
PASCAL VOC資料集分析(檢測部分)
阿新 • • 發佈:2019-02-12
Pascal VOC 資料集介紹
介紹Pascal VOC資料集:
- Challenge and tasks, 只介紹Detection與Segmentation相關內容。
- 資料格式 Dataset
- 衡量方式 Evaluation
- voc2007, voc2012
Challenge and tasks
給定自然圖片, 從中識別出特定物體。
待識別的物體有20類:
- person
- bird, cat, cow, dog, horse, sheep
- aeroplane, bicycle, boat, bus, car, motorbike, train
- bottle, chair, dining table, potted plant, sofa, tv/monitor
有以下幾個task:
* Classification(略過)
* Detection: 將圖片中所有的目標用bounding box(bbox)框出來
* Segmentation: 將圖片中所有的目標分割出來
* Person Layout(略過)
接下來本文只介紹Detection與Segmentation相關的內容。
Dataset
- 所有的標註圖片都有Detection需要的label, 但只有部分資料有Segmentation Label。
- VOC2007中包含9963張標註過的圖片, 由train/val/test三部分組成, 共標註出24,640個物體。
- VOC2007的test資料label已經公佈, 之後的沒有公佈(只有圖片,沒有label)。
- 不同年份的VOC資料集之間存在交集,後面年份的VOC資料集是在之前的資料集基礎之上新增資料得到的。
- 對於檢測任務,VOC2012的trainval/test包含08-11年的所有對應圖片。 trainval有11540張圖片共27450個物體。
- 對於分割任務, VOC2012的trainval包含07-11年的所有對應圖片, test只包含08-11。trainval有 2913張圖片共6929個物體。
Detection Ground Truth and Evaluation
Ground truth
<annotation>
<folder>VOC2007</folder>
<filename Evaluation
提交的結果儲存在一個檔案中, 每行的格式為:
<image identifier> <confidence> <left> <top> <right> <bottom>例如:
comp3_det_test_car.txt:
000004 0.702732 89 112 516 466
000006 0.870849 373 168 488 229
000006 0.852346 407 157 500 213
000006 0.914587 2 161 55 221
000008 0.532489 175 184 232 201- confidence會被用於計算mean average precision(mAP). 簡要流程如下, 詳細可參考https://sanchom.wordpress.com/tag/average-precision/
- 根據confidence對結果排序,計算top-1, 2, …N對應的precision和recall
- 將recall劃分為n個區間
t in [t1, ..., tn] - 找出滿足
recall>=t的最大presicision - 最後得到n個最大precision, 求它們的平均值
aps = []
for t in np.arange(0., 1.1, 0.1):#將recall分為多個區間
# 在所有 recall > t對應的precision中找出最大值
mask = tf.greater_equal(recall, t)
v = tf.reduce_max(tf.boolean_mask(precision, mask))
aps.append(v / 11.)
# 得到其平均值
ap = tf.add_n(aps)
return ap- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
如果,recall-precision曲線是單調下降的,這樣得到的結果其實就近似的等於recall-precision的面積。
程式碼給出的是voc07的計算方式, voc2010在recall區間區分上有變化: 假如有M個正樣例,則將recall劃分為[1/M, 1/(M - 1), 1/(M - 2), ... 1]。其餘步驟不變。
預測的bbx的判別:
- 如輸出的bbox與一個ground truth bbox的 IOU大於0.5, 且類別相同,則為True Positive, 否則為False Positive
- 對於一個ground truth bbox, 只會有一個 true positive, 其餘都為false positive.
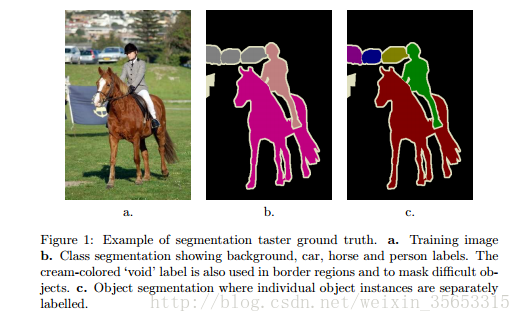
Segmentation
Ground Truth
分割的label由兩部分組成: 對畫素點進行分類
* class segmentation: 標註出每一個畫素的類別(語義分割)
* object segmentation: 標註出每一個畫素屬於哪一個物體(例項分割)
Evaluation
每類的precision和總體precision.
轉載自:http://blog.csdn.net/weixin_35653315/article/details/71028523
北理工車輛檢測資料集:
http://iitlab.bit.edu.cn/mcislab/vehicledb/