論文閱讀:《Deep Image Matting》CVPR 2017
概述
Adobe提出一種基於深度學習的新演算法,主要解決傳統方法中只有low-level features和缺乏high-level context的問題。深度模型分為兩個階段。第一階段是深度卷積編碼-解碼網路,該神經網路將原圖和對應的trimap作為輸入,並預測影象的alpha matte。第二階段是一個小型卷積神經網路,該網路對第一個網路預測的alpha matte進行精煉,從而擁有更準確的α值和銳化邊緣。此外,還建立了一個大規模摳圖資料集,該資料集包含 49300張訓練影象和1000張測試影象。深度模型+大規模資料集使之效果表現尤佳。
Motivation
方法的動機來源於傳統方法存在的兩個問題。
一是當前方法將摳圖方程設計為兩個顏色的線性組合,即將摳圖看做一個染色問題,這種方法將顏色看做是一個可區分的特徵。但是當前景和背景的顏色空間分佈重疊時,這種方法的效果就不是很好了。使用深度學習不首要依賴色彩資訊,它會學習影象的自然結構,並將其反映到alpha matte。
二是當前基於摳圖的資料集太小,alphamatting.com資料集只有27張訓練圖片和8張測試圖片,訓練出來的模型泛化能力較差。針對該問題,作者將前景摳出來,並放入到不同的背景下,從而構建一個大規模摳圖資料集。

網路結構
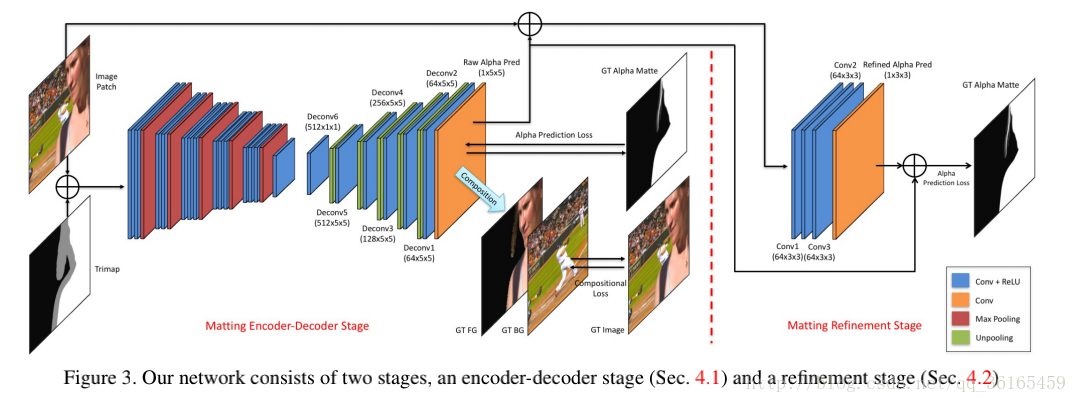
網路結構由兩階段組成,Matting encoder-decoder stage 和 Matting refinement stage.
Matting encoder-decoder stage
網路:輸入影象塊和對應的trimap,輸出是alpha預測。編碼階段是14個卷積層和5個池化層,得到低解析度的特徵圖,解碼階段是6個卷積層的小網路,5次unpooling得到原圖大小的alpha prediction.
Loss: 使用了兩個loss,第一個是alpha-prediction loss,是預測的alpha values 和ground truth的alpha values的絕對差。第二個loss是compositional loss,預測的RGB顏色值和對應的ground truth絕對差。兩個loss以0.5加權得到最終的loss。
實現
Matting refinement stage
網路:4個卷積層,輸入是影象塊和預測的alpha prediction。
實現:先訓練編解碼網路,待其收斂後用於更新refine網路,第二個網路只使用alpha-prediction loss。
總結
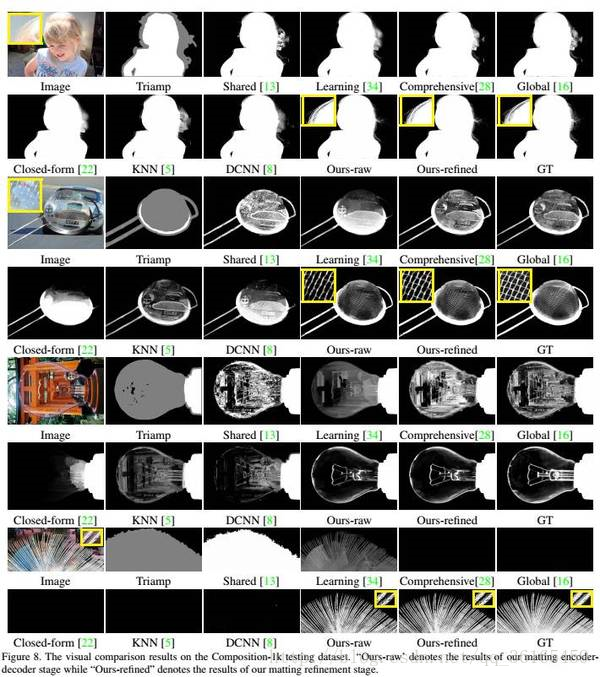
為了泛化到自然影象中,摳圖演算法必須超越以色彩為主要線索,並能利用更加結構性和語義性的特徵。論文中的神經網路有足夠的能力捕捉到高層次特徵(high-order features),並利用它們計算且提升摳圖效果。以下是一些論文中report的結果。