
【野火®】i.MX RT1052評測——移植RT-Thread
跨界處理器
i.MX RT1052是i.MX RT系列晶片,是由 NXP 半導體公司推出的跨界處理器晶片,該系列下又包括i.MX RT1020、i.MX RT1050及 i.MX RT1060等子系列晶片。所謂“跨界”,是指它自身的定位既非傳統的應用處理器也非傳統的微控制器。
傳統的應用處理器如手機主控晶片,它們通常採用 ARM 的 Cortex-A系列核心,配合
其晶片架構使得晶片能實現更高頻率的執行。傳統的微控制器也稱為 MCU,它們通常採用
ARM 的 Cortex-M 系列核心,相對來說該核心對中斷響應更快,所以具有良好的實時性,
但其晶片架構特別是整合片內快閃記憶體帶來了生產技術限制和成本負擔,從而限制了其效能。
而i.MX RT 系列晶片集成了兩者的優點,它基於應用處理器的晶片架構,採用了微控制
器的核心 Cortex-M7,從而具有應用處理器的高效能及豐富的功能,又具備傳統微控制器
的易用、實時及低功耗的特性。
野火i.MX RT1052
野火的i.MX RT1052核心板搭載了i.MX RT1025DVL6A晶片,Cortex-M7核心,主頻高達600M。130個IO全部引出。整合32MB SDRAM、128MB NAND FLASH、32MB QSPI FLASH、2Kb EEPROM、LCD-RGB565 FPC介面、1個SWD除錯介面、 1個uart 除錯介面、1個電源LED、1個使用者LED、
底板圖片如下:

裝在mini底板上的效果圖,哎,傑傑還是很羨慕Pro底板的,資源豐富。連LCD都能放在板子上,而我的LCD就只能通過排線弄出來。

看看火哥核心板的風騷走線:

頂層

底層
這些走線騷氣得一批,不過很多訊號線都採用等長走線,保證了訊號的穩定性,這個值得點贊!!!
i.MX RT1052的效能
介紹一下i.MX RT1052晶片的效能優點吧:
無需片內快閃記憶體
由於跨界處理器採用了應用處理器架構,具有大幅縮小的
高效能
具備高密度片內 TCM 或快取的跨界處理器的快取未命中率可低至 1-2%,因此能夠提供明顯高於 MCU 的有效效能。
低中斷延遲
在協調對內部和外部硬體事件做出及時響應方面,中斷在嵌入式系統中發揮了重要作用。在與使用者互動的實時系統中,它們發揮的作用尤其重要,這是因為由使用者輸入觸發的外部事件需要 CPU 做出可靠的低延遲即時響應。跨界處理器採用 MCU 核心構建,因此即使它們採用應用處理器架構,也延續了低中斷延遲這一重要特性。跨界處理器的中斷延遲最低可達到 10-20ns,而應用處理器的延遲通常長達 1毫秒。
高能效以及安全性。
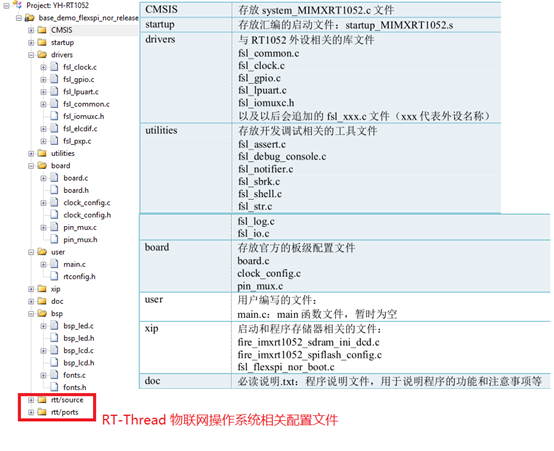
野火i.MX RT1052工程
下面來說說韌體庫寫的工程吧,按照火哥一貫舒服的程式碼風格
而且工程中含有不同版本的工程
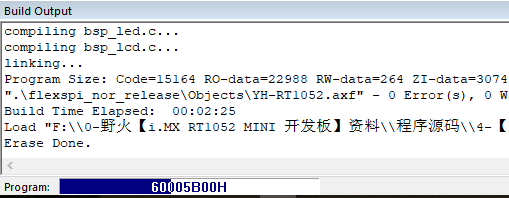
正常來說,我們寫程式碼不可能一次成功的,需要除錯很久才出結果,可以通過ram_debug或者sdram_debug版本將程式快速載入到我們的開發板上的RT1052 晶片的內部 RAM 中或者是板載的SDRAM 晶片中,實現快速除錯程式碼,但是RAM 空間小,適用於小程式除錯,而板載的sdram則有32MB的空間,適用於大程式的除錯。但是掉電則丟失這些程式,無法用在產品上,僅做除錯用。
而下面兩個版本,則可以作為產品的最終程式碼,將程式下載到NOR FLASH中,但是下載速度較慢,而且執行速度較SDRAM慢,傑傑猜測,我們或許應該可以將程式寫為兩段,在釋出產品的時候,從NOR FLASH啟動,執行NOR FLASH的第一段程式,將存在NOR FLASH的第二段程式載入到SDRAM/SRAM中執行,直到掉電。這樣子就能提高速度了吧。
前面的前三個模式均採用低優化等級(-O0)優化,而_flexspi_nor_release版本則採用高優化(-O3)等級,以便節約程式空間,提高執行效率。(傑傑吐槽:就是編譯有點久)。
溫馨提示:如果不用mdk看程式碼的話,可以去掉“魔術棒”->Output -> Browse Information的√。然後可以使用source insight看程式碼,方便很多,至少比mdk好多了。
下個程式碼欣賞欣賞。
RT-Thread物聯網作業系統
野火i.MX RT1052的程是移植了RT-Thread物聯網作業系統的(還是要支援一下國產的作業系統的),來看看原始碼吧。
先介紹介紹RT-Thread物聯網作業系統(以下簡稱rtt),作業系統是輕量級的,利用很小的資源完成實時作業系統的工作。
這些就是rtt的一些檔案,bsp就是一些板級相關的東西,components就是一些元件,看英文單詞都知道啦。然後就是src就是rtt的實現的原始碼,include就是一些標頭檔案,而libcpu就是一些晶片的支援,tools就是一些rtt的工具,example還不會的別學嵌入式了。。。。。
看原始碼確實是一個很輕量級的作業系統,移植起來也是很簡單,重點是火哥已經幫我們移植好啦,直接用吧,傑傑在學校rtt的過程中,發現跟一些作業系統還是有點不一樣的,他的啟動方式就在啟動檔案已經做好了。來看看:
在components.c中的148行:
1/* re-define main function */
2int $Sub$$main(void)
3{
4 rt_hw_interrupt_disable();
5 rtthread_startup();
6 return 0;
7}
先關中斷,再做rtt的啟動
1int rtthread_startup(void)
2{
3 rt_hw_interrupt_disable();
4 /* board level initalization
5 * NOTE: please initialize heap inside board initialization.
6 */
7 rt_hw_board_init();
8 /* show RT-Thread version */
9 rt_show_version();
10 /* timer system initialization */
11 rt_system_timer_init();
12 /* scheduler system initialization */
13 rt_system_scheduler_init();
14#ifdef RT_USING_SIGNALS
15 /* signal system initialization */
16 rt_system_signal_init();
17#endif
18 /* create init_thread */
19 rt_application_init();
20 /* timer thread initialization */
21 rt_system_timer_thread_init();
22 /* idle thread initialization */
23 rt_thread_idle_init();
24 /* start scheduler */
25 rt_system_scheduler_start();
26 /* never reach here */
27 return 0;
28}
裡面有一些函式是我們自己實現的,比如開發板初始化:rt_hw_board_init,
rtt還是有點好玩的,對外開放了main嘛!我們一般寫程式都在main.c中,所以,它又搞了個main_thread_entry執行緒(其實我更喜歡把這些稱作任務,不過都一樣啦,既然學了rtt,那就跟官方叫吧)
1void main_thread_entry(void *parameter)
2{
3 extern int main(void);
4 extern int $Super$$main(void);
5 /* RT-Thread components initialization */
6 rt_components_init();
7 /* invoke system main function */
8#if defined (__CC_ARM)
9 $Super$$main(); /* for ARMCC. */
10#elif defined(__ICCARM__) || defined(__GNUC__)
11 main();
12#endif
13}
這個函式是跳轉到我們的main.c中的main。下面才是真正實現我們的程式碼的地方。
由於前面說了,rtt啟動的時候,會將開發板相關資源初始化,所以,我們自己的main就不需要再初始化了,直接開啟rtt的執行緒的建立與啟動。
1lcd_thread = rt_thread_create("lcd",
2 lcd_thread_entry,
3 RT_NULL,
4 LCD_THREAD_STACK_SIZE,
5 LCD_THREAD_PRIORITY,
6 LCD_THREAD_TIMESLICE);
7 if (lcd_thread != RT_NULL) //建立成功
8 rt_thread_startup(lcd_thread); //啟動執行緒
9 else
10return -1;
11相關巨集定義:
12#define LCD_THREAD_PRIORITY 13 /* 優先順序,數值越大,優先順序越低 */
13#define LCD_THREAD_STACK_SIZE 1024 /* 執行緒棧大小,單位為位元組 */
14#define LCD_THREAD_TIMESLICE 5 /* 執行緒時間片,單位為tick */
i.MX RT1052性能測試
既然是評測,當然得有效能的評測啦,一段使用(-O0)低階優化的整形數計算,在野火i.MX RT1052板載的SDRAM上僅跑了21.487秒。在STM32H743上面跑了21.479秒(400M的工作頻率,開啟CaChe(快取記憶體)),而在stm32f103zet6上跑了9分57秒多。效能可見一斑了吧???如果不信可以自行測試,我可是等了幾分鐘就去刷牙了,回來還沒跑完。。。。。
測試程式碼如下:(來源網路的測試程式碼)
1void Calculate()
2{
3 unsigned long x;
4 unsigned long a;
5 a=1;
6 for(x=0;x<4294967294;x++)
7 {
8 a=a+1;
9 }
10}
測試結果對比:
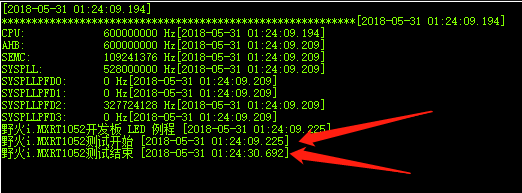
i.MX RT1052
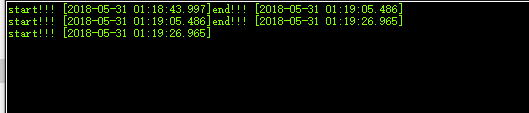
STM32H743

stm32f103zet6
在效能上面,i.MX RT1052,估計是一般mcu無法跨越的存在了,效能真的是超級強悍的。看文章的網友可能有疑問了,明明400M主頻的H7比1052快啊,在此傑傑回答一下,1052是在外部SDRAM上的程式,而H7在片內記憶體上,而且H7開了cache,能不快嗎,如果這點小程式在1052的SRAM存上跑,絕對也能飛起。。。。。而且重要的是工業級的1052僅需3.8美金,很便宜了。
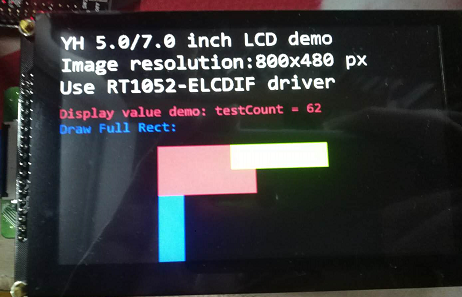
據火哥測試,i.MX RT1052的刷屏速度也很快,1366*768解析度的螢幕可以達到52HZ,而1280*800的螢幕則達到了60HZ,70MHZ左右的VCLK時鐘,佔用SDRAM的50%左右的資料吞吐量。

想要了解更多1052相關的東西,歡迎與傑傑聯絡
本次測試完結。

