
SRILM使用之訓練無平滑語言模型
阿新 • • 發佈:2019-02-12
【語料準備】
訓練語料
wget http://idiom.ucsd.edu/~rlevy/teaching/2015winter/lign165/lectures/lecture13/toy-example/corpus.txt測試語料
wget http://idiom.ucsd.edu/~rlevy/teaching/2015winter/lign165/lectures/lecture13/toy-example/test_corpus.txt訓練語料內容
$ cat corpus.txtdogs chase cats
dogs bark
cats meow
dogs chase birds
cats chase birds
dogs chase the cats
the birds chirp
【計數檔案生成】 此步在實際應用中不需要
ngram-count -text corpus.txt -order 2 -write1 corpus_1gram.count -write2 corpus_2gram.count將計數檔案分別輸出到1-gram檔案和2-gram檔案
【模型檔案生成】
ngram-count -text corpus.txt -debug 2 -order 2 -addsmooth 0 -lm corpus.lm這裡使用-addsmooth 0 引數,使模型不進行平滑處理
對模型檔案的分析 此處省略了一些資料,詳見excel
第1部分
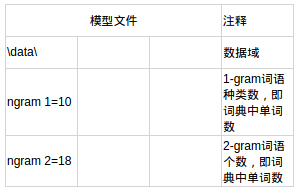
第2部分
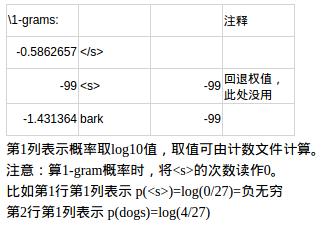
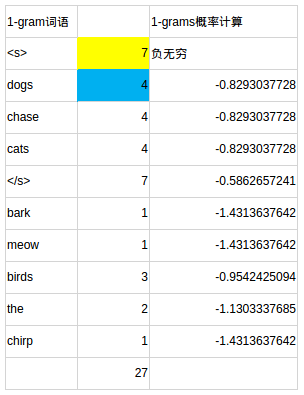
第3部分

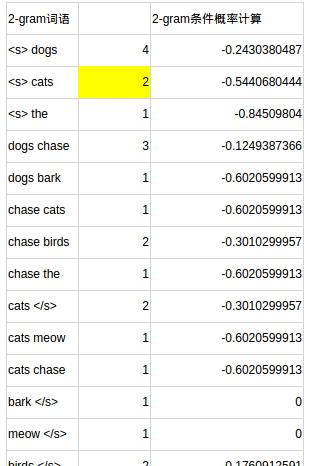
【計算測試檔案困惑度】
ngram -lm corpus.lm -ppl test_corpus.txt -debug 2
其中:每一行代表可以從lm檔案中查到的條件概率,第1列概率表示,第2列說明是幾元條件概率,第3列概率值,第4列為概率值取對數。
logprob為整個句子的概率,它是由所有行概率值相加得到的。
ppl為困惑度,它是由公式10^-logprob/(#sen+#words)計算得到的。
以第1句話為例:ppl=10^-(-1.44716)/(1+4)=1.94729。
ppl1為困惑度,它是由公式 10^-logprob/#words計算得到的。
以第1句話為例:ppl1=10^-(-1.44716)/4=2.30033。