
銀行貸款預測分析(Loan Prediction)
貸款資料的預測分析,通過使用python來分析申請人哪些條件對貸款有影響,並預測哪些客戶更容易獲得銀行貸款。
提出問題:哪些客戶更容易獲得銀行貸款?
匯入資料
import numpy as np
import pandas as pd
from matplotlib import pyplot as plt
import seaborn as sns
%matplotlib inline
# 匯入資料
full_data = pd.read_csv('loan_train.csv')
full_data.shape
(614, 13)
資料有614行,13列。
檢視前五行資料
full_data. | Loan_ID | Gender | Married | Dependents | Education | Self_Employed | ApplicantIncome | CoapplicantIncome | LoanAmount | Loan_Amount_Term | Credit_History | Property_Area | Loan_Status | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | LP001002 | Male | No | 0 | Graduate | No | 5849 | 0.0 | NaN | 360.0 | 1.0 | Urban | Y |
| 1 | LP001003 | Male | Yes | 1 | Graduate | No | 4583 | 1508.0 | 128.0 | 360.0 | 1.0 | Rural | N |
| 2 | LP001005 | Male | Yes | 0 | Graduate | Yes | 3000 | 0.0 | 66.0 | 360.0 | 1.0 | Urban | Y |
| 3 | LP001006 | Male | Yes | 0 | Not Graduate | No | 2583 | 2358.0 | 120.0 | 360.0 | 1.0 | Urban | Y |
| 4 | LP001008 | Male | No | 0 | Graduate | No | 6000 | 0.0 | 141.0 | 360.0 | 1.0 | Urban | Y |
一、理解資料
Loan_ID 貸款人ID
Gender 性別 (Male, female)
ApplicantIncome 申請人收入
Coapplicant Income 申請收入
Credit_History 信用記錄
Dependents 親屬人數
Education 教育程度
LoanAmount 貸款額度
Loan_Amount_Term 貸款時間長
Loan_Status 貸款狀態 (Y, N)
Married 婚姻狀況(NO,Yes)
Property_Area 所在區域包括:城市地區、半城區和農村地區
Self_Employed 職業狀況:自僱還是非自僱
檢視描述統計資料
full_data.describe()
| ApplicantIncome | CoapplicantIncome | LoanAmount | Loan_Amount_Term | Credit_History | |
|---|---|---|---|---|---|
| count | 614.000000 | 614.000000 | 592.000000 | 600.00000 | 564.000000 |
| mean | 5403.459283 | 1621.245798 | 146.412162 | 342.00000 | 0.842199 |
| std | 6109.041673 | 2926.248369 | 85.587325 | 65.12041 | 0.364878 |
| min | 150.000000 | 0.000000 | 9.000000 | 12.00000 | 0.000000 |
| 25% | 2877.500000 | 0.000000 | 100.000000 | 360.00000 | 1.000000 |
| 50% | 3812.500000 | 1188.500000 | 128.000000 | 360.00000 | 1.000000 |
| 75% | 5795.000000 | 2297.250000 | 168.000000 | 360.00000 | 1.000000 |
| max | 81000.000000 | 41667.000000 | 700.000000 | 480.00000 | 1.000000 |
檢視資料集
full_data.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 614 entries, 0 to 613
Data columns (total 13 columns):
Loan_ID 614 non-null object
Gender 601 non-null object
Married 611 non-null object
Dependents 599 non-null object
Education 614 non-null object
Self_Employed 582 non-null object
ApplicantIncome 614 non-null int64
CoapplicantIncome 614 non-null float64
LoanAmount 592 non-null float64
Loan_Amount_Term 600 non-null float64
Credit_History 564 non-null float64
Property_Area 614 non-null object
Loan_Status 614 non-null object
dtypes: float64(4), int64(1), object(8)
memory usage: 62.4+ KB
看到資料有缺失值,需要後面進一步處理
二、從單變數進行分析
1. 分析目標變數Loan_Status貸款狀態
#目標變數統計
full_data['Loan_Status'].value_counts()
Y 422
N 192
Name: Loan_Status, dtype: int64
#統計百分比
full_data['Loan_Status'].value_counts(normalize=True)
Y 0.687296
N 0.312704
Name: Loan_Status, dtype: float64
sns.countplot(x='Loan_Status', data=full_data, palette = 'Set1')

614個人中有422人(約69%)獲得貸款批准
2.Gender 性別特徵
full_data['Gender'].value_counts(normalize=True)
Male 0.813644
Female 0.186356
Name: Gender, dtype: float64
sns.countplot(x='Gender', data=full_data, palette = 'Set1')
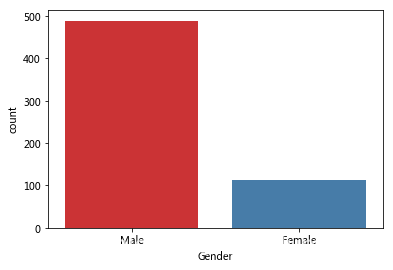
資料集中80%的申請人是男性。
3.Married婚姻特徵
full_data['Married'].value_counts(normalize=True).plot.bar(title= 'Married')
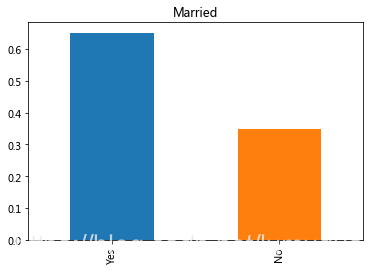
有65%的申請貸款的人是已經結婚。
4.Dependent親屬特徵
Dependents=full_data['Dependents'].value_counts(normalize=True)
Dependents
0 0.575960
1 0.170284
2 0.168614
3+ 0.085142
Name: Dependents, dtype: float64
Dependents.plot.bar(title= 'Dependents')

貸款客戶主要集中在沒有親屬關係中,佔到57%.
5.是否自僱人士
Self_Employed=full_data['Self_Employed'].value_counts(normalize=True)
print(Self_Employed)
No 0.859107
Yes 0.140893
Name: Self_Employed, dtype: float64
Self_Employed.plot.bar(title= 'Self_Employed')

大約有13%的申請人是自僱人士。
6.Loan_Amount_Term貸款時間
full_data['Loan_Amount_Term'].value_counts().plot.bar(title= 'Loan_Amount_Term')

貸款時間主要集中在360天
7.Credit_History 信用記錄變數
Credit_History=full_data['Credit_History'].value_counts(normalize=True)
print(Credit_History)
1.0 0.842199
0.0 0.157801
Name: Credit_History, dtype: float64
Credit_History.plot.bar(title= 'Credit_History')

大約85%的申請人已償還債務了。
8.Education 教育程度
Education=full_data['Education'].value_counts(normalize=True)
print(Education)
Graduate 0.781759
Not Graduate 0.218241
Name: Education, dtype: float64
Education.plot.bar(title= 'Education')

貸款的客戶中有接近80%的客戶主要是受教育的畢業生
三、雙變數分析各個特徵與目標變數(Loan_Status)的關係
1.性別與貸款關係
Gender=pd.crosstab(full_data['Gender'],full_data['Loan_Status'])
Gender.plot(kind="bar", stacked=True, figsize=(5,5))

男性更容易申請通過貸款
2.結婚與貸款關係
Married=pd.crosstab(full_data['Married'],full_data['Loan_Status'])
Married.plot(kind="bar", stacked=True, figsize=(5,5))

已經結婚的客戶申請貸款通過的最高
3.親屬人數與貸款關係
Dependents=pd.crosstab(full_data['Dependents'],full_data['Loan_Status'])
Dependents.plot(kind="bar", stacked=True, figsize=(5,5))

沒有親屬關係的客戶也容易獲得申請通過貸款
4.教育與貸款關係
Education=pd.crosstab(full_data['Education'],full_data['Loan_Status'])
Education.plot(kind="bar", stacked=True, figsize=(5,5))

已經受教育畢業的客戶獲得貸款更容易
5.職業與貸款關係
Self_Employed=pd.crosstab(full_data['Self_Employed'],full_data['Loan_Status'])
Self_Employed.plot(kind="bar", stacked=True, figsize=(5,5))

不是自僱客戶申請通過的最高
6.信用記錄與貸款之間的關係
Credit_History=pd.crosstab(full_data['Credit_History'],full_data['Loan_Status'])
Credit_History.plot(kind="bar", stacked=True, figsize=(5,5))

信用記錄為1的人更有可能獲得貸款批准,說明有信用的獲得貸款的機會大。
7.區域與貸款關係
Property_Area=pd.crosstab(full_data['Property_Area'],full_data['Loan_Status'])
Property_Area.plot(kind="bar", stacked=True, figsize=(5,5))

在半城市區獲得批准的貸款要高於農村或城市地區
四、熱圖來視覺化相關性
用於檢視所有數值變數之間的相關性。
首先將類別特徵值轉為數值型,方便熱圖分析相關性
將dependents變數中的3+更改為3以使其成為數值變數。我們還將目標變數的類別轉換為0和1,以便我們可以找到它與數值變數的相關性。
full_data['Gender'].replace(('Female','Male'),(0,1),inplace=True)
full_data['Married'].replace(('NO','Yes'),(0,1),inplace=True)
full_data['Dependents'].replace(('0', '1', '2', '3+'),(0, 1, 2, 3),inplace=True)
full_data['Education'].replace(('Not Graduate', 'Graduate'),(0, 1),inplace=True)
full_data['Self_Employed'].replace(('No','Yes'),(0,1),inplace=True)
full_data['Property_Area'].replace(('Semiurban','Urban','Rural'),(0,1,2),inplace=True)
通過著色的變化來顯示資料。顏色較深的變數意味著它們的相關性更高。
matrix = full_data.corr()
f, ax = plt.subplots(figsize=(8, 8))
sns.heatmap(matrix,vmax=.8, square=True,cmap="BuPu",annot=True);

可以看到最相關的變數是(ApplicantIncome - LoanAmount)和(Credit_History - Loan_Status),這兩者相關性強。
LoanAmount也與CoapplicantIncome相關。說明申請人的收入和貸款金額、信用歷史記錄與貸款狀態有很強的關係
五、缺失值和異常值的處理
連續變數特徵分析是否有異常值
申請人收入資料分析
plt.figure()
plt.subplot(121)
sns.distplot(full_data['ApplicantIncome']);
plt.subplot(122)
full_data['ApplicantIncome'].plot.box(figsize=(16,5))
plt.show()

收入分配的大部分資料主要偏在左邊,沒有呈現正態分佈,箱線圖確認存在大量異常值,收入差距較大,需要進行處理
按教育分開繪製
full_data.boxplot(column='ApplicantIncome', by = 'Education')
plt.suptitle("")
Text(0.5,0.98,'')

可以看到受教育的人,有很多的高收入,出現異常值。
貸款額度分析
plt.figure(1)
plt.subplot(121)
df=full_data.dropna()
sns.distplot(df['LoanAmount']);
plt.subplot(122)
full_data['LoanAmount'].plot.box(figsize=(16,5))
plt.show()

貸款額度數呈現正態分佈,但是從箱線圖中看到出現很多的異常值,下面需要進行處理異常值。
處理缺失值
檢視有多少缺失值
full_data.isnull().sum()
Loan_ID 0
Gender 13
Married 3
Dependents 15
Education 0
Self_Employed 32
ApplicantIncome 0
CoapplicantIncome 0
LoanAmount 22
Loan_Amount_Term 14
Credit_History 50
Property_Area 0
Loan_Status 0
dtype: int64
Gender,Married,Dependents,Self_Employed,LoanAmount,Loan_Amount_Term和Credit_History功能中缺少值
填充缺失的值的方法:
對於數值變數:使用均值或中位數進行插補
對於分類變數:使用常見眾數進行插補,這裡主要使用眾數進行插補空值
full_data['Gender'].fillna(full_data['Gender'].value_counts().idxmax(), inplace=True)
full_data['Married'].fillna(full_data['Married'].value_counts().idxmax(), inplace=True)
full_data['Dependents'].fillna(full_data['Dependents'].value_counts().idxmax(), inplace=True)
full_data['Self_Employed'].fillna(full_data['Self_Employed'].value_counts().idxmax(), inplace=True)
full_data["LoanAmount"].fillna(full_data["LoanAmount"].mean(skipna=True), inplace=True)
full_data['Loan_Amount_Term'].fillna(full_data['Loan_Amount_Term'].value_counts().idxmax(), inplace=True)
full_data['Credit_History'].fillna(full_data['Credit_History'].value_counts().idxmax(), inplace=True)
檢視是否存在缺失值
full_data.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 614 entries, 0 to 613
Data columns (total 13 columns):
Loan_ID 614 non-null object
Gender 614 non-null float64
Married 614 non-null object
Dependents 614 non-null float64
Education 614 non-null int64
Self_Employed 614 non-null float64
ApplicantIncome 614 non-null int64
CoapplicantIncome 614 non-null float64
LoanAmount 614 non-null float64
Loan_Amount_Term 614 non-null float64
Credit_History 614 non-null float64
Property_Area 614 non-null int64
Loan_Status 614 non-null object
dtypes: float64(7), int64(3), object(3)
memory usage: 62.4+ KB
可以看到資料集中已填充所有缺失值,沒有缺失值存在。
異常值處理
對於異常值需要進行處理,這裡採用對數log轉化處理,消除異常值的影響,讓資料迴歸正態分佈
full_data['LoanAmount_log'] = np.log(full_data['LoanAmount'])
full_data['LoanAmount_log'].hist(bins=20)
<matplotlib.axes._subplots.AxesSubplot at 0x1f506860>

full_data['ApplicantIncomeLog'] = np.log(full_data['ApplicantIncome'])
full_data['ApplicantIncomeLog'].hist(bins=20)

異常值處理完成,接下來構建模型預測準確率
六、構建模型(邏輯迴歸模型)
Loan_ID變數對貸款狀態沒有影響,需要刪除更改。
full_data=full_data.drop('Loan_ID',axis=1)
刪除目標變數Loan_Status,並將它儲存在另一個數據集中
X = full_data.drop('Loan_Status',1)
y = full_data.Loan_Status
X=pd.get_dummies(X)
full_data=pd.get_dummies(full_data)
匯入匯入train_test_split
from sklearn.model_selection import train_test_split
#建立訓練集合測試集
x_train, x_cv, y_train, y_cv = train_test_split(X,y, test_size =0.3)
從sklearn匯入LogisticRegression和accuracy_score並擬合邏輯迴歸模型
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
建立模型邏輯迴歸和訓練模型
model = LogisticRegression()
model.fit(x_train, y_train)
LogisticRegression(C=1.0, class_weight=None, dual=False, fit_intercept=True,
intercept_scaling=1, max_iter=100, multi_class='ovr', n_jobs=1,
penalty='l2', random_state=None, solver='liblinear', tol=0.0001,
verbose=0, warm_start=False)
評估模型
pred_cv = model.predict(x_cv)
accuracy_score(y_cv,pred_cv)
0.8054054054054054
預測幾乎達到80%準確,說明正確識別80%的貸款狀態
總結
通過練習熟悉資料分析的基本過程,學習到缺失值填充和異常值的處理以及資料視覺化知識;在構建模型中有很多模型方法不瞭解,後期需要繼續學習python資料分析方法和模型構建等知識。
本次主要練習學習python,更多的資料分析方法需要進一步學習。