用Adaboost對自己的資料分類
想用Adaboost分類器對自己的資料分類 而網上一查 好多都是Adaboost+Harr人臉檢測啥啥啥的 所以只能自己寫了 參考http://blog.csdn.net/zhaocj/article/details/50536385的 用Adaboost演算法對自己的資料集分類。特徵和標籤都是csv檔案: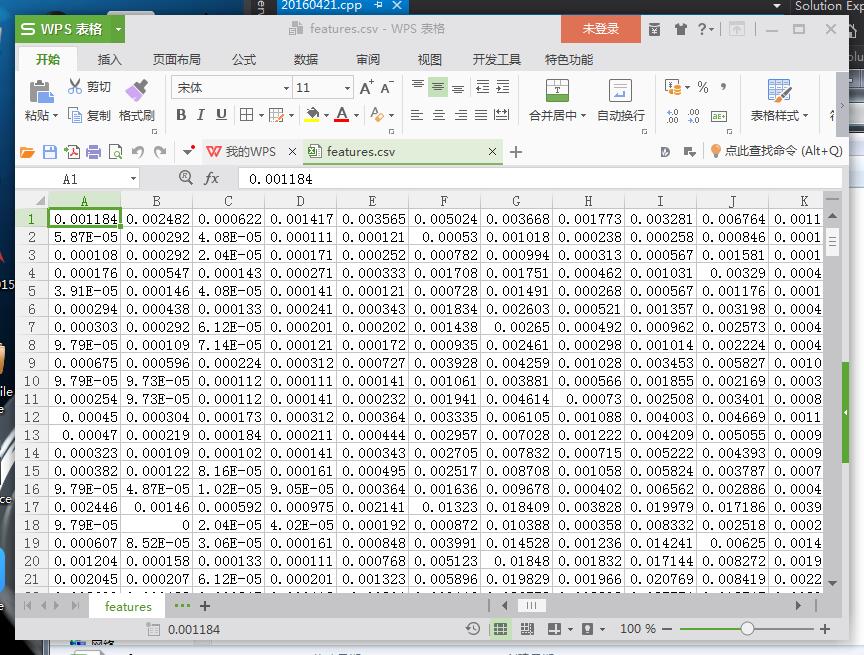
int main(int argc, char** argv)
{
//打亂順序結果在kuangvec[]和stonevec[]兩個數組裡 影象標號
const int uselesssample = 134, usefulsample = 90, allsample = 224,featurecol=1000;
//打亂順序 前90個為礦 後134個為廢石
int kuangvec[usefulsample], stonevec[uselesssample];
for (int i = 0; i < usefulsample; i++)
kuangvec[i] = i ;
for (int i = 0; i <uselesssample; i++)
stonevec[i] = usefulsample+i;
random_shuffle(kuangvec, kuangvec+usefulsample);
random_shuffle(stonevec, stonevec + uselesssample);
///////////////////////////////////////////////show fixed ranks
//for (int i = 0; i < usefulsample; i++)
//cout << kuangvec[i] << endl;
//cout << endl;
//for (int i = 0; i < uselesssample; i++)
//cout << stonevec[i] << endl;
/////////////////////////////////////////////////////////////////////read features
CvMLData cvmlprimer;
cvmlprimer.read_csv("features.csv");
cv::Mat cvml = cv::Mat(cvmlprimer.get_values(),true);
CvMLData resprimer;
resprimer.read_csv("labels.csv");
cv::Mat res = cv::Mat(resprimer.get_values(), true);
/////////////////////////////////////////////////////////////////////saperate into trainset
const float rate =0.6;
int trainnum=int(usefulsample*rate)+int(uselesssample*rate), testnum=allsample-trainnum;
Mat traindata=Mat::zeros(trainnum, featurecol, cvml.type()), testdata=Mat::zeros(testnum, featurecol, cvml.type()), trainlabel=Mat::zeros(trainnum, 1, res.type()), testlabel=Mat::zeros(testnum,1, res.type());
for (int i = 0; i <int(usefulsample*rate); i++)
{
float* newrow = traindata.ptr<float>(i);
int currentrow = kuangvec[i];
float* primerow = cvml.ptr<float>(currentrow);
for (int j = 0; j < featurecol; j++)
newrow[j] = primerow[j];
float* newlabelrow = trainlabel.ptr<float>(i);
float* primerlabelrow = res.ptr<float>(currentrow);
newlabelrow[0] = primerlabelrow[0];
}
for (int i = int(usefulsample*rate); i <trainnum; i++)
{
float* newrow = traindata.ptr<float>(i);
int ii = i - int(usefulsample*rate);
int currentrow = stonevec[ii];
float* primerow = cvml.ptr<float>(currentrow);
for (int j = 0; j < featurecol; j++)
newrow[j] = primerow[j];
float* newlabelrow = trainlabel.ptr<float>(i);
float* primerlabelrow = res.ptr<float>(currentrow);
newlabelrow[0] = primerlabelrow[0];
}
//saperate into testset
for (int i = 0; i <usefulsample-int(usefulsample*rate); i++)
{
float* newrow = testdata.ptr<float>(i);
int iii = i + int(usefulsample*rate);
int currentrow = kuangvec[iii];
float* primerow = cvml.ptr<float>(currentrow);
for (int j = 0; j < featurecol; j++)
newrow[j] = primerow[j];
float* newlabelrow = testlabel.ptr<float>(i);
float* primerlabelrow = res.ptr<float>(currentrow);
newlabelrow[0] = primerlabelrow[0];
}
for (int i = usefulsample - int(usefulsample*rate); i <testnum; i++)
{
int ii = int(uselesssample*rate) + i - (usefulsample - int(usefulsample*rate));
float* newrow = testdata.ptr<float>(i);
int currentrow = stonevec[ii];
float* primerow = cvml.ptr<float>(currentrow);
for (int j = 0; j < featurecol; j++)
newrow[j] = primerow[j];
float* newlabelrow = testlabel.ptr<float>(i);
float* primerlabelrow = res.ptr<float>(currentrow);
newlabelrow[0] = primerlabelrow[0];
}
//trainset and testset have done!/////////////////////////////////////////////////////////////////
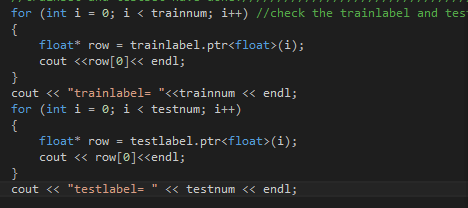
//for (int i = 0; i < trainnum; i++) //check the trainlabel and testlabel
//{
//float* row = trainlabel.ptr<float>(i);
//cout <<row[0]<< endl;
//}
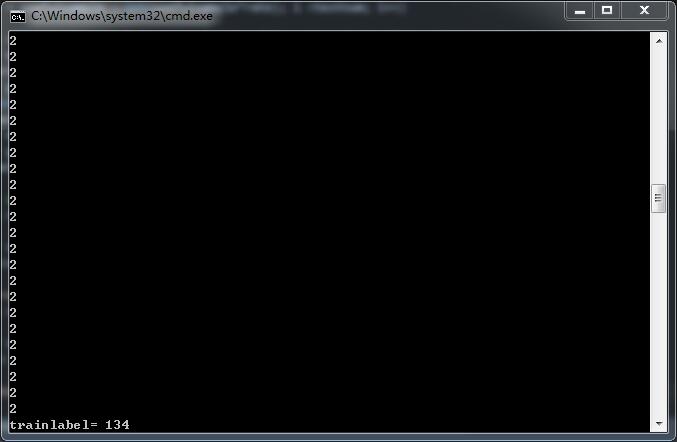
//cout << "trainlabel= "<<trainnum << endl;
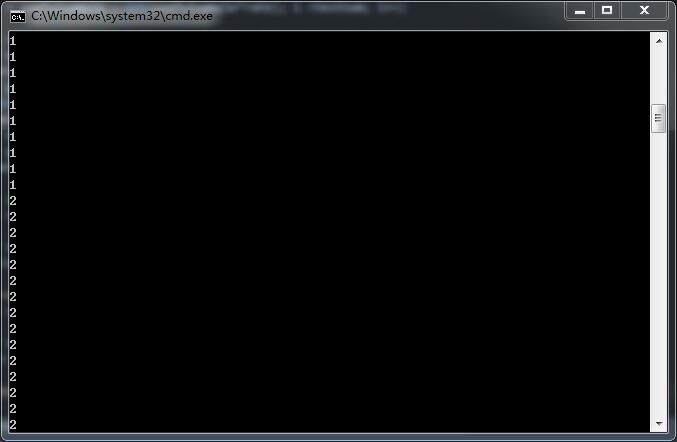
//for (int i = 0; i < testnum; i++)
//{
//float* row = testlabel.ptr<float>(i);
//cout << row[0]<<endl;
//}
CvMat traindata2 =traindata, trainlabel2 =trainlabel;
const CvMat* traindata3 = cvCreateMat(traindata2.rows, traindata2.cols, traindata2.type);
const CvMat* trainlabel3 = cvCreateMat(trainlabel2.rows, trainlabel2.cols, trainlabel2.type);
printf("Ready for Training ... ");
float priors[1000] = { 1, 1, 1, };
CvBoostParams params(CvBoost::GENTLE, 10, 0.95, 1, false, priors);
CvBoost boost;
bool update = false;
const CvMat* varIdx = 0;
const CvMat* sampleIdx = 0;
const CvMat* varType = 0;
const CvMat* missingDataMask = 0;
boost.train(traindata3,CV_ROW_SAMPLE, trainlabel3, varIdx, sampleIdx, varType, missingDataMask, params, update);
cout << "training done!" << endl;
// 1. Declare a couple of vectors to save the predictions of each sample
//std::vector train_responses, test_responses;
// 2. Calculate the training error
//float fl1 = boost.calc_error(&cvml, CV_TRAIN_ERROR, &train_responses);
// 3. Calculate the test error
//float fl2 = boost.calc_error(&cvml, CV_TEST_ERROR, &test_responses);
//printf("Error train %f \n", fl1);
//printf("Error test %f \n", fl2);
// Save the trained classifier
//boost.save("./trained_boost.xml", "boost");
//return EXIT_SUCCESS;
return 0;
}
我上面只是train 可是用Adaboost訓練時候就報錯 說只能用來二分類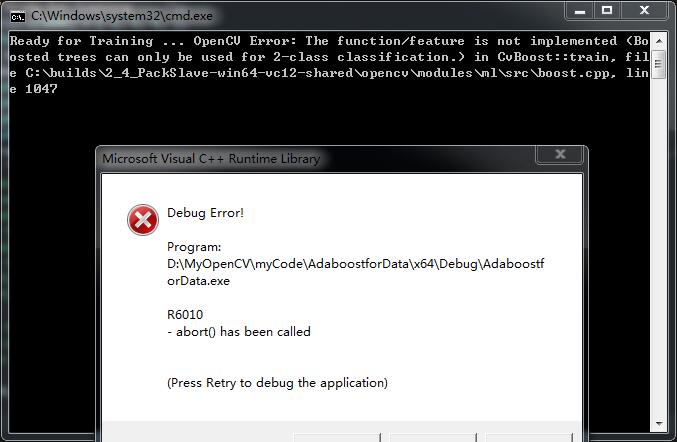
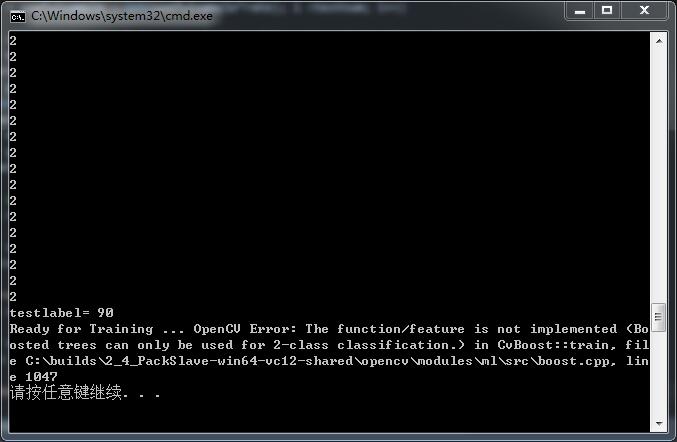
搞了一上午 終於知道為什麼了 從traindata轉成CvMat*時候沒有複製資料 只是複製了資訊頭 所以trian裡面是沒有任何資料的!!!太蠢了
改成了這樣:
#include "opencv2/core/core.hpp"
#include "opencv2/highgui/highgui.hpp"
#include "opencv2/imgproc/imgproc.hpp"
#include "opencv2/ml/ml.hpp"
#include <iostream>
#include<algorithm>
#include<opencv2/opencv.hpp>
using namespace cv;
using namespace std;
int main(int argc, char** argv)
{
//打亂順序結果在kuangvec[]和stonevec[]兩個數組裡 影象標號
const int uselesssample = 134, usefulsample = 90, allsample = 224,featurecol=1000;
//打亂順序 前90個為礦 後134個為廢石
int kuangvec[usefulsample], stonevec[uselesssample];
for (int i = 0; i < usefulsample; i++)
kuangvec[i] = i ;
for (int i = 0; i <uselesssample; i++)
stonevec[i] = usefulsample+i;
random_shuffle(kuangvec, kuangvec+usefulsample);
random_shuffle(stonevec, stonevec + uselesssample);
///////////////////////////////////////////////show fixed ranks
//for (int i = 0; i < usefulsample; i++)
//cout << kuangvec[i] << endl;
//cout << endl;
//for (int i = 0; i < uselesssample; i++)
//cout << stonevec[i] << endl;
/////////////////////////////////////////////////////////////////////read features
CvMLData cvmlprimer;
cvmlprimer.read_csv("features.csv");
cv::Mat cvml = cv::Mat(cvmlprimer.get_values(),true);
CvMLData resprimer;
resprimer.read_csv("labels.csv");
cv::Mat res = cv::Mat(resprimer.get_values(), true);
/////////////////////////////////////////////////////////////////////saperate into trainset randomly
const float rate =0.6;
int trainnum=int(usefulsample*rate)+int(uselesssample*rate), testnum=allsample-trainnum;
Mat traindata=Mat::zeros(trainnum, featurecol, cvml.type()), testdata=Mat::zeros(testnum, featurecol, cvml.type()), trainlabel=Mat::zeros(trainnum, 1, res.type()), testlabel=Mat::zeros(testnum,1, res.type());
for (int i = 0; i <int(usefulsample*rate); i++)
{
float* newrow = traindata.ptr<float>(i);
int currentrow = kuangvec[i];
float* primerow = cvml.ptr<float>(currentrow);
for (int j = 0; j < featurecol; j++)
newrow[j] = primerow[j];
float* newlabelrow = trainlabel.ptr<float>(i);
float* primerlabelrow = res.ptr<float>(currentrow);
newlabelrow[0] = primerlabelrow[0];
}
for (int i = int(usefulsample*rate); i <trainnum; i++)
{
float* newrow = traindata.ptr<float>(i);
int ii = i - int(usefulsample*rate);
int currentrow = stonevec[ii];
float* primerow = cvml.ptr<float>(currentrow);
for (int j = 0; j < featurecol; j++)
newrow[j] = primerow[j];
float* newlabelrow = trainlabel.ptr<float>(i);
float* primerlabelrow = res.ptr<float>(currentrow);
newlabelrow[0] = primerlabelrow[0];
}
//saperate into testset
for (int i = 0; i <usefulsample-int(usefulsample*rate); i++)
{
float* newrow = testdata.ptr<float>(i);
int iii = i + int(usefulsample*rate);
int currentrow = kuangvec[iii];
float* primerow = cvml.ptr<float>(currentrow);
for (int j = 0; j < featurecol; j++)
newrow[j] = primerow[j];
float* newlabelrow = testlabel.ptr<float>(i);
float* primerlabelrow = res.ptr<float>(currentrow);
newlabelrow[0] = primerlabelrow[0];
}
for (int i = usefulsample - int(usefulsample*rate); i <testnum; i++)
{
int ii = int(uselesssample*rate) + i - (usefulsample - int(usefulsample*rate));
float* newrow = testdata.ptr<float>(i);
int currentrow = stonevec[ii];
float* primerow = cvml.ptr<float>(currentrow);
for (int j = 0; j < featurecol; j++)
newrow[j] = primerow[j];
float* newlabelrow = testlabel.ptr<float>(i);
float* primerlabelrow = res.ptr<float>(currentrow);
newlabelrow[0] = primerlabelrow[0];
}
//trainset and testset have done!/////////////////////////////////////////////////////////////////
//for (int i = 0; i < trainnum; i++) //check the trainlabel and testlabel
//{
//float* row = trainlabel.ptr<float>(i);
//cout <<row[0]<< endl;
//}
//cout << "trainlabel= "<<trainnum << endl;
//for (int i = 0; i < testnum; i++)
//{
//float* row = testlabel.ptr<float>(i);
//cout << row[0]<<endl;
//}
//cout << "testlabel= " << testnum << endl;
CvMat traindata2 = traindata, trainlabel2 = trainlabel;
CvMat* traindata3 = cvCreateMat(traindata2.rows, traindata2.cols, traindata2.type);
cvCopy(&traindata2, traindata3);
CvMat* trainlabel3 = cvCreateMat(trainlabel2.rows, trainlabel2.cols, trainlabel2.type);
cvCopy(&trainlabel2, trainlabel3);
cout<<"Ready for Training ... "<<endl;
float priors[1000];
for (int i = 0; i < 1000; i++)
priors[i] = 1;
CvBoostParams params(CvBoost::GENTLE, 1000, 0.95, 1, false, priors);
CvBoost boost;
bool update = false;
const CvMat* varIdx = 0;
const CvMat* sampleIdx = 0;
const CvMat* varType = 0;
const CvMat* missingDataMask = 0;
boost.train(traindata3,CV_ROW_SAMPLE, trainlabel3, varIdx, sampleIdx, varType, missingDataMask, params, update);
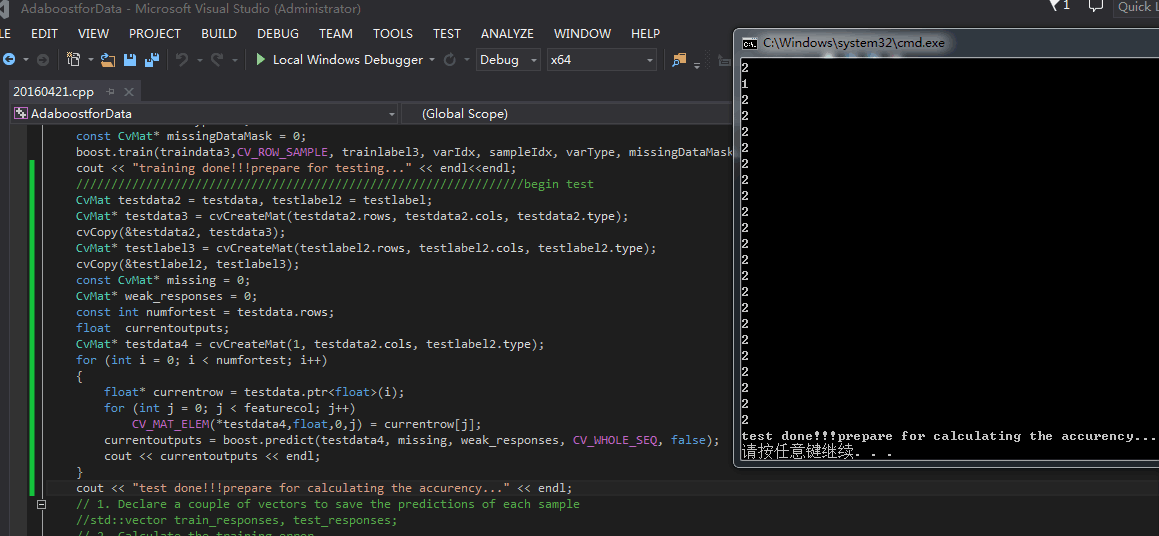
cout << "training done!!!prepare for testing..." << endl<<endl;
////////////////////////////////////////////////////////////////begin test
CvMat testdata2 = testdata, testlabel2 = testlabel;
CvMat* testdata3 = cvCreateMat(testdata2.rows, testdata2.cols, testdata2.type);
cvCopy(&testdata2, testdata3);
CvMat* testlabel3 = cvCreateMat(testlabel2.rows, testlabel2.cols, testlabel2.type);
cvCopy(&testlabel2, testlabel3);
const CvMat* missing = 0;
CvMat* weak_responses = 0;
const int numfortest = testdata.rows;
float outputs;
outputs=boost.predict(testdata3, missing, weak_responses, CV_WHOLE_SEQ, false);
// 1. Declare a couple of vectors to save the predictions of each sample
//std::vector train_responses, test_responses;
// 2. Calculate the training error
//float fl1 = boost.calc_error(&cvml, CV_TRAIN_ERROR, &train_responses);
// 3. Calculate the test error
//float fl2 = boost.calc_error(&cvml, CV_TEST_ERROR, &test_responses);
//printf("Error train %f \n", fl1);
//printf("Error test %f \n", fl2);
// Save the trained classifier
//boost.save("./trained_boost.xml", "boost");
//return EXIT_SUCCESS;
return 0;
}
我增加了把資料集和標籤隨機分為測試集和訓練集 還改了之前的錯誤 結果證明訓練可以了