Spark系統執行內幕機制迴圈流程
一、TaskScheduler原理解密
1.DAGScheduler在提交TaskSet給底層排程器的時候是面向介面TaskScheduler的,這符合面向物件中依賴抽象而不依賴的原則,帶來底層資源排程器的可插拔性,導致Spark可以執行的眾多資源排程器模式上,例如Standalone、Yarn、Mesos、Local、EC2、其它自定義的資源排程器。在Standalone的模式下,我們聚焦於TaskSchedulerImpl
2.在SparkContext例項化的時候通過createTaskScheduler建立TaskSchedulerImpl和SparkDEploySchedulerBackend:
case SPARK_REGEX(sparkUrl)=>
val scheduler = new TaskSchedulerImpl(sc)
val masterUrls=sparkUrl.split(",").map("spark://"+_)
val backend=new SparkDeploySchedulerBackend(scheduler,sc,masterUrls)
scheduler.initialize(backend)
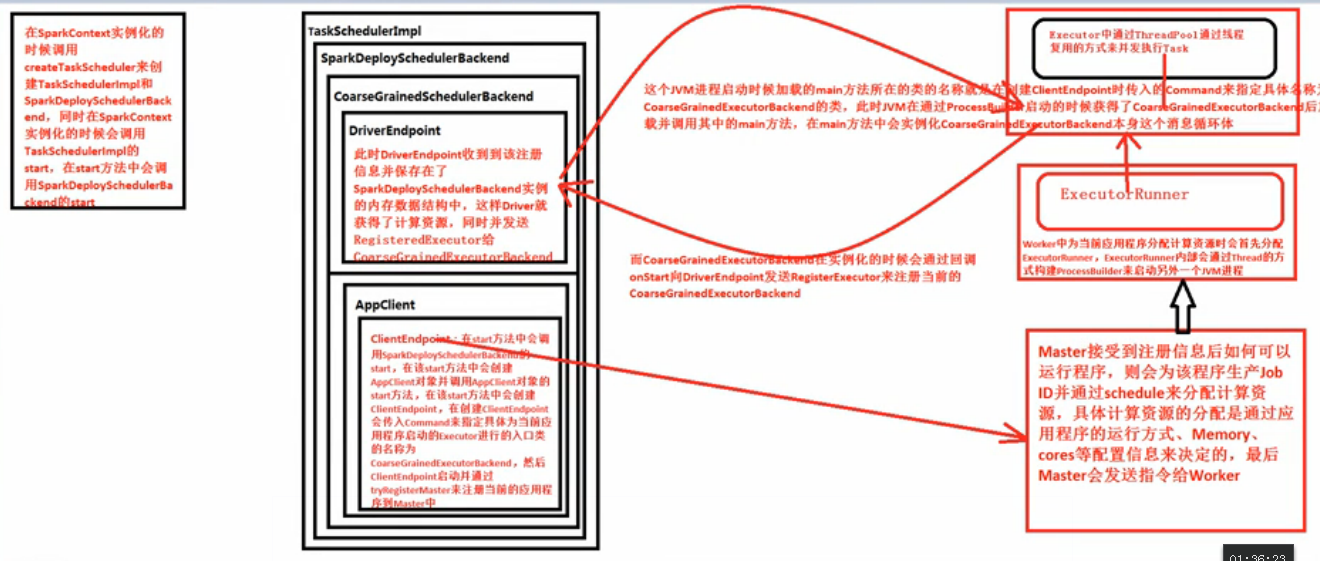
(backend,scheduler)在TaskSchedulerImpl的initialize方法中把SparkDeploySchedulerBackend傳進來從而賦值為TaskSchedulerImpl的Backend;在TaskSchedulerImpl呼叫start方法的時候回撥用backend.start方法,在start方法中會最終註冊應用程式
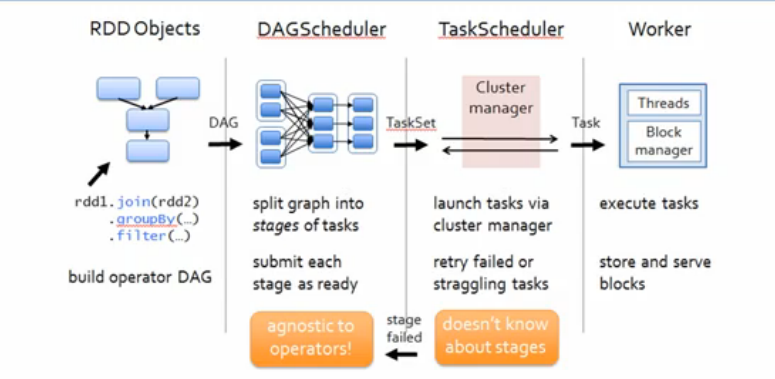
3.TaskScheduler的核心任務是提交TaskSet到叢集運算並彙報結構
a)為TaskSet建立和維護一個TaskSetManager並追蹤任務的本地性以及錯誤資訊;
b)遇到Straggle任務會放到其它的節點進行重試
c)向DAGScheduler彙報執行情況,包括在Shuffle輸出lost的時候報告fetch failed錯誤等資訊
4.TaskScheduler內部會握有SchedulerBackend,從Standalone的模式來講具體實現是SparkDeploySchedulerBackend
5.SparkDeploySchedulerBackend在啟動的時候構造了APPClient例項並在該例項start的時候啟動了ClientEndPoint這個訊息迴圈體,ClientEndPoint在啟動的會向Master註冊當前程式;而SparkDeploySchedulerBackend的父類CoarseGrainedSchedulerBackend在start的時候會例項化型別為DriverEndPoint(這就是我們程式執行時候的經典物件Driver)的訊息迴圈體.SparkDeploySchedulerBackend專門負責收集Worker上的資源資訊,當ExecutorBackend啟動的時候會向DriverEndPoint註冊;此時SparkDeploySchedulerBackend就掌握了當前應用程式擁有的計算資源,TaskScheduler就是通過SparkDeploySchedulerBackend擁有的計算資源來具體執行Task
6.SparkContext,TaskSchedulerImpl,DAGScheduler,SparkDeploySchedulerBackend在應用程式啟動的時候只例項化一次,應用程式存在期間始終存在這些物件:
大總結:在SparkContext例項化的時候呼叫createTaskScheduler來建立TaskSchedulerImpl和SparkDeploySchedulerBackend,同時在SparkContext例項化的時候會呼叫TaskSchedulerImpl的start,在start方法中會呼叫SparkDeploySchedulerBackend的start,在該start方法中會建立APPClient物件並呼叫APPClient物件的start方法,在該start方法中會建立ClientEndPoint,在建立ClientEndPoint會傳入Command來指定具體為當前應用程式啟動的Executor進行的入口類的名稱為CoarseGrainedExecutorBackend,然後ClientEndPoint啟動並通過tryRegisterMaster來註冊當前的應用程式到Master中,Master接受到註冊資訊後如何可以執行程式,則會該程式生產Job ID並通過Schedule來分配計算資源,具體計算資源的分配是通過應用程式的執行方式、Memory、cores等配置資訊來決定的,最後Master會發送指令給Worker,Worker中為當前應用程式分配計算資源時會首先分配ExecutorRunner,ExecutorRunner內部會通過Thread方式構建ProcessBuilder來啟動另外一個JVM程序,這個 JVM程序啟動時候載入的main方法所在類的名稱就是在建立ClientEndPoint時傳入的Command來指定具體名稱為CoarseGrainedExecutorBackend的類,此時JVM在通過ProcessBuilder啟動的時候獲得了CoarseGrainedExecutorBackend後加載並呼叫其中的Main方法,在main方法中會例項化CoarseGrainedExecutorBackend本身這個訊息迴圈體,而CoarseGrainedExecutorBackend在例項化的時候會通過回撥onStart向DriverEndPoint傳送RegisterExecutor來註冊當前的CoarseGrainedExecutorBackend,此時DriverEndPoint收到該註冊資訊並儲存在了SparkDeploySchedulerBackend例項的記憶體資料結構中,這樣Driver就獲得了計算資源。