
《SQL進階教程》讀書小記
阿新 • • 發佈:2019-02-12
CASE表示式的兩種寫法:
①簡單CASE表示式:
CASE sex
WHEN '1' THEN '男'
WHEN '2' THEN '女'
ELSE '其他' END②搜尋CASE表示式:
CASE
WHEN sex = '1' THEN '男'
WHEN sex = '2' THEN '女'
ELSE '其他' END- CASE語句不寫ELSE子句時,執行結果是NULL。
- CASE將已有編號方式轉換為新的方式並統計:
SELECT (CASE語句),SUM(需要統計的列)
FROM 表
GROUP 比如:
SELECT CASE pref_name
WHEN '德島' THEN '四國'
WHEN '香川' THEN '四國'
WHEN '愛媛' THEN '四國'
WHEN '高知' THEN '四國'
WHEN '福岡' THEN '九州'
WHEN '佐賀' THEN '九州'
WHEN '長崎' THEN '九州'
ELSE '其他'
END AS district, SUM(population)
FROM PopTb1
GROUP -
-
新手用WHERE子句進行條件分支,高手用SELECT子句進行條件分支。
- CASE和CHECK搭配使用,使用蘊含式:P→Q。即:如果P為真,Q一定要為真;P不為真,無所謂。
- UPDATE使用CASE:
UPDATE products
SET prod_price = CASE
WHEN prod_price < 4 THEN prod_price + 0.51
WHEN prod_price > 11 THEN prod_price - 0.99
ELSE prod_price
END- CASE語句還能判斷表示式:
SELECT course_name
, CASE
WHEN course_id IN (
SELECT course_id
FROM opencourses
WHERE month = 200706
) THEN 'O'
ELSE 'X'
END AS '6月'
, CASE
WHEN course_id IN (
SELECT course_id
FROM opencourses
WHERE month = 200707
) THEN 'O'
ELSE 'X'
END AS '7月'
, CASE
WHEN course_id IN (
SELECT course_id
FROM opencourses
WHERE month = 200708
) THEN 'O'
ELSE 'X'
END AS '8月'
FROM coursemaster;SELECT course_name
, CASE
WHEN EXISTS (
SELECT course_id
FROM opencourses OC
WHERE month = 200706
AND OC.course_id= CM.course_id
) THEN 'O'
ELSE 'X'
END AS '6月'
, CASE
WHEN EXISTS (
SELECT course_id
FROM opencourses OC
WHERE month = 200707
AND OC.course_id= CM.course_id
) THEN 'O'
ELSE 'X'
END AS '7月'
, CASE
WHEN EXISTS (
SELECT course_id
FROM opencourses OC
WHERE month = 200708
AND OC.course_id= CM.course_id
) THEN 'O'
ELSE 'X'
END AS '8月'
FROM coursemaster CM- 在CASE中使用聚合函式:
1.獲取只加入了一個社團的學生的社團ID。
2.獲取加入了多個社團的學生的主社團ID。

SELECT std_id
, CASE
WHEN COUNT(club_id) = 1 THEN club_id
ELSE MAX(CASE
WHEN main_club_flg = 'Y' THEN club_id
ELSE NULL
END)
END AS main_club
FROM studentclub
GROUP BY std_id-
-
新手用HAVING子句進行條件分支,高手用SELECT子句進行條件分支。
CASE語句可以寫在SELECT子句、GROUP BY子句、WHERE子句、ORDER BY子句中。
SQL -> 面向集合語言
在SQL中,只要被賦予了不同的名稱,即便是相同的表也應該當作不同的表(集合)來對待。集合是SQL唯一能處理的資料結構。
在需要獲取列的組合時,經常需要用到“非等值自連線”。
獲取product表的名字的組合,組合不是排列,組合{1,2}和{2,1}是同一個元素,而排列有順序。
SELECT p1.name AS name1, p2.name AS name2
FROM products p1, products p2
WHERE p1.name > p2.name;- 對NULL使用比較謂詞後得到的結果總是unknow,比如1 = NULL、2 > NULL 、NULL = NULL。
真值優先順序:
AND的情況:false > unknow > true
OR的情況:true > unknow > falseSQL的查詢結果裡只有判斷結果為true的行,false和unknow的行不會出現在結果裡。
- 在SQL中,排中律並不成立,因為有NULL值,比如
年齡=20 OR 年齡 <> 20現實生活中是成立的,但在資料庫中,年齡可能是NULL,這樣就是unknow OR unknow,結果還是unknow,所以排中律在資料庫中並不成立。 - CASE子句判斷條件中如果有NULL,不要使用
CASE 列 WHEN NULL...這個永遠是unknow,它等於:
CASE WHEN 列 = NULL...應該使用:
CASE WHEN 列 IS NULL...的格式。
- 切記:NULL不是值。
- unknow AND 條件 => 結果不會為true
- unknow OR 條件 => 結果不會為false
- IN和EXISTS可以互相替換使用,NOT IN和NOT EXISTS不可以互相替換。IN相當於多個OR,只要有一個true就為true;NOT IN相當於多個NOT AND(NOT IN(x or y or z)= NOT x AND NOT y AND NOT z),只要x,y,z出現一個NULL就永遠不為true。EXISTS和NOT EXISTS子句只會返回true或false,不會返回unknow。
- 在以前的SQL標準中,HAVING子句必須和GROUP BY子句一起使用;但是按照現在的SQL標準來說,HAVING自己是可以單獨使用的,不過這種情況下,就不能再SELECT子句中引用原來的列了,要麼使用常量,要麼使用聚合函式。單獨使用HAVING子句的情況可以看成是對空欄位進行了GROUP BY,此時整張表會被聚合為一行。
- COUNT(*)可以用於NULL,COUNT(列名)要先排除NULL的行再進行統計。
- SQL通過不斷生成子集來求得目標集合。
- MYSQL不支援FULL JOIN。可以將left join的結果和right join的結果union起來的方式來實現full join。
使用sql進行集合運算
①交集
內連線
SELECT * FROM table_a
INNER JOIN table_b ON table_a.id = table_b.id;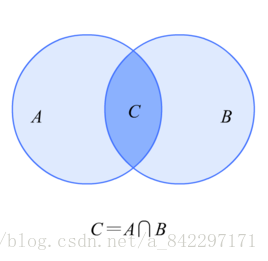
②並集
全外連線
SELECT * FROM table_a
FULL OUTER JOIN table_b ON table_a.id = table_b.id;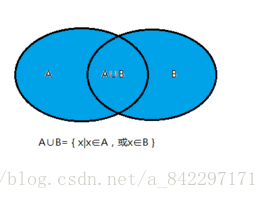
有的DBMS不支援全外連線,比如MYSQL,可以使用union all來實現全外連線:
SELECT * FROM table_a
INNER JOIN table_b ON table_a.id = table_b.id
UNION ALL
SELECT * FROM table_a
LEFT OUTER JOIN table_b ON table_a.id = table_b.id
WHERE table_b.id IS NULL
UNION ALL
SELECT * FROM table_a
RIGHT OUTER JOIN table_b ON table_a.id = table_b.id
WHERE table_a.id IS NULL③差集
左外連線、右外連線
SELECT * FROM table_a
RIGHT OUTER JOIN table_b ON table_a.id = table_b.id
WHERE table_a.id IS NULL;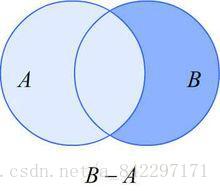
④異或集
全外連線-內連線
SELECT * FROM table_a
FULL OUTER JOIN table_b ON table_a.id = table_b.id
where table_a.id IS NULL OR table_b.id IS NULL;
- SIGN(x)函式:如果x > 0,返回1;如果x = 0,返回0;如果x < 0,返回-1。
- 時間重疊函式overlaps,mysql還不支援,oracle支援。
- 加上可選項ALL之後,就不會發生排序,所以效能會有所提升。比如UNIOIN ALL,如果不關心資料是否重複,或者確定不會有重複的資料,可以加上ALL。
- 如果兩個集合是相同的,則它們的並集也是相同的。即:
A UNIOIN B = A = B。而且是冪等性的,即S UNION S UNION S UNION S...UNION S = S,這裡的集合指的是沒有重複行的集合,也是數學裡的集合,所以主鍵是多麼重要。 - 支撐SQL和關係資料庫的基礎理論主要有兩個:一個是數學領域的集合論,另一個是作為現代邏輯學標準體系的謂詞邏輯。
- 例如“=、<、>”等比較謂詞,以及BETWEEN、LIKE、IN、IS等都屬於謂詞。實際上,謂詞是一種特殊的函式,返回值是真值。謂詞邏輯提供謂詞是為了判斷命題(可以理解成陳述句)的真假。平時使用的WHERE子句,其實也可以看成是由多個謂詞組合而成的新謂詞,只有能讓WHERE子句的返回值為真的命題,才能從表中查詢到。
- EXISTS的引數是資料的集合,所以是二階謂詞;其他謂詞比如=、>的引數都是一行資料,所以使一階謂詞。
- EXISTS和NOT EXISTS實際上是把表中的資料一行行用引數的集合來校驗。
- 在SQL中遇到需要全稱量化的問題時,一般的思路都是把“所有行都滿足條件P”轉換成它的雙重否定——不存在不滿足條件P的行。
四種進行差集運算的方法:
①EXCEPT
②不支援EXCEPT的資料庫也能使用,而且易於理解的方法:NOT IN
③NOT IN的相似方法:NOT EXISTS
④麻煩的方法:外連線,比如 A left join B where A.x = B.x,差集就是右邊為NULL的列。
效能最好的是NOT EXISTS。某個集合中,如果元素最大值和最小值相等,那麼這個集合中肯定只有一種值。
- 在數學中,通過GROUP BY生成的子集有一個對應的名字,叫作劃分。
- 資料庫中,0/0為NULL。
- 如果通過CASE表示式生成特徵函式,那麼無論多麼複雜的條件都可以描述。
- 使用多個欄位查詢集合中的重複元素時,不應該對各個欄位分別進行條件匹配,而應該將他們“整個地作為一個欄位”進行條件匹配。
- 引數是子查詢時,使用EXISTS代替IN。一方面子查詢可以走索引(如果列上有索引),另一方面只要查詢到一行滿足條件就會終止查詢。使用IN的時候,資料庫首先會進行子查詢,然後將結果儲存在一張臨時的工作表中(腦內聯檢視),然後掃描整個檢視。使用EXISTS,資料庫不會生成臨時的工作表。
- 引數是子查詢時,使用連線代替IN。
- 避免排序。
- 像UNION、INTERSECT、EXCEPT這類的運算子,資料庫內部都會進行排序,加上ALL可以避免排序(不在乎有重複資料的時候)。
- DISTINCT也會進行排序。可以使用EXISTS代替DISTINCT,因為EXISTS有遇到符合的就停止查詢的特性。
- 使用極值函式(比如MAX和MIN),如果引數欄位上建有索引,則只需要掃描索引,不需要掃描整張表。
- 能寫在WHERE字句裡的條件不要寫在HAVING字句裡。
- HAVING子句是針對聚合後生成的檢視進行篩選的。
- 通過指定帶索引的列作為GROUP BY和ORDER BY的列,可以實現高速查詢。
- 把運算的表示式放在查詢條件的右側,就能用到索引了。
- 使用索引時,條件表示式的左側應該是原始欄位。
- 使用聯合索引時,指定條件的順序很重要。
- 使用LIKE謂詞進行後方一致或中間一致的匹配。
- 預設的型別轉換不僅會增加額外的效能開銷,還會導致索引不可用。
- 不管是減少排序還是使用索引,抑或是避免中間表的使用,都是為了減少對硬碟的訪問。
- 如果沒有為索引和約束顯式地指定名稱,DBMS就會自動為之分配隨機的名稱。
- SQL中各部分的執行順序是:FROM -> WHERE -> GROUP BY -> HAVING -> SELECT(-> ORDER BY)。
