
用好Lua+Unity,讓效能飛起來—LuaJIT效能坑詳解
導語:大家都知道LuaJIT比原生Lua快,快在JIT這三個字上。但實際情況是,LuaJIT的行為十分複雜。尤其JIT並不是一個簡單的把程式碼翻譯成機器碼的機制,背後有很多會影響效能的因素存在,下面筆者將帶大家一一說明。
這是侑虎科技第231篇原創文章,感謝作者招文勇供稿,歡迎轉發分享,未經作者授權請勿轉載。當然,如果您有任何獨到的見解或者發現也歡迎聯絡我們,一起探討。(QQ群:465082844)
一、LuaJIT分為JIT模式和Interpreter模式,首先要弄清楚你使用的模式
同樣的程式碼,在PC下可能以不足1ms的速度完成,而到了iOS卻需要幾十ms,是因為PC的CPU更好?是,但要知道頂級iOS裝置的CPU單核效能已經是PC級,幾十甚至百倍的差距顯然不在這裡。
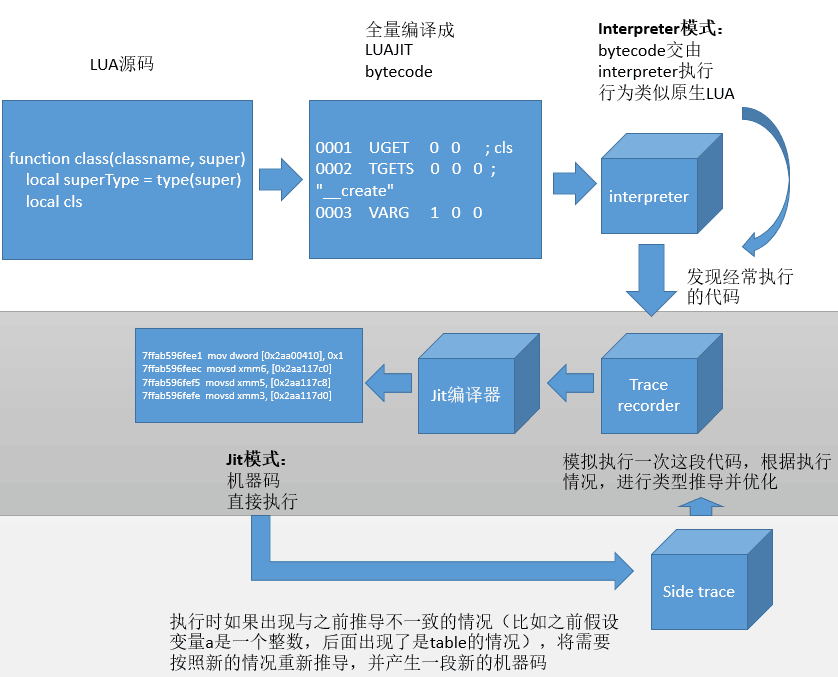
這裡要了解LuaJIT的兩種執行模式:JIT、Interpreter
JIT模式:這是LuaJIT高效所在,簡單地說就是直接將程式碼編譯成機器碼級別執行,效率大大提升(事實上這個機制沒有說的那麼簡單,下面會提到)。然而不幸的是這個模式在iOS下是無法開啟的,因為iOS為了安全,從系統設計上禁止了使用者程序自行申請有執行許可權的記憶體空間,因此你沒有辦法在執行時編譯出一段程式碼到記憶體然後執行,所以JIT模式在iOS以及其他有許可權管制的平臺(例如PS4,XBox)都不能使用。
Interpreter模式:那麼沒有JIT的時候怎麼辦呢?還有一個Interpreter模式。事實上這個模式跟原生Lua的原理是一樣的,就是並不直接編譯成機器碼,而是編譯成中間態的位元組碼(bytecode),然後每執行下一條位元組碼指令,都相當於switch到一個對應的function中執行,相比之下當然比JIT慢。但好處是這個模式不需要執行時生成可執行機器碼(位元組碼是不需要申請可執行記憶體空間的),所以任何平臺任何時候都能用,跟原生Lua一樣。這個模式可以執行在任何LuaJIT已經支援的平臺,而且你可以手動關閉JIT,強制執行在Interpreter模式下。
我們經常說的將Lua編譯成bytecode可以防止破解,這個bytecode是Interpreter模式的bytecode,並不是JIT編譯出的機器碼(事實上還有一個在bytecode向機器碼轉換過程中的中間碼SSA IR,有興趣可以看LuaJIT官方WIKI),比較坑的是可供32位版本和64位版本執行的bytecode還不一樣,這樣才有了著名的2.0.x版本在iOS加密不能的坑。
二、JIT模式一定更快?不一定!
iOS不能用JIT,那麼安卓下應該就可以飛起來用了吧?用指令碼語言獲得飛一般的效能,讓我大紅米也能對槓iPhone!然而,並不是安卓不能開啟JIT,而是JIT的行為極其複雜,對平臺高度依賴,導致它在以arm為主的安卓平臺下,未必能發揮出在PC上的威力,要知道LuaJIT最初只是考慮PC平臺的。
首先我們要知道,JIT到底怎麼運作的。LuaJIT使用了一個很特殊的機制(也是其大坑),叫做trace compiler的方式,來將程式碼進行JIT編譯的。什麼意思呢?它不是簡單的像C++編譯器那樣直接把整套程式碼翻譯成機器碼就完事了,因為這麼做有三個問題:
- 編譯時間長,這點比較好理解。
- 更關鍵的是,作為動態語言,難以優化。例如對於一個function foo(a),這個a到底是什麼型別,並不知道,對這個a的任何操作,都要檢查型別,然後根據型別做相應處理,哪怕就是一個簡單的a+b都必須這樣(a和b完全有可能是兩個表,實現的__add元方法),實際上跟Interpreter模式就沒什麼區別了,根本起不到高效執行的作用;
- 很多動態型別無法提前知道型別資訊,也就很難做連結(知道某個function的地址、知道某個成員變數的地址)。
那怎麼辦呢?這個解決方案可以另寫一篇文章了。這裡只是簡單說一下LuaJIT採用的trace compiler方案:首先所有的Lua都會被編譯成bytecode,在Interpreter模式下執行,當Interpreter發現某段程式碼經常被執行,比如for迴圈程式碼(是的,大部分效能瓶頸其實都跟迴圈有關),那麼LuaJIT會開啟一個記錄模式,記錄這段程式碼實際執行每一步的細節(比如裡頭的變數是什麼型別,猜測是數值還是table)。有了這些資訊,LuaJIT就可以做優化了:如果a+b發現就是兩個數字相加,那就可以優化成數值相加;如果a.xxx就是訪問a下面某個固定的欄位,那就可以優化成固定的記憶體訪問,不用再走表查詢。最後就可以將這段經常執行的程式碼JIT化。
這裡可以看到,第一,Interpreter模式是必須的,無論平臺是否允許JIT,都必須先使用Interpreter執行;第二,並非所有程式碼都會JIT執行,僅僅是部分程式碼會這樣,並且是執行過程中決定的。
三、要在安卓下發揮JIT的威力,必須要解決掉JIT模式下的坑:JIT失敗
那麼說了JIT怎麼運作的,看起來沒什麼問題呀,為何說不一定更快呢?這裡就有另一個大坑:LuaJIT無法保證所有程式碼都可以JIT化,並且這點只能在嘗試編譯的過程中才知道。
聽起來好像沒什麼概念。事實上,這種情況的出現,有時是毀滅性的,可以讓你的執行速度下降百倍。對,你沒看錯,是百倍,幾ms的程式碼突然飆到幾百ms。具體的感受,可以看看我們之前的技術推文《Unity專案常見Lua解決方案效能比較》中S3的測試資料,一個純Lua程式碼的用例(Vector3.Normalize沒有經過c#),卻出現了巨大的效能差異。而JIT失敗的原因非常多,而當你理解背後的原理後會知道,在安卓下JIT失敗的可能要比PC上高得多。
根據我們在安卓下的使用來看,最常見的有以下幾種,並且後面寫上了應對方案。
3.1 可供程式碼執行的記憶體空間被耗盡->要麼放棄JIT,要麼修改LuaJIT的程式碼
要JIT,就要編譯出機器碼,放到特定的記憶體空間。但是arm有一個限制,就是跳轉指令只能跳轉前後32MB的空間,這導致了一個巨大的問題:LuaJIT生成的程式碼要保證在一個連續的64MB空間內,如果這個空間被其他東西佔用了,LuaJIT就會分配不出用於jit的記憶體,而目前LuaJIT會瘋狂重複嘗試編譯,最後導致效能處於癱瘓的狀態。
雖然網上有一些不修改LuaJIT的方案,在Lua中呼叫LuaJIT的jit.opt的api嘗試將記憶體空間分配給LuaJIT,但根據我們的測試,在Unity上這樣做仍然無法保證所有機器上能夠不出問題,因為這些方案的原理要搶在這些記憶體空間被用於其他用途前全部先分配給LuaJIT,但是uLua可以執行的時候已經是程式初始化非常後期的階段,這個時候眾多的Unity初始化流程可能早已耗光了這塊記憶體空間。相反Cocos-2dx這個問題並不多見,因為LuaJIT執行早,有很大的機會提前搶佔記憶體空間。
無論從程式碼看還是根據我們的測試以及LuaJIT maillist的反饋來看,這個問題早在2.0.x就存在,更換2.1.0依然無法解決,我們建議,如果專案想要使用jit模式,需要在android工程的Activity入口中就載入LuaJIT,做好記憶體分配,然後將這個luasate傳遞給Unity使用。如果不願意趟這個麻煩,那可以根據專案實際測試的情況,考慮禁用jit模式(見文章第9點)。一般來說,Lua程式碼越少,遇到這個問題的可能性越低。
3.2 暫存器分配失敗->減少local變數、避免過深的呼叫層次
很不幸的一點是,arm中可用的暫存器比x86少。LuaJIT為了速度,會盡可能用暫存器儲存local變數,但是如果local變數太多,暫存器不夠用,目前JIT的做法是:放棄治療(有興趣可以看看原始碼中asm_head_side函式的註釋)。因此,我們能做的,只有按照官方優化指引說的,避免過多的local變數,或者通過do end來限制local變數的生命週期。
3.3 呼叫c函式的程式碼無法JIT->使用ffi,或者使用2.1.0beta2
這裡要提醒一點,呼叫c#,本質也是呼叫c,所以只要呼叫c#匯出,都是一樣的。而這些程式碼是無法JIT化的,但是LuaJIT有一個利器,叫ffi,使用了ffi匯出的c函式在呼叫的時候是可以JIT化的。
另外,2.1.0beta2開始正式引入了trace stitch,可以將呼叫c的lua程式碼獨立起來,將其他可以jit的程式碼jit掉,不過根據作者的說法,這個優化效果依然有限。
3.4 JIT遇到不支援的位元組碼->少用for in pairs,少用字串連線
有非常多bytecode或者內部庫呼叫是無法JIT化的,最典型就是for in pairs,以及字串連線符(2.1.0開始支援JIT)。
四、怎麼知道自己的程式碼有沒有JIT失敗?使用v.lua
完整的LuaJIT的exe版本都會帶一個JIT目錄,下面有大量LuaJIT的工具,其中有一個v.lua,這是LuaJIT Verbose Mode(另外還有一個很重要的叫p.lua,luajit profiler,後面會提到),可以追蹤LuaJIT執行過程中的一些細節,其中就可以幫你追蹤JIT失敗的情況。
local verbo = require("jit.v")
verbo.start()
當你看到以下錯誤的時候,說明你遇到了JIT失敗:
failed to allocate mcode memory,對應錯誤3.1
NYI: register coalescing too complex,對應錯誤3.2
NYI: C function,對應錯誤3.3(這個錯誤在2.1.0beta2中已經移除,因為有trace stitch)
NYI: bytecode,對應錯誤3.4
這在LuaJIT.exe下使用會很正常,但要在Unity下用上需要修改v.lua的程式碼,把所有out:write輸出導向到Debug.Log裡。
五、照著LuaJIT的偏好來寫Lua程式碼
最後,趟完LuaJIT本身的深坑,還有一些相對輕鬆的坑,也就是你如何在寫Lua的時候,根據LuaJIT的特性,按照其喜好的方式來寫,獲得更好的效能
這裡可以看我們的另一篇文章《LuaJIT官方效能優化指南和註解》,這裡比較詳細地說明如何寫出適合LuaJIT的Lua程式碼。
六、如果可以,用傳統的local function而非class的方式來寫程式碼
由於cocos2dx時代的推廣,目前主流的Lua面向物件實現(例如Cocos-2dx以及uLua的simpleframework整合的)都依賴metatable來呼叫成員函式,深入讀過LuaJIT後就會知道,在Interpreter模式下,查詢metatable會產生多一次表查詢,而且self:Func()這種寫法的效能也遠不如先cache再呼叫的寫法:local f = Class.Func; f(self),因為local cache可以省去表查詢的流程,根據我們的測試,Interpreter模式下,結合local cache和移除metatable流程,可以有2~3倍的效能差。
而LuaJIT官方也建議儘可能只調用local function,省去全域性查詢的時間。比較典型的就是Vector3的主流Lua實現都是基於metatable做的,雖然程式碼更優雅,更接近面向物件的風格(va:Add(vb)對比Vector3.Add(va, vb))但是效能會差一些。當然,這點可以根據專案的實際情況來定,不必強求,畢竟要在程式碼可讀性和效能間權衡。我們建議在高頻使用的物件中(例如Vector3)使用function風格的寫法,而主要的程式碼可以繼續保持class風格的寫法。
七、不要過度使用C#回撥Lua,這非常慢
目前LuaJIT官方文件(ffi的文件)中建議優先進行Lua呼叫c,而儘可能避免c回撥Lua。當然常用的UI回撥因為頻次不高所以一般可以放心使用,但是如果是每幀觸發的邏輯,那麼直接在Lua中完成,比反覆從Lua->C->Lua的呼叫要更快。這裡有一篇blog分析,可以參考:http://www.cppblog.com/tdzl2003/archive/2013/02/24/198045.html
八、藉助ffi,進一步提升LuaJIT與C/C#互動的效能
ffi是LuaJIT獨有的一個神器,用於進行高效的LuaJIT與C互動。其原理是向LuaJIT提供C程式碼的原型宣告,這樣LuaJIT就可以直接生成機器碼級別的優化程式碼來與C互動,不再需要傳統的Lua API來做互動。
我們進行過簡單的測試,利用ffi的互動效率可以有數倍甚至10倍級別的提升(當然具體要視乎引數列表而定),真可謂飛翔的速度。而藉助ffi也是可以提高LuaJIT與C#互動的效能。原理是利用ffi呼叫自己定義的C函式,再從C函式呼叫C#,從而優化掉LuaJIT到c這一層的效能消耗,而主要留下C到C#的互動消耗。在上一篇中我們提到的300ms優化到200ms,就是利用這個技巧達到的。
必須要注意的是,ffi只有在JIT開啟下才能發揮其效能,如果是在iOS下,ffi反而會拖慢效能。所以使用的時候必須要做好快關。
首先,我們在c中定義一個方法,用於將C#的函式註冊到c中,以便在c中可以直接呼叫C#的函式,這樣只要LuaJIT可以ffi呼叫c,也就自然可以呼叫C#的函數了
void gse_ffi_register_csharp(int id, void* func)
{
s_reg_funcs[id] = func;
}
這裡,id是一個你自由分配給C#函式的id,lua通過這個id來決定呼叫哪個函式。
然後在C#中將C#函式註冊到c中
[DllImport(LUADLL, CallingConvention = CallingConvention.Cdecl, ExactSpelling = true)]
public static extern void gse_ffi_register_csharp(int funcid, IntPtr func);
public static void gse_ffi_register_v_i1f3(int funcid, f_v_i1f3 func)
{
gse_ffi_register_csharp(funcid, Marshal.GetFunctionPointerForDelegate(func));
}
gse_ffi_register_v_i1f3(1, GObjSetPositionAddTerrainHeight);//將GObjSetPositionAddTerrainHeight註冊為id1的函式
然後Lua中使用的時候,這麼呼叫
local ffi = require("ffi")
ffi.cdef[[
int gse_ffi_i_f3(int funcid, float f1, float f2, float f3);
]]
local funcid = 1
ffi.C.gse_ffi_i_f3(funcid, objID, posx, posy, posz)
就可以從Lua中利用ffi呼叫C#的函數了
可以類似ToLua,將這個註冊流程的程式碼自動生成。
九、既然LuaJIT坑那麼多那麼複雜,為什麼不用原生Lua?
無法否認,LuaJIT的JIT模式非常難以駕馭,尤其是其在移動平臺上的效能表現不穩定導致在大型工程中很難保證其效能可靠。那是不是乾脆轉用原生Lua呢?
我們的建議是,繼續使用LuaJIT,但是對於一般的團隊而言,使用Interpreter模式。
目前根據我們的測試情況來看,LuaJIT的Interpreter模式誇平臺穩定性足夠,效能行為也基本接近原生Lua(不會像JIT模式有各種trace compiler帶來的坑),但是效能依然比原生Lua有絕對優勢(平均可以快3~8倍,雖然不及JIT模式極限幾十倍的提升),所以在遊戲這種效能敏感的場合下面,我們依然推薦使用LuaJIT,至少使用Interpreter模式。這樣專案既可以享受一個相對ok的語言效能,同時又不需要過度投入精力進行Lua語言的優化。
此外,LuaJIT原生提供的profiler也非常有用,更復雜的位元組碼也更有利於反破解。如果團隊有能力解決好LuaJIT的編譯以及程式碼修改維護,LuaJIT還是非常值得推薦的。
不過,LuaJIT目前的更新頻率確實在減緩,最新的LuaJIT2.1.0 beta2已經有一年沒有新的beta更新(但這個版本目前看也足夠穩定),在標準上也基本停留在Lua5.1上,沒有5.3裡int64/utf8的原生支援,此外由於LuaJIT的平臺相關性極強,一旦希望支援的平臺存在相容性問題的話,很可能需要自行解決甚至只能轉用原生Lua。所以開發團隊需要自己權衡。但從我們的實踐情況來看,LuaJIT使用5.1的標準再整合一些外部的int64/utf解決方法就能很好地適應跨平臺、國際化的需求,並沒有實質的障礙,同時繼續享受這個版本的效能優勢。
我們的專案,在戰鬥時同屏規模可達100+角色,在這樣的情況下Interpreter的效能依然有相當的壓力。所以團隊如果決定使用Lua開發,仍然要注意Lua和C #程式碼的合理分配,高頻率的程式碼儘量由C#完成,Lua負責組裝這些功能模組以及編寫經常需要熱更的程式碼。
最後,怎麼開啟Interpreter模式?非常簡單,最你執行第一行Lua前面加上。
if jit then
jit.off();jit.flush()
end
文末,再次感謝招文勇的分享,如果您有任何獨到的見解或者發現也歡迎聯絡我們,一起探討。(QQ群:465082844)。
也歡迎大家來積極參與U Sparkle開發者計劃,簡稱"US",代表你和我,代表UWA和開發者在一起!