
快速排序及優化(三路劃分等)
快速排序, 是最經典的排序演算法之一。快速排序擁有良好的時間複雜度,平均為
時間複雜度分析
首先說平均時間複雜度。以比較常用的從兩頭進行掃描的演算法為例,演算法主要分兩步:
1. 是快排的核心:“分趟”。就是“每一趟”下來,找到某一個元素應該待的位置,這個元素一般被稱為pivot;
2.再分別對pivot前後兩部分進行遞迴排序。
#include <iostream>
using namespace std;
int partition(int *a, int left, int right)
{
int 顯然,一趟下來,pivot被固定的位置越趨於中間,前後兩部分子序列的遞迴呼叫就越均衡,這時候時間複雜度是最小的。
T(n) <= n + 2T(n/2)
<= 2n + 4T(n/4)
<= 3n + 8T(n/8)
...
<= (log n)n + nT(1) = O(nlog n)因此,為
最差的情況下,也就是pivot被固定後的位置總是在最前面或最後面,導致前後兩部分子序列實際只是一個子序列。這也就意味著,原代排序列本身就是有序的,要麼從小到大,要麼從大到小。比如從小到大:此時,第一趟經過n-1次比較,將第一個元素固定在首位;第二趟經過n-2次比較,將第二個元素固定在第二位,以此類推,n個元素總共要比較
優化
優化大致有三種比較有效的方法。
使用插入排序
在子序列比較小的時候,其實插排是比較快的,因為對於有序的序列,插排可以達到
快排是在待排數列越趨近於有序時變得越慢,複雜度越高,呼叫插排可以很好的解決這個問題。
pivot選用中位數
對於一般的快排,我們直接簡單的就取最左或最右的資料作為pivot,這樣的話很可能遇到比較極端的pivot,使得劃分出來的左右子序列變得不均衡。如果選取最左、中間、最右這三個值的中位數的話,顯然會使得pivot更加“不偏激”,這樣劃分出來的左右子序列也會更加均衡。
選用中位數和呼叫插排一樣,都能避免數列比較有序時複雜度變高的問題。
三路劃分
快排是二路劃分的演算法。如果待排序列中重複元素過多,也會大大影響排序的效能。這時候,如果採用三路劃分,則會很好的避免這個問題。
如果一個帶排序列重複元素過多,我們先隨機選取一個pivot,設為T,那麼數列可以分為三部分:小於T,等於T,大於T:

等於T的部分就無需再參與後續的遞迴呼叫了,速度自然就大大提升了。
但是問題在於怎麼高效地將序列劃分為三部分!
如下圖,我們可以設定四個遊標,左端a、b,右端c、d。b、c的作用跟之前兩路劃分時候的左右遊標相同,就是從兩端向中間遍歷序列,並將遍歷到的元素與pivot比較,如果等於pivot,則移到兩端(b對應的元素移到左端,c對應的元素移到右端。移動的方式就是拿此元素和a或d對應的元素進行交換,所以a和d的作用就是記錄等於pivot的元素移動過後的邊界),反之,如果大於或小於pivot,還按照之前兩路劃分的方式進行移動。這樣一來,中間部分就和兩路劃分相同,兩頭是等於pivot的部分,我們只需要將這兩部分移動到中間即可。
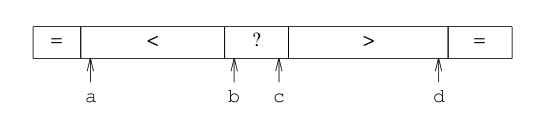

參考演算法如下,摘自http://blog.csdn.net/jlqCloud/article/details/46939703:
private void quickSort(int[] a, int left, int right) {
if (right <= left)
return;
/*
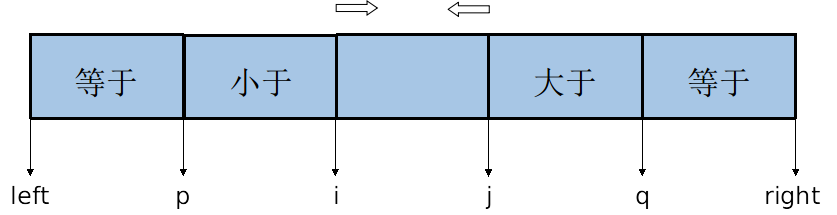
* 工作指標
* p指向序列左邊等於pivot元素的位置
* q指向序列右邊等於Pivot元素的位置
* i指向從左向右掃面時的元素
* j指向從右向左掃描時的元素
*/
int p, q, i, j;
int pivot;// 錨點
i = p = left;
j = q = right - 1;
/*
* 每次總是取序列最右邊的元素為錨點
*/
pivot = a[right];
while (true) {
/*
* 工作指標i從右向左不斷掃描,找小於或者等於錨點元素的元素
*/
while (i < right && a[i] <= pivot) {
/*
* 找到與錨點元素相等的元素將其交換到p所指示的位置
*/
if (a[i] == pivot) {
swap(a, i, p);
p++;
}
i++;
}
/*
* 工作指標j從左向右不斷掃描,找大於或者等於錨點元素的元素
*/
while (left <= j && a[j] >= pivot) {
/*
* 找到與錨點元素相等的元素將其交換到q所指示的位置
*/
if (a[j] == pivot) {
swap(a, j, q);
q--;
}
j--;
}
/*
* 如果兩個工作指標i j相遇則一趟遍歷結束
*/
if (i >= j)
break;
/*
* 將左邊大於pivot的元素與右邊小於pivot元素進行交換
*/
swap(a, i, j);
i++;
j--;
}
/*
* 因為工作指標i指向的是當前需要處理元素的下一個元素
* 故而需要退回到當前元素的實際位置,然後將等於pivot元素交換到序列中間
*/
i--;
p--;
while (p >= left) {
swap(a, i, p);
i--;
p--;
}
/*
* 因為工作指標j指向的是當前需要處理元素的上一個元素
* 故而需要退回到當前元素的實際位置,然後將等於pivot元素交換到序列中間
*/
j++;
q++;
while (q <= right) {
swap(a, j, q);
j++;
q++;
}
/*
* 遞迴遍歷左右子序列
*/
quickSort(a, left, i);
quickSort(a, j, right);
}
private void quick(int[] a) {
if (a.length > 0) {
quickSort(a, 0, a.length - 1);
}
}
private void swap(int[] arr, int a, int b) {
int temp = arr[a];
arr[a] = arr[b];
arr[b] = temp;
}三路劃分可以避免很多重複元素再次參與遞迴,對於有大量重複元素的待排序列,效率提高了不少。
以上只是理論上的總結,當然實踐起來程式碼也不難寫。在這裡推薦一篇有碼有實驗資料的文章,看後也是更加直觀形象,受益匪淺。
快排的優化其實對於一個電腦科學與技術的入門者來講,是一個不錯的思維上的砥礪,這種型別的東西多多探索,電腦科學“素養”自然慢慢就上去了。