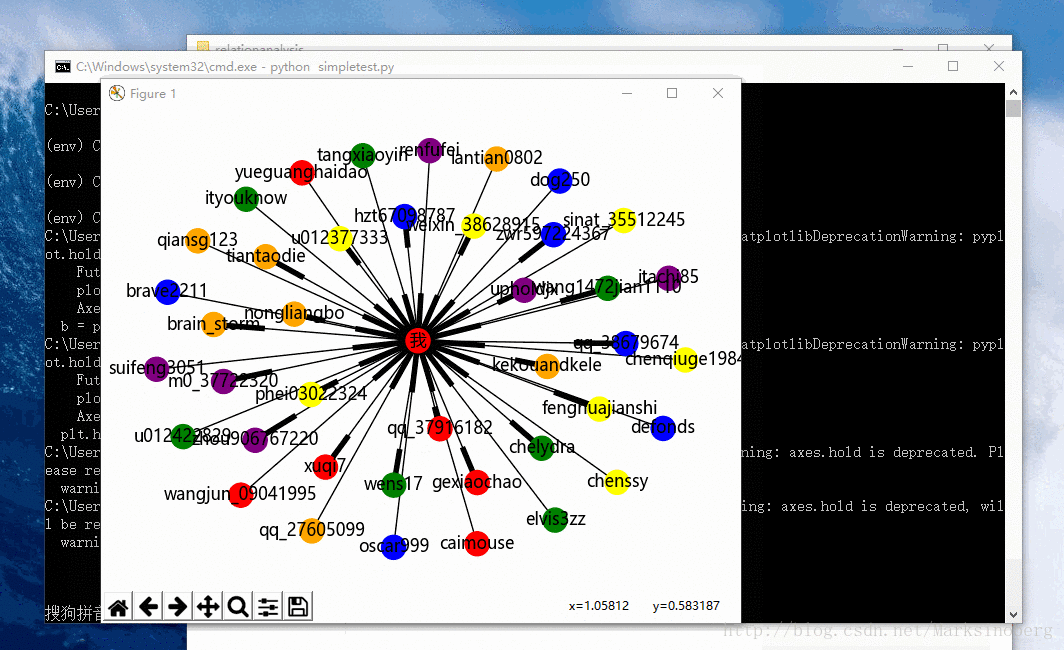
先來看下最終效果圖。
環境
從上面的效果圖上也可以看出,命令列前面有一個(env)的字首,這是使用了virtualenv的緣故。
virtualenv
使用virtualenv
安裝virtualenv也非常的簡單。
pip install virtualenv安裝好之後,就可以在任意的目錄下,使用命令列執行下面的命令。比如我在桌面新建了一個名為nerwork的資料夾,我就可以進入到這個資料夾內部,開啟命令列,執行:
virtualenv env這樣network資料夾下就會多出一個env的目錄,裡面的環境就是根據我們本地的Python環境而新建的一個隔離區。
這樣還不算完成,最後一步就是啟用這個虛擬環境。執行:
env\Scripts\activate.bat如果字首變成了(env)XXX,那就說明虛擬環境啟用成功了,我們只需要在這個虛擬環境中進行開發就可以了。
第三方庫
這裡需要用到一些第三方的庫,通過pip freeze命令,可以詳細的檢視每一個庫的名稱以及精確的版本號。
(env) C:\Users\biao\Desktop\network\code\relationanalysis>pip freeze
appdirs==1.4.3
beautifulsoup4==4.6.0
csdnbackup==0.0.1
cycler==0.10.0
decorator==4.0.11
matplotlib 但是我們需要安裝的卻不多,因為很多庫是與之關聯的,pip命令會自動把依賴的包幫我們安裝。我們需要安裝的包如下:
- networkx:
pip install networkx - csdnbackuo: 這個包是我之前寫過的一個關於CSDN部落格備份的工具庫,原始碼上傳到了GitHub。而且為了方便使用,我把它做成了一個.whl包,下面是下載地址:
https://github.com/guoruibiao/csdn-blog-backup-tool
下載裡面適合自己Python版本的whl檔案,然後執行
pip install csdnbackup-0.0.1-py2.py3-none-any.whl即可。
這樣,依賴的庫就基本上安裝成功了。
模組化
完成一個任務,首先並不是上來就寫程式碼。而是先搞清楚需求。比如這裡,要做的是關注人和粉絲的圖形化展示。那麼仔細想想,不難發現可以細化這個大任務。
- 獲取粉絲資訊
- 獲取關注人資訊
- 關於圖形化展示的部分
這樣一來,我們只需要每次完成一個小任務,最終通過整合測試就能完成任務了。下面針對每一個小任務進行實現。
爬蟲模組
這裡的爬蟲模組不是必須要用我那個庫,你也可以自己寫。但是重複造輪子是一件很枯燥的事,人生苦短,咱還是用輪子吧。
關於模擬登陸
from csdnbackup.login import Login然後使用下面的程式碼即可實現模擬登陸。
# coding: utf8
# @Author: 郭 璞
# @File: logintest.py
# @Time: 2017/5/18
# @Contact: [email protected]
# @blog: http://blog.csdn.net/marksinoberg
# @Description: csdnbackup模擬登陸測試
from csdnbackup.login import Login
import getpass
#
username = input('請輸入您的賬號:')
password = getpass.getpass(prompt='請輸入您的密碼:')
loginer = Login(username=username, password=password)
session = loginer.login()
headers = loginer.headers
headers['Host'] = 'blog.csdn.net'
response = session.get('http://blog.csdn.net/marksinoberg', headers=headers)
print(response.status_code)
print(response.text)
print("網頁總長度:", len(response.text))
沒有圖不足以證實此輪子的好用。
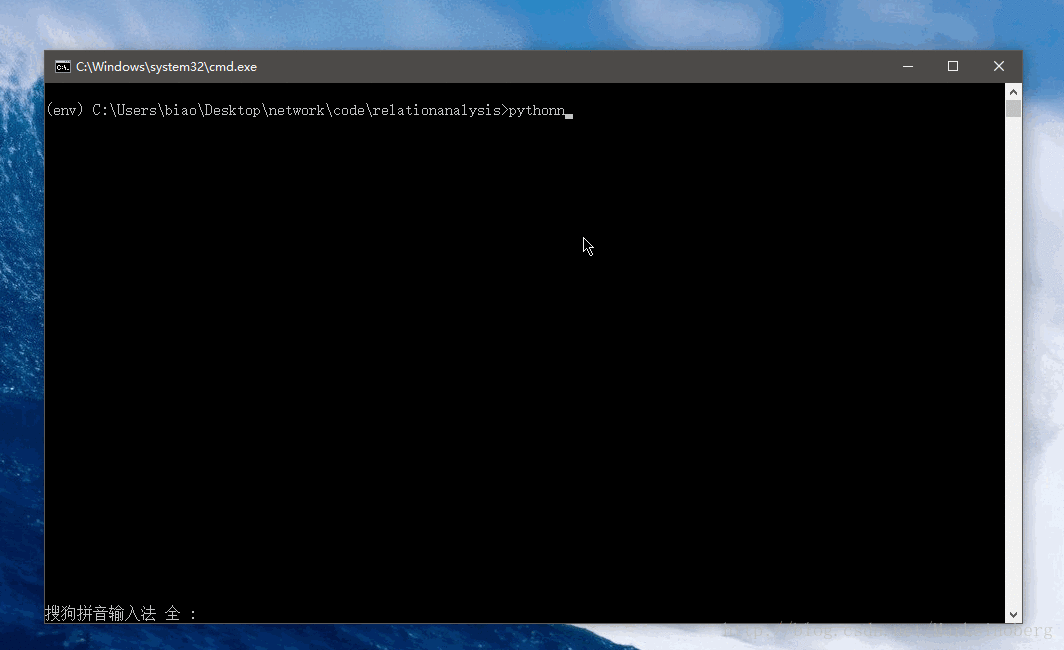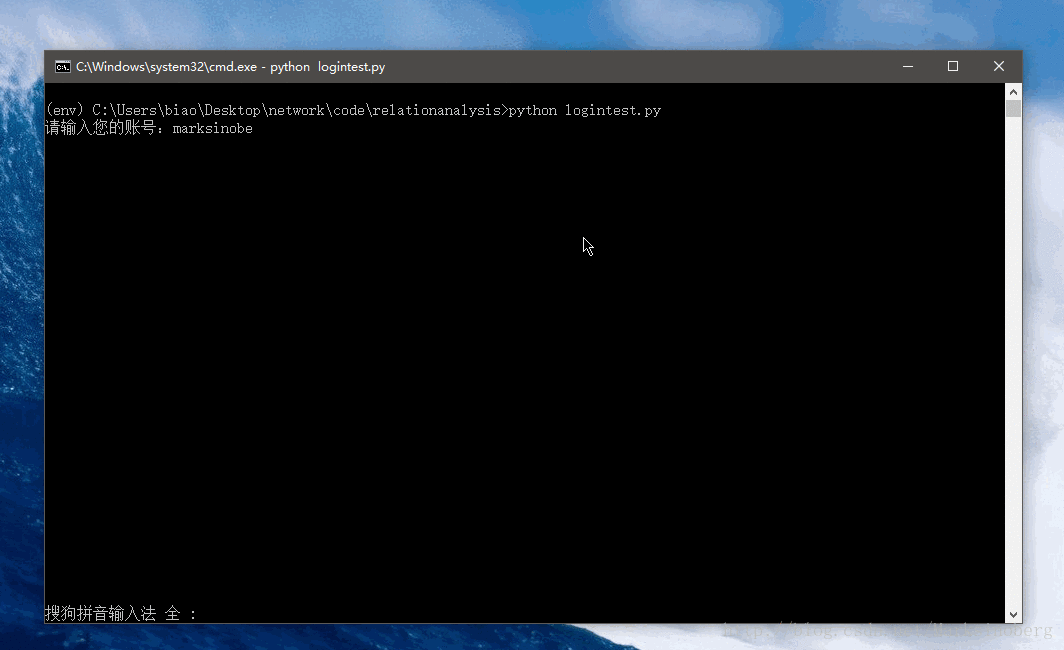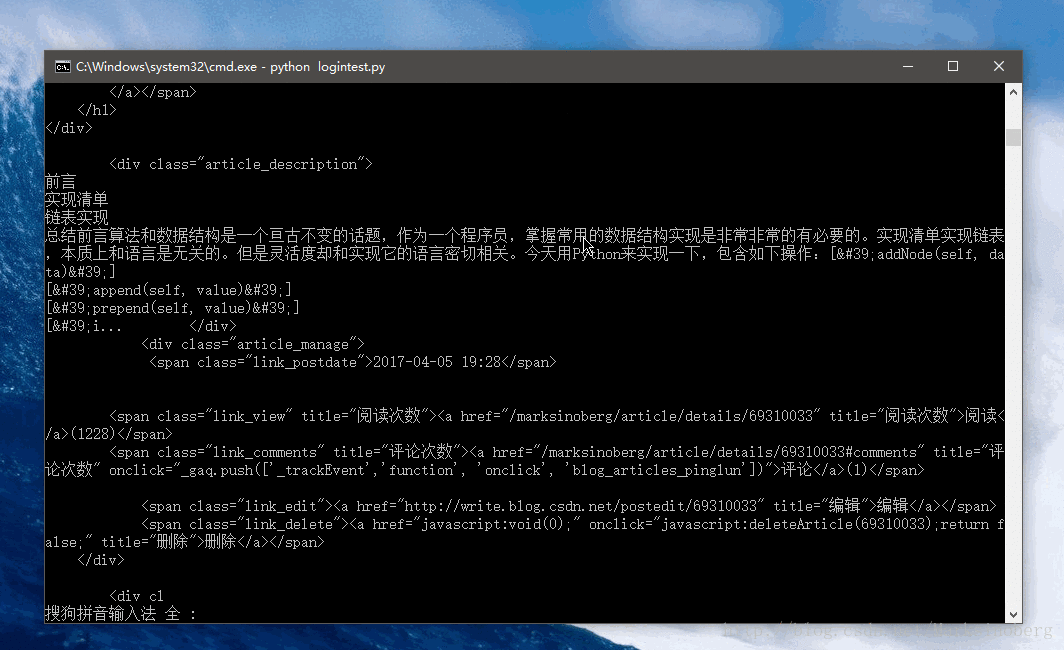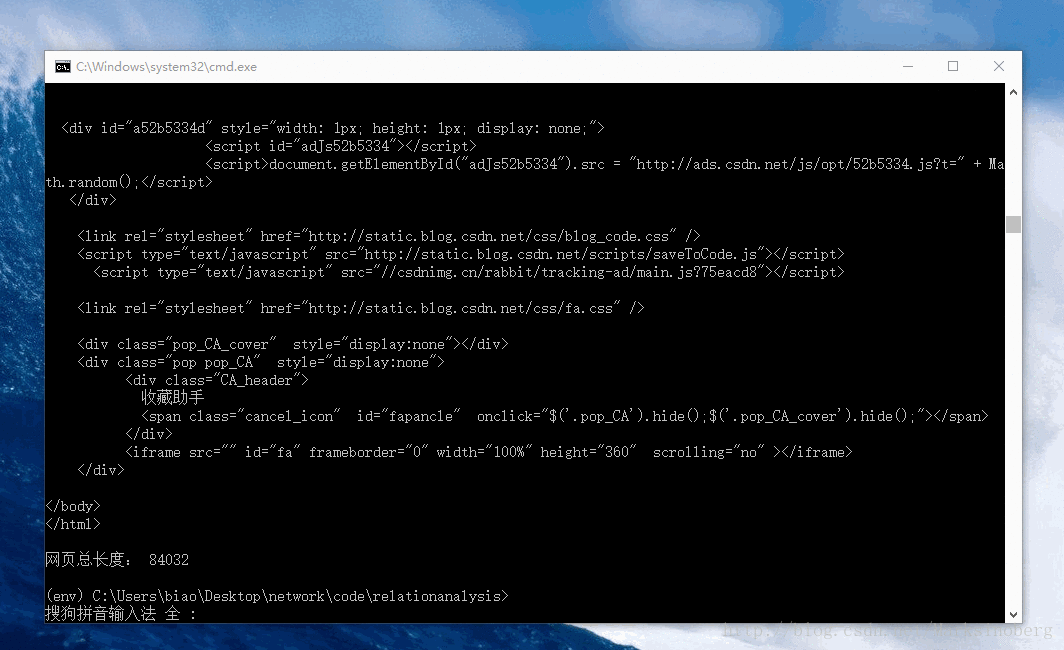
爬取資料
巧婦難為無米之炊,下面來弄點米出來。
# coding: utf8
# @Author: 郭 璞
# @File: spider.py
# @Time: 2017/5/18
# @Contact: [email protected]
# @blog: http://blog.csdn.net/marksinoberg
# @Description: 爬蟲,爬取博主的粉絲資訊
from csdnbackup.login import Login
from bs4 import BeautifulSoup
import math
import numpy as np
class Fans(object):
def __init__(self, domain, password):
self.domain = domain
self.loginer = Login(username=domain, password=password)
self.session = self.loginer.login()
# set the headers
self.headers = self.loginer.headers
self.headers['Referer'] = 'http://blog.csdn.net/{}'.format(self.domain)
self.headers['Host'] = 'my.csdn.net'
def get_fans_number(self):
url = 'http://my.csdn.net/{}'.format(self.domain)
response = self.session.get(url=url, headers=self.headers)
# print(response.text)
if response.status_code == 200:
soup = BeautifulSoup(response.text, 'html.parser')
return soup.find('a', {'href': '/my/fans'}).get_text()
else:
return 0
def get_fans(self):
fans = []
url = 'http://my.csdn.net/{}'.format(self.domain)
fans_number = self.get_fans_number()
pages = math.ceil(int(fans_number)/20)
# pages+1
for index in range(1, pages):
url = 'http://my.csdn.net/my/fans/{}'.format(index)
response = self.session.get(url=url, headers=self.headers)
if response.status_code == 200:
soup = BeautifulSoup(response.text, 'html.parser')
user_names = soup.find_all('a', {'class': 'user_name'})
fans.extend([str(username.attrs['href']).lstrip('/') for username in user_names])
else:
raise Exception("獲取第{}頁資料失效".format(index))
return fans
def get_follow_number(self):
url = 'http://my.csdn.net/{}'.format(self.domain)
response = self.session.get(url=url, headers=self.headers)
# print(response.text)
if response.status_code == 200:
soup = BeautifulSoup(response.text, 'html.parser')
return soup.find('a', {'href': '/my/follow'}).get_text()
else:
return 0
def get_follow(self):
follows = []
url = 'http://my.csdn.net/{}'.format(self.domain)
follow_number = self.get_follow_number()
pages = math.ceil(int(follow_number) / 20)
# pages+1
for index in range(1, pages):
url = 'http://my.csdn.net/my/follow/{}'.format(index)
response = self.session.get(url=url, headers=self.headers)
if response.status_code == 200:
soup = BeautifulSoup(response.text, 'html.parser')
user_names = soup.find_all('a', {'class': 'user_name'})
follows.extend([str(username.attrs['href']).lstrip('/') for username in user_names])
else:
raise Exception("獲取第{}頁資料失效".format(index))
return follows
class ListUtils(object):
"""
利用numpy 進行資料的篩選
"""
def __init__(self):
pass
@staticmethod
def comminInList(self, x=[], y=[]):
return np.intersect1d(ar1=x, ar2=y, assume_unique=True)
if __name__ == '__main__':
fans = Fans(domain='你的使用者名稱', password='你的密碼')
# fans1 = fans.get_fans(username='marksinoberg')
# result = ListUtils.comminInList(fans1, fans2)
# print(result)
follows = fans.get_follow()
print(follows)
對照一下執行結果,關注人資訊獲取如下。
圖形化
圖形化需要藉助matplotlib來畫圖,而載體就是networkx,所以我們需要對此進行安裝。在此不再過多敘述。
然後就是對於networkx的使用了。
步驟
一般有如下幾個步驟:
- 宣告graph
- 填充節點和邊
- 畫出圖形
中文節點問題
預設的matplotlib 對於中文支援的不太友好。為了解決這一個問題,可以通過如下步驟實現。
到matplotlib的安裝目錄下找到字型資料夾, 比如我的是
C:\Users\biao\Desktop\network\env\Lib\site-packages\matplotlib\mpl-data\fonts\ttf然後從本地的字型庫(比如C:\Windows\Fonts\XX.ttf)中拷貝一份,重新命名為DejaVuSans.ttf,放置到剛才的matplotlib字型資料夾下即可。為什麼要這麼做?答案就是matplotlib預設使用DejaVuSans.ttf。
實戰
下面實戰一下CSDN的關注人和粉絲跟自己的關係演示。因為粉絲人數過多的話,會導致生成的圖片重疊度較大,所以這裡選取前20個關注人和前20個粉絲。
import networkx as nx
import matplotlib.pyplot as plt
import spider
fans = spider.Fans(domain='你的使用者名稱', password='你的密碼')
fans_names = fans.get_fans()[:20]
follow_names = fans.get_follow()[:20]
nodes = fans_names
relations1 = [('我', username) for username in fans_names]
relations2 = [(username, '我') for username in follow_names]
colors = ['red', 'orange', 'yellow', 'green', 'blue', 'purple']
graph = nx.DiGraph()
graph.add_node('我')
graph.add_nodes_from(fans_names)
graph.add_edges_from(relations1)
graph.add_edges_from(relations2)
nx.draw(graph, with_labels=True, hold=True, node_color=colors)
plt.title('CSDN 部落格關注與粉絲圖形化顯示')
plt.axis('off')
plt.show()
生成的圖片如下:
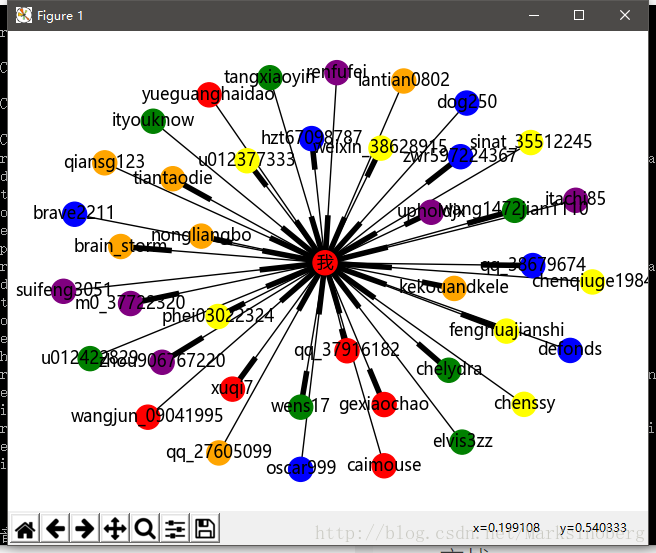
總結
對於networkx,這裡講的並不是很多,也可以說就沒怎麼講。這是因為官方文件的卻是夠詳細了。而且越往深處看,越覺驚喜。基本上對於社交網路的分析,它是一個很不錯的選擇了。
還有就是關於輪子,平時多寫一些可靠的輪子,說不一定哪天就用到了。
相關推薦
社交網路分析演算法(SNA)
近來學習聚類,發現聚類中有一個非常有趣的方向—社交網路分析,這篇只是一篇概況,並沒有太多的公式推導和程式碼,基本是用人話解釋社交網路分析中的常用的幾種演算法。詳細到每個演算法的以後有空再把詳細的公式和程式碼補上。 目錄: 1.應用場景 2.分析指標 3.
【轉載】使用 IBM SPSS Modeler 進行社交網路分析
背景知識:社交網路分析、資料探勘、IBM SPSS Modeler社交網路分析是人、組織、計算機或者其他資訊或知識處理實體之間的關係和流動資訊的對映和測量。圖 1 是社交網路的一個示意圖,其中的節點表示人、組織、計算機或者其他資訊或知識處理實體;連線表示節點之
社交網路分析中(SNA)的中心性(centrality) 度中心性(degree),接近中心性(closeness),中介中心性(betweenness)
I. 概念梳理中心性(Centrality)是社交網路分析(Social network analysis, SNA)中常用的一個概念,用以表達社交網路中一個點或者一個人在整個網路中所在中心的程度,這個程度用數字來表示就被稱作為中心度(也就是通過知道一個節點的中心性來了解判斷
“社交網路”分析
前言 最近國產的一部電視劇《人民的名義》突然的就火了,隨之而來的是各大Coder們的社交網路分析。針對劇本中出現的人名,事件,詞頻等以圖形化的介面展示,清晰化的顯示出了劇本的特色。 而對於CSDN的關注人和粉絲的圖形化展示,也恰好符合這一個主題(暫
【python資料探勘課程】十七.社交網路Networkx庫分析人物關係(初識篇)
這是《Python資料探勘課程》系列文章,也是我大資料金融學院上課的部分內容。本章主要講述複雜網路或社交網路基礎知識,通過Networkx擴充套件包繪製人物關係,並分析了班級學生的關係學院資訊。本篇文章為初始篇,基礎文章希望對你有所幫助,如果文章中存在錯誤或不足支援,還請海涵
bzoj1491 [NOI2007]社交網路
[NOI2007]社交網路 Time Limit: 10 Sec Memory Limit: 64 MB Description 在社交網路(socialnetwork)的研究中,我們常常使用圖論概念去解釋一些社會現象。不妨看這樣的一個問題。 在一個社交圈子裡有n個人,人與人之間有不同程度的關係。我們將
#linux 記憶體、磁碟、程序、網路分析
1 記憶體 [root@localhost ~]# free -m total used free shared buffers cached Mem: 15951 13825
洛谷P2047||bzoj1491 [NOI2007]社交網路
https://www.luogu.org/problemnew/show/P2047 https://www.lydsy.com/JudgeOnline/problem.php?id=1491 也可以用floyed做掉 1 #include<cstdio> 2
【BZOJ1491】社交網路
題目連結:https://www.lydsy.com/JudgeOnline/problem.php?id=1491 算是Floyd的擴充套件吧,在求最短路的同時,記錄最短路的條數。 一旦獲得的任意兩點間最短路的條數,就可以在O(n^3)的時間內求出每個點的l了。 提交一直出錯,看了
[BZOJ] 1491 [洛谷] P2047 [NOI2007] 社交網路
傳送門——洛谷 傳送門——BZOJ Description 在社交網路(socialnetwork)的研究中,我們常常使用圖論概念去解釋一些社會現象。不妨看這樣的一個問題。 在一個社交圈子裡有n個人,人與人之間有不同程度的關係。我們將這個關係網路對應到一個n個結點的無向圖上,
R語言 igraph——圖挖掘助力社會網路分析
該文章出自http://www.ituring.com.cn/article/1762,介紹了igraph包,igraph包可統計分析網路圖的幾何特徵,還包括圖上的很多經典演算法,例如最大連通圖、最短路徑等。 社交網路(如Facebook,Twitter)可以完整地表現人們的生活。人們用
網際網路數字營銷時代,搜尋引擎與社交網路哪種廣告會有效果呢?
新媒體時代,使用者的注意力越來越分散,流量越來越貴,就算花錢也收不到好的效果。這點,相信很多企業家都感同身受。那麼,數字營銷時代,搜尋引擎與社交網路哪種廣告會有效果呢? 價值攫取型的營銷戰略 價值攫取型就是想辦法爭取更多存量資源,比如買更好的廣告位、找頂級的代言人等。幾年前,大部分品牌把
網路分析技術
一、使用tcpdump與wireshark解決疑難問題;tcpdump的常用5個引數:-i:指定抓包使用的網絡卡;-nnn:ip和埠號以數字顯示;-s:指定抓包的大小;-c:指定抓包數量;-w:將抓包資料儲存到檔案; 常用的過濾器:過濾器規則可以使用and或者or進行組合;
【ArcGIS|空間分析|網路分析】0 網路分析總結
文章目錄 網路分析一般步驟 1 配置Network Analyst環境 2 向ArcMap新增網路資料集 3 建立網路分析圖層和新增網路分析物件 網路分析圖層和網路分析物件的關係 網路分析物件屬性欄位
【ArcGIS|空間分析|網路分析】12 使用約束屬性執行網路分析
文章目錄 要求 步驟 1 在網路資料集屬性中檢查“約束條件用法”引數 2 在網路分析圖層屬性中檢查“約束條件用法”引數 3 求解路徑分析 4 禁止收費公路 5 避開收費公路 6 首選指定的貨車路徑
【ArcGIS|空間分析|網路分析】11 利用流量資料執行網路分析
文章目錄 要求 步驟 1 配置上午 9:00 的服務區圖層 2 為上午 9:00 的服務區圖層求解 3 配置晚上 10:00 的服務區圖層 4 為晚上 10:00 的服務區圖層求解 5 將上午 9:00 和晚上 10
【ArcGIS|空間分析|網路分析】10 在網路資料集上配置實時流量
文章目錄 要求 步驟 1 建立儲存實時流量檔案(DTF 檔案)的資料夾 2 建立網路資料集 *3 配置時區屬性 4 構建網路資料集 *5 實時流量源 獲取資料提供商帳戶 開啟模型工具
【ArcGIS|空間分析|網路分析】9 使用位置分配選擇最佳商店位置
文章目錄 要求 步驟 1 建立位置分配分析圖層 2 新增候選設施點 3 新增請求點 4 設定位置分配分析的屬性 5 執行此過程以確定最佳商店位置 6 新增必需設施點 7 設定分析的屬性(最大化人流量,
【ArcGIS|空間分析|網路分析】8 查詢能夠為需求點對提供服務的最佳路徑
文章目錄 要求 步驟 1 建立車輛配送 (VRP) 分析圖層 2 新增特殊要求 3 新增停靠點 4 新增需求點對 5 新增站點 6 新增路徑 7 新增路徑區 8 設定分析屬性 9 執行
【ArcGIS|空間分析|網路分析】7 使用一支車隊服務一組停靠點
參考ArcGIS幫助文件 文章目錄 要求 車輛配送 1 建立車輛配送 (VRP) 分析圖層 2 新增停靠點 3 新增站點 4 新增路徑 5 設定車輛配送 (VRP) 分析的屬性 6 執行這一