
論文閱讀-Learning Deep CNN Denoiser Prior for Image Restoration
Zhang K, Zuo W, Gu S, et al. Learning Deep CNN Denoiser Prior for Image Restoration[J]. 2017.
1.引言
影象恢復(image restoration,IR) ——從退化模型中恢復出乾淨的影象x
退化模型: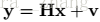
影象恢復有三種典型的任務,在影象去噪中,H是單位矩陣(identity matrix); 影象去模糊中,H的模糊運算元;影象超分辨中,H是下采樣和模糊的複合運算元。
從貝葉斯的角度分析,x的估計(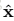
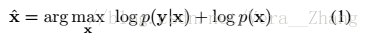
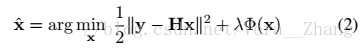
式(2)前半部分為保真項(fidelity firm),後半部分為正則項(regularization firm )。
為了解決式(2),一般有兩種方法,基於模型的優化方法和判別學習方法(discriminative learning methods),基於模型的優化方法例如NCSR,基於學習的方法L例如SRCNN、MLP等等,前者只需退化矩陣,後者需要訓練集和特定的退化矩陣;在此我的理解是,前者為傳統的影象處理演算法,後者為利用深度學習或者機器學習的影象處理演算法。這兩種方法都有各自的優缺點,如果能加以結合各自的優勢,可能會提高效果。幸運的是,已有變數分離技術( variable splitting technique),如ADMM(alternating direction method of multipliers
本文的目標在於訓練一系列快速高效的discriminative denoisers,並把它們用於基於模型優化的方法中,解決求逆問題。不使用MAP相關方法,而是使用CNN學習denoisers。
本文貢獻:
- 訓練出一系列CNN denoisers。使用變數分離技術,強大的denoisers可以為基於模型的優化方法帶來影象先驗。
- 學習到的CNN denoisers被作為一個模組部分插入基於模型的優化方法中,解決其他的求逆問題。
2.背景
以HQS方法為例,講解如何對保真項和正則項進行變數分離。
為了將denoiser先驗加入式(2)的優化操作,可行的變數分離操作通常是將保真項和正則項分解,在HQS方法中,引入附加變數z,等式(2)可被改寫為一個約束最優化問題:

用HQS方法求解式(4)則可寫為:
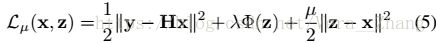
其中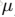
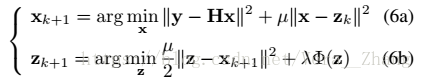
其中保真項在式(6a)中,正則項在式(6b)中,(6a)的解法如下:

(6b)可改寫為:

通過貝葉斯概率,式(8)可以看做處理影象高斯噪聲的問題,噪聲水平為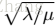

通過式(8)和式(9),影象先驗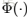
3.學習深度CNN去噪器先驗
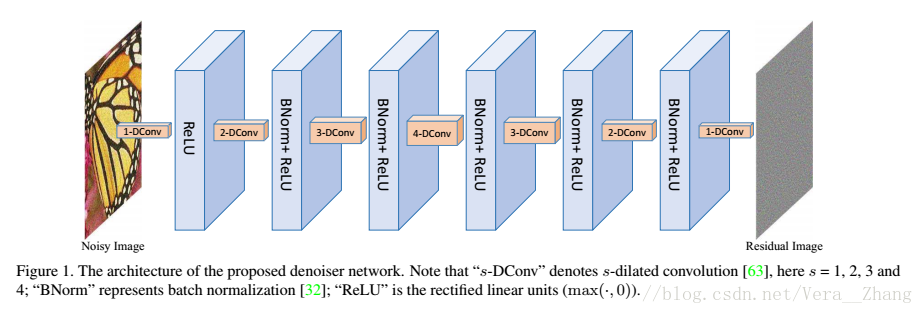
CNN去噪器模型如上圖,由七層組成,含三種blocks,分別是:第一個“dilated Convolution+Relu”,中間五個“dilated Convolution+BN+Relu”,最後一層“dilated Convolution”。其中空洞因子(dilated factors,3×3)被依次設定為,1,2,3,4,3,2,1。每一箇中間層的feature maps個數均為64.
下面給出本網路一些重要的設計和訓練細節。
- 使用dilated filter擴大感受野。在影象去噪任務中,背景資訊對重構受損畫素具有很大的作用。通過擴大CNN的感受野有兩個方法,一個是增大卷積核尺寸,另一個是加深卷積深度。而增大卷積核尺寸,不僅引入了更多變數,也增加了計算負擔,因此,最好的做法就是在現有的CNN設計中,使用深度更深的3×3卷積核。本文就是使用空洞卷積來平衡網路深度和感受野大小。空洞因子為s的空洞濾波器可以解釋為尺寸為(2s+1)×(2s+1)的稀疏濾波器,其中只有9個位置非零。因此,對應於各層的感受野分為別:3,5,7,9,7,5,3,因此,所提出的網路卷感受野為33×33(問題:怎麼得到的?).如果使用傳統的3×3濾波器,網路深度一定(如7),網路將會有一個15×15的感受野;或者感受野一定(如33×33),網路深度將為16。為了展示本文網路融合了以上兩種模型的優勢,基於噪聲水平25,在相同的訓練引數下,我們訓練了三個模型。
- 使用批標準化BN和殘差學習加速訓練。
- 使用小尺寸訓練樣本避免邊界效應。
- 學習噪聲水平間隔較小的特定的去噪模型。