
靠“喂喂喂”來測試實時語音質量靠譜嗎?
以下是由陳若非博士,在RTC2016 實時網際網路大會上的演講實錄
陳若非,現在任職聲網Agora.io的音訊技術,負責整個音訊技術架構。在香港城市大學讀博士期間是音訊方面的諸多重要會議和期刊的主編。這位同學在以前的工作經驗裡積累了大量關於音訊的降噪、混合、雙麥等等這方面的工作經。

大家下午好,很高興今天有機會和大家分享一下:讓我們的APP實現實時語音功能時,我們需要做哪些測試?要怎麼樣做這些測試才能保證上線後是穩定沒有問題的。
有的開發者說,他們自己做了實時語音的功能,在自己的測試中覺得沒有問題,在公司測得都很好,也通過了。上線後,收到很多使用者反饋:為什麼你的語音這麼卡,為什麼有回聲,為什麼會有雜音?。他們才發現這些問題其實並不是這麼容易定位的,也不能像平時我們解BUG那樣快速修復這樣的問題。再追溯回來他們發現這背後跟很多網路相關的優化、音訊底層的演算法都有很大的關係,這一塊他們自己也解決不了,所以就會出現比較尷尬的局面。所以,希望在今天的演講之後可以給大家一些更豐富的手段,幫助大家去評估一下自己手裡的音訊引擎效果是怎麼樣的。
首先,我們來講講實時語音的發展。我相信大家對實時語音這樣的功能應該比較瞭解。實時語音發展已經有幾十年的歷史,近幾年越來越多的APP提供了這個功能,包括微信、陌陌。越來越多的使用者願意使用實時語音功能,從側面說明一個問題,實時語音這個功能已經達到可以商業化的地步了。
這背後,我們這兩年網路基礎設施的升級,智慧終端裝置的更新換代,包括現在流行的WebRTC技術的快速發展,都為實時語音野蠻省長提供非常肥沃的土壤。我們非常高興地看到,除了社交之外,遊戲、直播、線上醫療、線上教育這些行業對實時語音需求都是非常強烈。
那麼問題來了,當我們有一個語音引擎在手裡,我們已經調通了,出聲了,到上線究竟還有多遠?這個問題其實是見仁見智的。我們跟一些開發者打交道下來,聽到比較多的兩種聲音是:我現在就想做視訊應用,看臉的世界,出聲就可以;還有一種,我覺得音訊很重要,但是我不知道怎麼測?我要如何來做測試才能保證上線後的穩定?要回答這兩個問題我們首先來看一下我們實時語音到底有哪些特徵?
實時語音到底有哪些特徵?
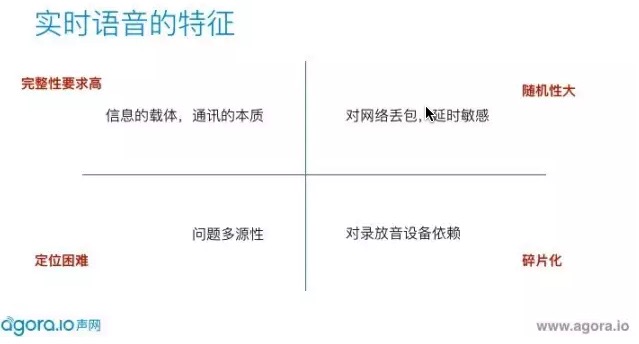
首先,實時語音的完備性要求非常高。我們不可否認語音是溝通的本質,是資訊的載體。如果我們在通話中語音資訊丟失了,這個對話是根本不能繼續下去的。這實際上說明了,我們首先對實時語音的完備性要求是非常高的,而且使用者對這部分的音訊問題容忍度是非常低的。
第二,實時語音其實是隨機性很大。我們要做基於網際網路的實時語音,也決定了我們繞不開網路的丟包、延時的問題,所以這部分又決定了實時語音其實是隨機性很大的。
第三,問題的多元性。這個問題怎麼解釋?舉個例子,大家平時有人會給你報你的語音卡頓,到底是什麼原因?你首先想到的肯定是網路,網路會卡頓。其實還有別的原因會引起卡頓,比如裝置CPU負荷很高時,錄放音排程有問題,也會導致聲音的卡頓。更隱性的問題,比如回聲消除,兩個人同時說話時,這邊開著外放,收回去的時候兩個聲音混在一起,過程中會有損傷,造成斷續。通過這些例子,可以想見,實時語音的問題很難去定位。
最後,對錄放音裝置的依賴。我們每個人都有自己的嘴和耳朵,裝置也一樣,有揚聲器和麥克風,而且它還有更多的外設。所以,其實最後的聽感體驗很大程度受到錄放音裝置的制約,這也決定了音訊的問題其實是碎片化的。
我們可以看到,這四個問題其實都是很難搞的問題,這也決定了用喂喂喂或者簡單幾次測試不可能很好覆蓋整個音訊測試。
來總結一下,我們這裡把影響語音質量的因素分為三類:
網路問題:丟包,或者抖動,都會導致聽感滯後或者斷續;
裝置問題:很突出,在一些低端的安卓機上,聲學設計並不理想。揚聲器之間的耦合很大,或者揚聲器的非線性很大,導致你的演算法不能很好貫通在上面,導致聽感上有一些卡頓、毛刺的問題。
物理環境:比如我在一個很吵的環境和你打電話,或者我在很小的房間跟你打電話感覺是不一樣的;還有遠場拾音,比如做電視應用,必須要在2米以外收音,這個時候麥克風的拾音效果決定了音訊聽到的體驗。
這麼多複雜的問題,業界一般怎麼處理?
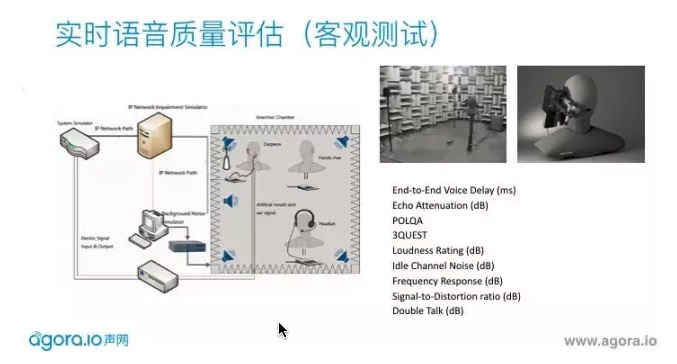
手機公司會有很大的消聲室,是用來規避一些不確定外界聲源的影響。還需要有人工頭、人工嘴和人工耳做高保真的放音和收音,四周有高保真的音響放出自由場的噪聲源,模擬不同網路狀況。會測試回聲,語音在乾淨或噪聲環境下的得分,雙降的效能。每個手機出場之前都會做這樣的測試。
但這一般開發者來說門檻很高,這樣一套裝置很貴,我們有沒有更經濟合理的方法做測試?
我們也總結了一下,聲網在實踐中覺得比較適合開發者自己去做,在上線前自測的一些方法,這裡也按我們之前提到的三個歸類,網路、裝置和物理環境講一下。
首先,網路部分。
這裡面可能不能涵蓋所有的丟包,但是基本上也能測到語音在不同丟包下的表現,可以測到引擎的極限在哪裡。聲網的引擎基本現在做到在TC下,30%的丟包是無感的,70%的丟包可以正常的通話。
還有一個比較重要的是:跨運營商的測試。這一點很多客戶是不重視的,自己在公司內用P2P測覺得很好,一上線就有很多問題。在中國,跨運營商的丟包,或者2G、3G、4G行動網路下會有很多問題,建議大家在這方面做足夠測試再上線。
其次,裝置的問題。
大家在一些平板電腦測試覺得聲學很好,調的也很好,底層也有演算法。但是,到安卓之後就變得非常的麻煩。很多低端的安卓機,底層錄音的通路沒有調好,底噪很大。而且,聲學設計不夠好,有很多非線性的問題需要適配。而這些問題如果只是在一個比較高階的機器上測,可能是不會體現的。所以,如果你的目標使用者中有很多這樣的機型,那麼一定要在測試中把這一塊覆蓋好。同時,在聽筒、耳機、外放、藍芽,也需要去測,這些都是會影響使用者的體驗的細節。、
第三,物理場景。
我們其實沒有辦法覆蓋非常多的場景,建議去下載一些語音降噪的序列、噪聲的序列,是免費的,可以在不同的信噪比情況下用來測試。遠場拾音,只要測一下不同的說話距離就能感覺到不同的體驗。
我相信通過這三步的測試,你的語音引擎是基本可用的。
另外,稍微講一下一些技術細節。

我們常說的3A引擎是指:回聲消除、降噪和自動增益控制,這是所有音訊引擎中必須有的模組。在測回聲時,需要留意降完回聲之後殘留的程度;雙講透明度,就是兩個人同時說話的時候會有多少聲音可以透過去;穩定性是指在安卓上這些CPU比較高的情況之下可以穩定執行的一個時間,收斂時間。 降噪,我降噪完聲音的殘留噪聲的程度和收斂時間。自動增益控制關注兩個點,第一收音距離多遠,第二,你把聲音推大,雜音也會推大,這個部分有沒有做特殊的處理?不然有人會說,你的這個聲音是很大,但是背景音一起推起來了,這時需要一些演算法來做的更好。如果在1米、2米情況下不用AGC聲音已經非常小,這裡面必須有演算法支援它。

上圖的三個演算法也是比較特殊場景下的演算法,聲網在這三塊也做了比較多的工作。
可懂度增強:如果我在很噪雜的環境,對方傳過來的聲音是不吵的,但是我聽著還是很累,因為我旁邊有很多讓我分心的聲音。這個時候,我們需要去評估現在的環境下的有多噪雜,從而調整下行的訊號讓你聽得更清楚。
盲源分離:指的是我們剛才的降噪說得是平穩噪聲,對應在數學上也是用統計模型來做。但是在非平穩訊號下,可能需要有多麥技術來定位主講人聲源在哪,主要收主講人的聲音,其他的聲音遮蔽。
嘯叫抑制:真實環境中並不是很多。在做音訊測試時,如果兩個手機開著外放,你就會聽到很尖銳的雜音一直響。這怎麼辦?其實很簡單,只要把一臺插上耳機,把迴環的通路打斷就不會叫。聲網自己做了嘯叫抑制的模組,兩個手機都外放,即使不插耳機,我們也會把檢測到的尖銳雜音自動壓下來。
如果做的應用是比較特殊的場景,比如直播、遊戲,我們還有特殊的點需要注意。
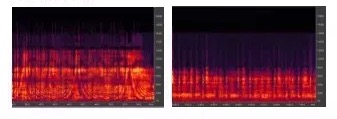
做直播,推流基本用44.1K,但聲音有效取樣取到多少才是真正重要的。左圖是32K的取樣,右圖那個雖然是44.1K的聲源,但其實有效頻率是8K,實際聽到的聲音會變悶的。
ASMR,就是用立體聲錄音去給聽眾聽到空間感的音訊。那聲網在手機平臺上,第一個做到立體聲錄音和播放。這意味著,主播可以現在拿著這個立體聲的裝置走到街上,一輛車開過去,其實直播的聽眾戴了耳機就能感覺到從左到右的效果。
再講一下游戲,很特殊的場景。拿一個槍戰類的遊戲舉例,在3D環境裡可以聽到周圍有隊友開槍,可以聽到哪邊交火。如果玩家開了實時語音,自己開著外放。那麼玩家開槍的聲音通過他的外放再被收回去,這部分回聲消除由於沒有參考訊號就做不了。這個聲音傳過去會影響對方的判斷,直接降低玩家的遊戲體驗。
上線只是一個開始,上線之後,語音的碎片化問題還會不斷出現。那麼就需要做兩方面的統計。
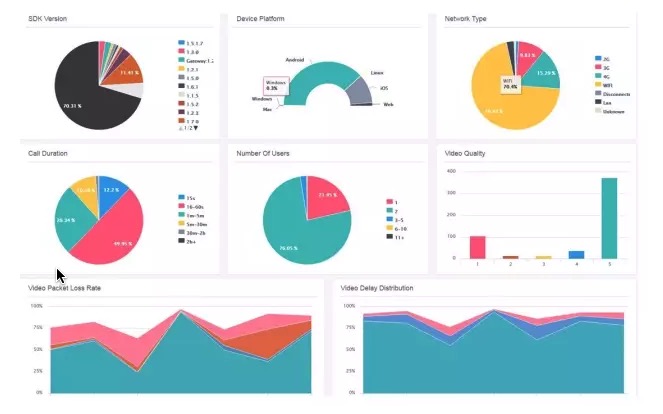
全域性監控。來反饋全域性質量,是不是大部分使用者都比較好?上圖是聲網做的一個統計,反應每天使用使用者大概比例,用什麼網路什麼系統,音訊視訊打分如何,丟包率如何?如果你不是使用聲網的服務,你自己也需要做這樣一套系統,來改進服質量 。
個例分析。全域性反饋良好,但依然有使用者報問題,我的聲音聽不到怎麼辦?聲網在實踐當中做了這樣一套系統,可以根據使用者ID去查詳細的通話資訊:包括一些位元速率、CPU的情、音訊錄音大小可以自己看得到,這樣子就能定位問題。
以下是現場提問
提問:我問一個關於降噪的問題,你剛才的演示PPT裡面沒有很清楚,降噪之後背景噪聲是消除越乾淨越好?還是應該是有一定的率?
陳若非:降噪有一個很大的問題,你壓得越多噪聲越低,語音失真也越大,這是必然的。如果你有一個噪音,失真率很小,如果壓得很多,非常乾淨,這個聲音訊率上會特別高,聽起來尖尖的,不是很舒服。所以這需要你在實踐中自己去調到一個你認為最好的點,沒有絕對,我不知道這樣回答有沒有回答你的問題?