
Mysql和MongoDB效能對比及應用場景分析
一、前言
為什麼調研MongoDB?
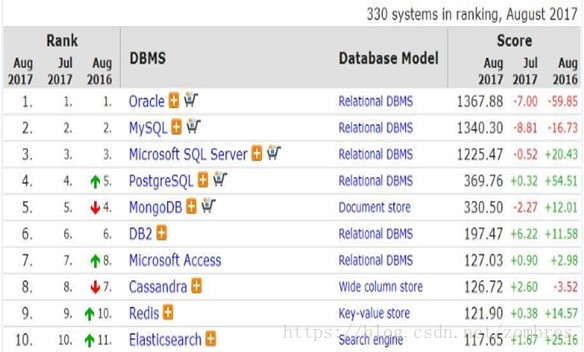
下圖是DB-Engines2017年8月資料庫的排名統計,可以看到MongoDB總排名在第5,在Nosql資料庫中排名第1。
優點:
1)社群活躍,使用者較多,應用廣泛。
2)MongoDB在記憶體充足的情況下資料都放入記憶體且有完整的索引支援,查詢效率較高。
3)MongoDB的分片機制,支援海量資料的儲存和擴充套件。
缺點:
1)不支援事務
2)不支援join、複雜查詢
初步調研下來,MongoDB具備我們需要的特性,而缺點不影響我們的應用場景,故接下來我們就開始做實際的效能壓測。
二、壓測效能對比
1、準備條件
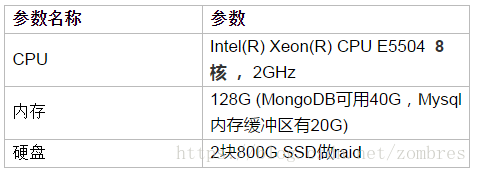
1)Mysql 、MongoDB資料庫所在伺服器硬體環境
2)最新的資料庫版本
MongoDB server version: 3.4.5
MongoDB client version: mongo-java-driver-2.14.3
Mysql server version:5.6.34
Mysql connector version: mysql-connector-java-6.0.6
MongoDB使用的儲存引擎wiredTiger
Mysql使用的儲存引擎InnoDB
3)資料庫表結構及索引
MongoDB索引為dateTime 且是唯一索引。我們實際測試使用的MongoDB資料結構及欄位如圖所示。
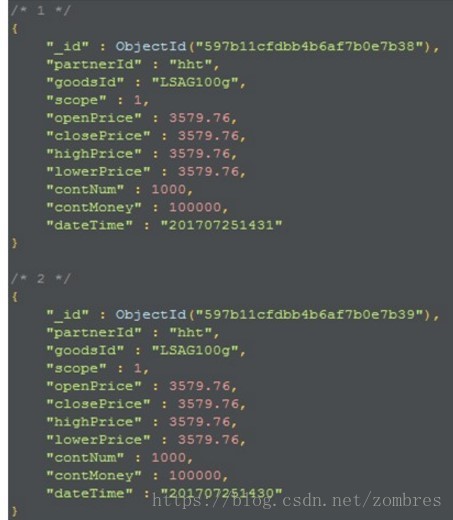
Mysql索引為DATETIME,PARTNER_ID,GOODS_ID,SCOPE且是唯一索引。我們實際測試使用的Mysql資料結構及欄位如圖所示。

sql語句根據datetime欄位進行時間範圍的查詢
4)連線池最大連線數都設定為200個。sql語句調到最優
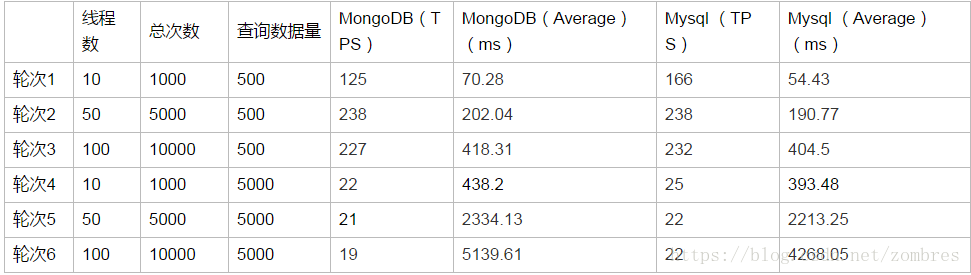
2、百萬、千萬級別的下不同查詢量不同併發量的壓測結果
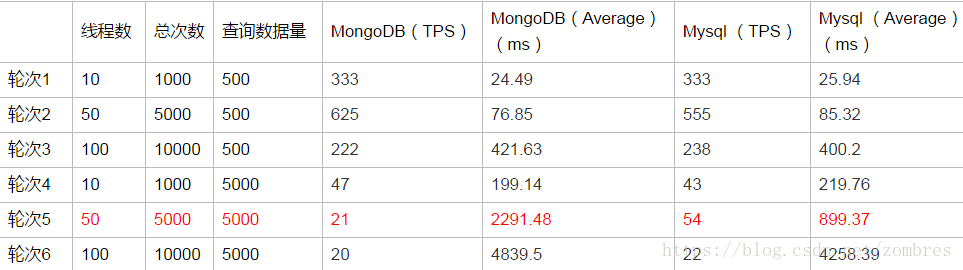
資料庫表中記錄數總量在百萬、千萬級別的壓測資料及結果如表所示。
3、億級別的下不同查詢量不同併發量的壓測結果
資料庫表中記錄數總量在億級別的壓測資料及結果如表所示。
壓測結果分析:
1)當每次查詢資料量在500條時,無論表中資料總量千萬或者億級別,Mysql和MongoDB在100執行緒併發的情況下查詢效能相當,表現良好,平均響應時間在500ms以內,TPS在230左右。
2)當每次查詢資料量在5000條時,表中資料總量為千萬級別時,MongoDB在50執行緒併發情況下查詢效能不及Mysql 的一半,100執行緒併發情況查詢效能都很差,平均響應時間在4500ms左右,表中資料總量為億級別時,在50個及以上的併發情況下,MongoDB和Mysql效能都較差。
在本案例簡單資料模型下的時間範圍內的等值查詢應用場景下,MongoDB在高併發條件下的大資料量查詢效能並沒有比Mysql更好。另外還有一點需要注意的是,在本案例中,資料總量由百萬級別到千萬級別再到億級別的變化過程中,對於查詢效能的影響都不是很大,但對於查詢資料量的數倍增長卻十分敏感,所以在考量資料庫查詢效能的時候,也要重點考量應用的單次查詢量的需求。
儘管MongoDB在我們的這種應用場景下並沒有達到我們預期的效能,我們也簡單的調研了下Mysql和MongoDB對於記憶體的使用機制以及一些可能影響查詢效率的內部配置。
三、Mysql和MongoDB記憶體結構
1、InnoDb記憶體使用機制
Innodb體系結構如圖所示。
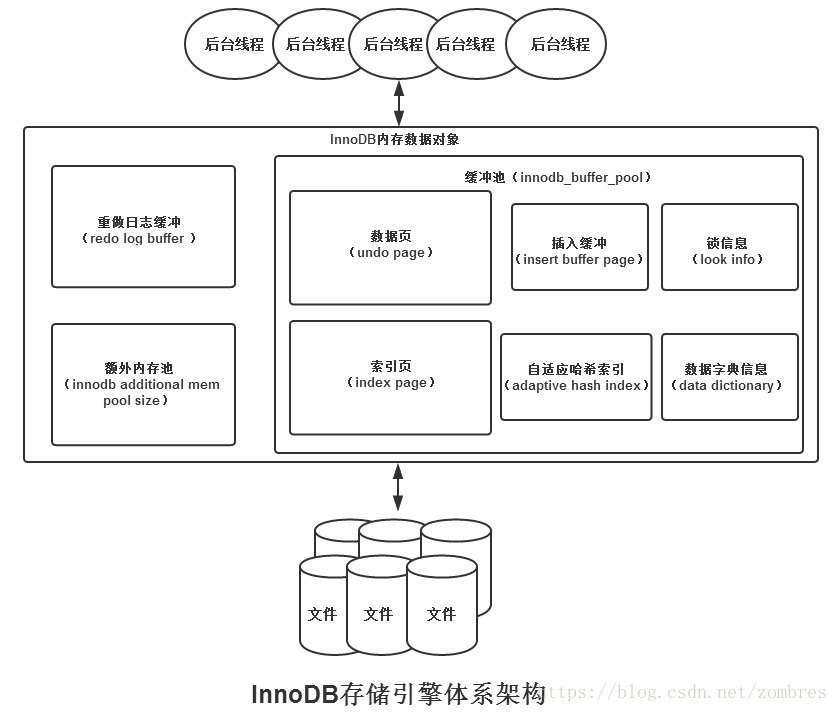
壓測的Mysql使用的是Innodb儲存引擎,Innodb關於查詢效率有影響的兩個比較重要的引數分別是innodb_buffer_pool_size,innodb_read_ahead_threshold。
innodb_buffer_pool_size指的是Innodb緩衝池的大小,本例中Innodb緩衝池大小為20G,該引數的大小可通過命令指定innodb_buffer_pool_size 20G。緩衝池使用改進的LRU演算法進行管理,維護一個LRU列表、一個FREE列表,FREE列表存放空閒頁,資料庫啟動時LRU列表是空的,當需要從緩衝池分頁時,首先從FREE列表查詢空閒頁,有則放入LRU列表,否則LRU執行淘汰,淘汰尾部的頁分配給新頁。
innodb_read_ahead_threshold相對應的是資料預載入機制,innodb_read_ahead_threshold 30表示的是如果一個extent中的被順序讀取的page超過或者等於該引數變數的,Innodb將會非同步的將下一個extent讀取到buffer pool中,比如該引數的值為30,那麼當該extent中有30個pages被sequentially的讀取,則會觸發innodb linear預讀,將下一個extent讀到記憶體中;在沒有該變數之前,當訪問到extent的最後一個page的時候,Innodb會決定是否將下一個extent放入到buffer pool中;可以在Mysql服務端通過show innodb status中的Pages read ahead和evicted without access兩個值來觀察預讀的情況:
Innodb_buffer_pool_read_ahead:表示通過預讀請求到buffer pool的pages;
Innodb_buffer_pool_read_ahead_evicted:表示由於請求到buffer pool中沒有被訪問,而驅逐出記憶體的頁數。
可以看出來,Mysql的緩衝池機制是能充分利用記憶體且有預載入機制,在某些條件下目標資料完全在記憶體中,也能夠具備非常好的查詢效能。
2、MongoDB的儲存結構及資料模型
1)本例中MongoDB使用的儲存引擎是WiredTiger,WiredTiger的結構如圖所示。
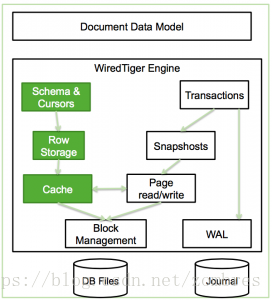
WiredTiger Cache的實現原理圖如圖所示。
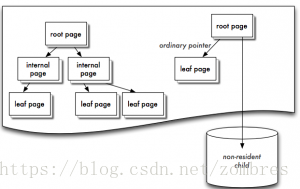
Wiredtiger的Cache採用Btree的方式組織,每個Btree節點為一個page,root page是btree的根節點,internal page是btree的中間索引節點,leaf page是真正儲存資料的葉子節點;btree的資料以page為單位按需從磁碟載入或寫入磁碟。
可以通過在配置檔案中指定storage.wiredTiger.engineConfig.cacheSizeGB引數設定引擎使用的記憶體量。此記憶體用於快取工作集資料(索引、namespace,未提交的write,query緩衝等)。
2)資料模型
內嵌
MongoDB的文件是無模式的,所以可以支援各種資料結構,內嵌模型也叫做非規格化模型(denormalized)。在MongoDB中,一組相關的資料可以是一個文件,也可以是組成文件的一部分。

內嵌型別支援一組相關的資料儲存在一個文件中,這樣的好處就是,應用程式可以通過比較少的的查詢和更新操作來完成一些常規的資料的查詢和更新工作。
當遇到以下情況的時候,我們應該考慮使用內嵌型別:
如果資料關係是一種一對一的包含關係,例如下面的文件,每個人都有一個contact欄位來描述這個人的聯絡方式。像這種一對一的關係,使用內嵌型別可以很方便的進行資料的查詢和更新。
{
”_id”: ,
”name”: “Wilber”,
”contact”: {
“phone”: “12345678”,
“email”: “wilber@shanghai.com”
}
}如果資料的關係是一對多,那麼也可以考慮使用內嵌模型。例如下面的文件,用posts欄位記錄所有使用者釋出的部落格。在這中情況中,如果應用程式會經常通過使用者名稱欄位來查詢改使用者釋出的部落格資訊。那麼,把posts作為內嵌欄位會是一個比較好的選擇,這樣就可以減少很多查詢的操作。
{
“_id”: ,
“name”: “Wilber”,
“contact”: {
”phone”: “12345678”,
”email”: “[email protected].com”
},
”posts”: [
{
”title”: “Indexes in MongoDB”,
”created”: “12/01/2014”,
”link”: “www.linuxidc.com”
},
{
”title”: “Replication in MongoDB”,
”created”: “12/02/2014”,
”link”: “www.linuxidc.com”
},
{
”title”: “Sharding in MongoDB”,
”created”: “12/03/2014”,
”link”: “www.linuxidc.com”
}
]
}根據上面的描述可以看出,內嵌模型可以給應用程式提供很好的資料查詢效能,因為基於內嵌模型,可以通過一次資料庫操作得到所有相關的資料。同時,內嵌模型可以使資料更新操作變成一個原子寫操作。然而,內嵌模型也可能引入一些問題,比如說文件會越來越大,這樣就可能會影響資料庫寫操作的效能,還可能會產生資料碎片(data fragmentation)。
引用
相對於嵌入模型,引用模型又稱規格化模型(Normalized data models),通過引用的方式來表示資料之間的關係。這裡同樣使用來自MongoDB文件中的圖片,在這個模型中,把contact和access從user中移出,並通過user_id作為索引來表示他們之間的聯絡。
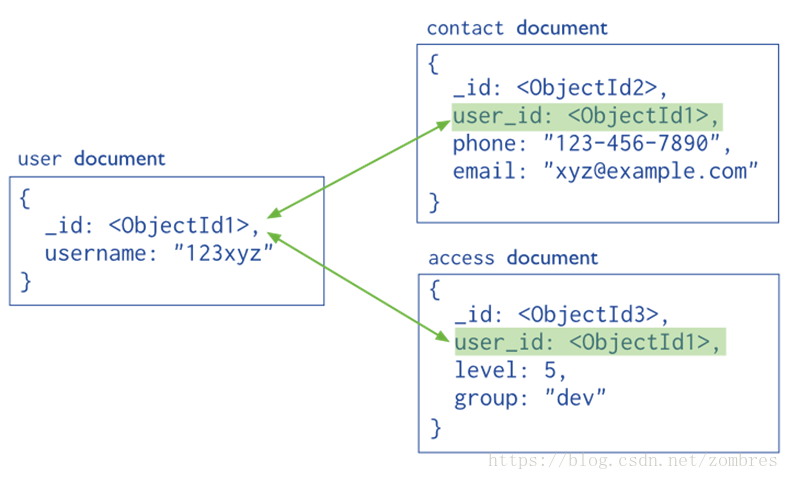
當我們遇到以下情況的時候,就可以考慮使用引用模型了:
使用內嵌模型往往會帶來資料的冗餘,卻可以提升資料查詢的效率。但是,當應用程式基本上不通過內嵌模型查詢,或者說查詢效率的提升不足以彌補資料冗餘帶來的問題時,我們就應該考慮引用模型了。
當需要實現複雜的多對多關係的時候,可以考慮引用模型。比如我們熟知的例子,學生-課程-老師關係,如果用引用模型來實現三者的關係,可能會比內嵌模型更清晰直觀,同時會減少很多冗餘資料。
當需要實現複雜的樹形關係的時候,可以考慮引用模型。
四、應用場景分析
1、MongoDB的應用場景
1)表結構不明確且資料不斷變大
MongoDB是非結構化文件資料庫,擴充套件欄位很容易且不會影響原有資料。內容管理或者部落格平臺等,例如圈子系統,儲存使用者評論之類的。
2)更高的寫入負載
MongoDB側重高資料寫入的效能,而非事務安全,適合業務系統中有大量“低價值”資料的場景。本身存的就是json格式資料。例如做日誌系統。
3)資料量很大或者將來會變得很大
Mysql單表資料量達到5-10G時會出現明細的效能降級,需要做資料的水平和垂直拆分、庫的拆分完成擴充套件,MongoDB內建了sharding、很多資料分片的特性,容易水平擴充套件,比較好的適應大資料量增長的需求。
4)高可用性
自帶高可用,自動主從切換(副本集)
不適用的場景
1)MongoDB不支援事務操作,需要用到事務的應用建議不用MongoDB。
2)MongoDB目前不支援join操作,需要複雜查詢的應用也不建議使用MongoDB。
2、關係型資料庫和非關係型資料庫的應用場景對比
關係型資料庫適合儲存結構化資料,如使用者的帳號、地址:
1)這些資料通常需要做結構化查詢,比如join,這時候,關係型資料庫就要勝出一籌
2)這些資料的規模、增長的速度通常是可以預期的
3)事務性、一致性
NoSQL適合儲存非結構化資料,如文章、評論:
1)這些資料通常用於模糊處理,如全文搜尋、機器學習
2)這些資料是海量的,而且增長的速度是難以預期的,
3)根據資料的特點,NoSQL資料庫通常具有無限(至少接近)伸縮性
4)按key獲取資料效率很高,但是對join或其他結構化查詢的支援就比較差
相關推薦
Mysql和MongoDB效能對比及應用場景分析
一、前言 為什麼調研MongoDB? 下圖是DB-Engines2017年8月資料庫的排名統計,可以看到MongoDB總排名在第5,在Nosql資料庫中排名第1。 優點: 1)社群活躍,使用者較多,應用廣泛。 2)MongoDB在記憶體充足
Mysql和Mongodb的區別與應用場景對比
寫入 通過 原子 love 區別 擴展 屬於 這樣的 管理 MySQL是關系型數據庫 優勢: 在不同的引擎上有不同 的存儲方式。 查詢語句是使用傳統的sql語句,擁有較為成熟的體系,成熟度很高。 開源數據庫的份額在不斷增加,mysql的份額頁在持續增長。 缺點: 在海量數據
關於debounce和throttle的區別及應用場景
scroll NPU str win 兩種 區別 個人 沒有 tro 電梯超時 想象每天上班大廈底下的電梯。把電梯完成一次運送,類比為一次函數的執行和響應。假設電梯有兩種運行策略 `throttle` 和 `debounce` ,超時設定為15秒,不考慮容量限制。 thro
TCP和UDP的區別及應用場景
面試題回答: TCP和UDP的區別 (1)TCP是面向連線的,udp是無連線的即傳送資料前不需要先建立連結。 (2)TCP提供可靠的服務。也就是說,通過TCP連線傳送的資料,無差錯,不丟失,不重複,且按序到達;UDP盡最大努力交付,即不保證可靠交付。 並且因為tcp可靠,面向連線,不會丟
從MySQL和MongoDB的對比,看SQL與NoSQL的較量
作者介紹 張家江,網易樂得高階工程師。 貴金屬(注:貴金屬為筆者部門業務)的行情繫統提供的介面通過Redis獲取資料,目前使用Redis最多隻儲存了大概8000條左右的分鐘k的行情資料,考慮到將來可能會有更大資料量的查詢需求,需要查詢幾月甚至幾年的行情資料,要求資料庫在提供功能的同時又能保證效能和穩
二叉樹的前序中序和後續遍歷及應用場景
二叉樹的結構定義 public class TreeNode { int val = 0; TreeNode left = null; TreeNode right = null; public TreeNode(int val) {
藍芽協議中LQ和RSSI的原理及應用場景
本文轉自http://www.wowotech.net 在藍芽協議棧的物理層,有這樣兩個比較有用的引數:LQI和RSSI。它們都是通過接收端,判斷當前無線環境的質量(鏈路質量),以指導後續的動作。但這兩個數值的計算原理和使用場景又有很大的差別。 LQI (Link Qua
MyISAM引擎和InnoDB引擎介紹及應用場景
# 如果你的MySQL服務包含InnoDB支援但是並不打算使用的話, # 使用此選項會節省記憶體以及磁碟空間,並且加速某些部分 #skip-innodb =======================================================================
Flask框架鉤子函式使用方式及應用場景分析
Flask框架鉤子函式使用方式及應用場景分析 在正常執行的程式碼前中後,強行插入執行一段你想要實現的功能的程式碼,這種函式就叫做鉤子函式。鉤子函式就是等同於高速公路上的收費站,進高速之前給你一個卡,並檢查你是否超重。離開之前收你,也可以攔住你安檢一下。 一. 基礎概念:
Rocksdb的優劣及應用場景分析
轉載:https://www.jianshu.com/p/73fa1d4e4273研究Rocksdb已經有七個月的時間了,這期間閱讀了它的大部分程式碼,對底層儲存引擎進行了適配,同時也做了大量的測試。在正式研究之前由於對其在本地儲存引擎這個江湖地位的膜拜,把它想象的很完美,深入摸索之後才發現現實很骨感,光鮮背
ZeroMQ簡介及應用場景分析
1ZeroMQ概述ZeroMQ是一種基於訊息佇列的多執行緒網路庫,其對套接字型別、連線處理、幀、甚至路由的底層細節進行抽象,提供跨越多種傳輸協議的套接字。ZeroMQ是網路通訊中新的一層,介於應用層和傳輸層之間(按照TCP/IP劃分),其是一個可伸縮層,可並行執行,分散在分散
AngularJs與ReactJS優劣及應用場景分析
優點 AngularJS是一套完整的框架,angular有自帶的資料繫結、render渲染、angularUI庫,過濾器,directive(模板),服務q(defer),http,inject(依賴注入),factory,provider……,等等一系列
Docker五種存儲驅動原理及應用場景和性能測試對比
Docker 存儲驅動 Docker最開始采用AUFS作為文件系統,也得益於AUFS分層的概念,實現了多個Container可以共享同一個image。但由於AUFS未並入Linux內核,且只支持Ubuntu,考慮到兼容性問題,在Docker 0.7版本中引入了存儲驅動, 目前,Docker支持AUFS
面試被問之-----sql優化中in與exists的區別 Mysql中 in or exists not exists not in區別 (網路整理) Sql語句中IN和exists的區別及應用 [筆記] SQL效能優化 - 避免使用 IN 和 NOT IN
曾經一次去面試,被問及in與exists的區別,記得當時是這麼回答的:''in後面接子查詢或者(xx,xx,xx,,,),exists後面需要一個true或者false的結果",當然這麼說也不算錯,但別人想聽的是sql優化相關,肯定是效率的問題,只是那個時候確實不知道它們在sql優化上的區別,只知道用in會進
memcache和redis、Mongodb優缺點及應用場景
1.mongodb 埠(27017) (1)是文件型的非關係型資料庫,使用bson結構。其優勢在於查詢功能比較強大,能儲存海量資料,缺點是比較消耗記憶體。 (2)一般可以用來存放評論等半結構化資料,支援二級索引。 適合儲存json型別資料,不經常變化。 優點: l
PHP(Mysql/Redis)消息隊列的介紹及應用場景案例--轉載
接收 根據 好友 學習 range nod 存取 情況下 ble 鄭重提示:本博客轉載自好友博客,個人覺得寫的很牛逼所以未經同意強行轉載,原博客連接 http://www.cnblogs.com/wt645631686/p/8243438.html 歡迎訪問 在進行網站設計
mongodb入門-關系型RDMS數據庫對比及適用場景
lock 地理位置 發表 get 簡單的 標記 商業智能 過期 set 引言 最近工作接觸到了mongodb數據庫,記錄下個人對其的理解和使用情況。雖然mongodb 出來的時間已經不短,但是相對mysql mssql oracle 這樣傳統的關系型數據庫來說還是比
applyMiddleware原理和middleware中介軟體原理及應用場景
首先看下redux執行流程: redux設計思想: (1)Reducer:純函式,只承擔計算 State 的功能,不合適承擔其他功能,也承擔不了,因為理論上,純函式不能進行讀寫操作。 (2)View:與 State 一一對應,可以看作 State 的視覺層,也
MySQL(表鎖)、PHP(檔案鎖)鎖機制及應用場景
模擬高併發訪問一個指令碼:apache安裝檔案的bin/ab.exe可以模擬併發量 C:\phpStudy\Apache\bin>ab.exe -c 10 -n 10 http://localhost/try.php // -c 模擬多少併發量 -n 一共請求多少次 http://請求的指令