
spark sql 實踐(續)
前言
之前一篇文章《spark sql 在mysql的應用實踐》 已經簡單描述了spark sql 在我們的業務場景的實踐、開發遇到的問題和叢集的佇列分配問題。這篇主要介紹spark dataset 的cache,瞭解其引數,基本原理和簡單的原始碼分析。
cache
實際開發過程中,有時候很多地方都會用到同一個dataset, 那麼每個地方遇到Action操作的時候都會對同一個運算元計算多次,這樣會造成執行效率低下的問題,而通過cache操作可以把dataset持久化到記憶體或者磁碟,提高執行效率。
cache的使用有兩種方式,cache()和persist();
/**
* Persist this RDD with /**
* Persist this RDD with the default storage level (`MEMORY_ONLY`).
*/
def persist(): this.type = persist(StorageLevel.MEMORY_ONLY)可以看到,cache只有一個預設的快取級別MEMORY_ONLY ,而persist可以根據情況設定其它的快取級別。
引數設定
/**
* :: DeveloperApi ::
* Flags for 從原始碼中可以看到,快取有以下幾種型別:
useDisk:使用硬碟(外存)
useMemory:使用記憶體
useOffHeap:使用堆外記憶體,堆外記憶體意味著把記憶體物件分配在Java虛擬機器的堆以外的記憶體,這些記憶體直接受作業系統管理(而不是虛擬機器)。這樣做的結果就是能保持一個較小的堆,以減少垃圾收集對應用的影響。這部分記憶體也會被頻繁的使用而且也可能導致OOM,它是通過儲存在堆中的DirectByteBuffer物件進行引用,可以避免堆和堆外資料進行來回複製。
deserialized:反序列化,將物件表示成一連串的位元組;而反序列化就表示將位元組恢復為物件的過程。序列化是物件永久化的一種機制,可以將物件及其屬性儲存起來,並能在反序列化後直接恢復這個物件 。
replication:備份數(在多個節點上備份,預設為1)
此外,還有快取級別的設定細化快取
/**
* Various [[org.apache.spark.storage.StorageLevel]] defined and utility functions for creating
* new storage levels.
*/
object StorageLevel {
val NONE = new StorageLevel(false, false, false, false)
val DISK_ONLY = new StorageLevel(true, false, false, false)
val DISK_ONLY_2 = new StorageLevel(true, false, false, false, 2)
val MEMORY_ONLY = new StorageLevel(false, true, false, true)
val MEMORY_ONLY_2 = new StorageLevel(false, true, false, true, 2)
val MEMORY_ONLY_SER = new StorageLevel(false, true, false, false)
val MEMORY_ONLY_SER_2 = new StorageLevel(false, true, false, false, 2)
val MEMORY_AND_DISK = new StorageLevel(true, true, false, true)
val MEMORY_AND_DISK_2 = new StorageLevel(true, true, false, true, 2)
val MEMORY_AND_DISK_SER = new StorageLevel(true, true, false, false)
val MEMORY_AND_DISK_SER_2 = new StorageLevel(true, true, false, false, 2)
val OFF_HEAP = new StorageLevel(true, true, true, false, 1)dataset與block
dataset的cache由spark的storage模組進行管理,具體實現由BlockManager完成,在邏輯上dataset以block為基本儲存單位,dataset的每個partition經過處理後唯一對應一個Block(BlockId 的格式為 rdd_RDD-ID_PARTITION-ID ),根據設定的級不同,block可以儲存在磁碟/堆內記憶體/堆外記憶體,在實現上,BlockManager用一個LinkedHashMap來管理堆內和堆外儲存記憶體中所有的 Block 物件的例項,只有在dataset的所有block都remove完之後,在driver端的jvm才會釋放對dataset的物件引用。
/**
* Component of the [[BlockManager]] which tracks metadata for blocks and manages block locking.
*
* The locking interface exposed by this class is readers-writer lock. Every lock acquisition is
* automatically associated with a running task and locks are automatically released upon task
* completion or failure.
*
* This class is thread-safe.
*/
private[storage] class BlockInfoManager extends Logging {
private type TaskAttemptId = Long
/**
* Used to look up metadata for individual blocks. Entries are added to this map via an atomic
* set-if-not-exists operation ([[lockNewBlockForWriting()]]) and are removed
* by [[removeBlock()]].
*/
@GuardedBy("this")
private[this] val infos = new mutable.HashMap[BlockId, BlockInfo]LinkedHashMap 的新增和刪除間接記錄了記憶體的申請和釋放,
/**
* Attempt to acquire the appropriate lock for writing a new block.
*
* This enforces the first-writer-wins semantics. If we are the first to write the block,
* then just go ahead and acquire the write lock. Otherwise, if another thread is already
* writing the block, then we wait for the write to finish before acquiring the read lock.
*
* @return true if the block did not already exist, false otherwise. If this returns false, then
* a read lock on the existing block will be held. If this returns true, a write lock on
* the new block will be held.
*/
def lockNewBlockForWriting(
blockId: BlockId,
newBlockInfo: BlockInfo): Boolean = synchronized {
logTrace(s"Task $currentTaskAttemptId trying to put $blockId")
lockForReading(blockId) match {
case Some(info) =>
// Block already exists. This could happen if another thread races with us to compute
// the same block. In this case, just keep the read lock and return.
false
case None =>
// Block does not yet exist or is removed, so we are free to acquire the write lock
infos(blockId) = newBlockInfo
lockForWriting(blockId)
true
}
}/**
* Removes the given block and releases the write lock on it.
*
* This can only be called while holding a write lock on the given block.
*/
def removeBlock(blockId: BlockId): Unit = synchronized {
logTrace(s"Task $currentTaskAttemptId trying to remove block $blockId")
infos.get(blockId) match {
case Some(blockInfo) =>
if (blockInfo.writerTask != currentTaskAttemptId) {
throw new IllegalStateException(
s"Task $currentTaskAttemptId called remove() on block $blockId without a write lock")
} else {
infos.remove(blockId)
blockInfo.readerCount = 0
blockInfo.writerTask = BlockInfo.NO_WRITER
writeLocksByTask.removeBinding(currentTaskAttemptId, blockId)
}
case None =>
throw new IllegalArgumentException(
s"Task $currentTaskAttemptId called remove() on non-existent block $blockId")
}
notifyAll()
}可能有同學已經發現,新增block的時候用的是寫入鎖,實際上,block資訊的讀寫就是用的讀寫鎖提高多執行緒操作的效能的;因為每個executor在執行時會生成一個執行緒池對每個partition(即block)進行讀寫,為了保證多執行緒下的執行緒安全和讀寫效能,blockManage這裡使用了讀寫鎖和ConcurrentHashMultiset。
executor原始碼:
/**
* Spark executor, backed by a threadpool to run tasks.
*
* This can be used with Mesos, YARN, and the standalone scheduler.
* An internal RPC interface is used for communication with the driver,
* except in the case of Mesos fine-grained mode.
*/
private[spark] class Executor(
executorId: String,
executorHostname: String,
env: SparkEnv,
userClassPath: Seq[URL] = Nil,
isLocal: Boolean = false)
extends Logging {
logInfo(s"Starting executor ID $executorId on host $executorHostname")
// Application dependencies (added through SparkContext) that we've fetched so far on this node.
// Each map holds the master's timestamp for the version of that file or JAR we got.
private val currentFiles: HashMap[String, Long] = new HashMap[String, Long]()
private val currentJars: HashMap[String, Long] = new HashMap[String, Long]()
private val EMPTY_BYTE_BUFFER = ByteBuffer.wrap(new Array[Byte](0))
private val conf = env.conf
// No ip or host:port - just hostname
Utils.checkHost(executorHostname, "Expected executed slave to be a hostname")
// must not have port specified.
assert (0 == Utils.parseHostPort(executorHostname)._2)
// Make sure the local hostname we report matches the cluster scheduler's name for this host
Utils.setCustomHostname(executorHostname)
if (!isLocal) {
// Setup an uncaught exception handler for non-local mode.
// Make any thread terminations due to uncaught exceptions kill the entire
// executor process to avoid surprising stalls.
Thread.setDefaultUncaughtExceptionHandler(SparkUncaughtExceptionHandler)
}
// Start worker thread pool
private val threadPool = ThreadUtils.newDaemonCachedThreadPool("Executor task launch worker")
private val executorSource = new ExecutorSource(threadPool, executorId)BlockInfo 原始碼:
/**
* Tracks metadata for an individual block.
*
* Instances of this class are _not_ thread-safe and are protected by locks in the
* [[BlockInfoManager]].
*
* @param level the block's storage level. This is the requested persistence level, not the
* effective storage level of the block (i.e. if this is MEMORY_AND_DISK, then this
* does not imply that the block is actually resident in memory).
* @param classTag the block's [[ClassTag]], used to select the serializer
* @param tellMaster whether state changes for this block should be reported to the master. This
* is true for most blocks, but is false for broadcast blocks.
*/
private[storage] class BlockInfo(
val level: StorageLevel,
val classTag: ClassTag[_],
val tellMaster: Boolean) {
/**
* The size of the block (in bytes)
*/
def size: Long = _size
def size_=(s: Long): Unit = {
_size = s
checkInvariants()
}
private[this] var _size: Long = 0
/**
* The number of times that this block has been locked for reading.
*/
def readerCount: Int = _readerCount
def readerCount_=(c: Int): Unit = {
_readerCount = c
checkInvariants()
}
private[this] var _readerCount: Int = 0
/**
* The task attempt id of the task which currently holds the write lock for this block, or
* [[BlockInfo.NON_TASK_WRITER]] if the write lock is held by non-task code, or
* [[BlockInfo.NO_WRITER]] if this block is not locked for writing.
*/
def writerTask: Long = _writerTask
def writerTask_=(t: Long): Unit = {
_writerTask = t
checkInvariants()
}
private[this] var _writerTask: Long = BlockInfo.NO_WRITER
private def checkInvariants(): Unit = {
// A block's reader count must be non-negative:
assert(_readerCount >= 0)
// A block is either locked for reading or for writing, but not for both at the same time:
assert(_readerCount == 0 || _writerTask == BlockInfo.NO_WRITER)
}
checkInvariants()
}cache過程
dataset與blockManager的關係如圖所示:

- 在快取dataset到記憶體之前,我們讀取dataset 的partition的每行record的,些 Record 的物件例項在邏輯上佔用了 JVM 堆內記憶體的 other 部分的空間,同一 Partition 的不同 Record 的空間並不連續。RDD 在快取到儲存記憶體之後,Partition 被轉換成 Block,Record 在堆內或堆外儲存記憶體中佔用一塊連續的空間。將Partition由不連續的儲存空間轉換為連續儲存空間的過程,Spark稱之為”展開”(Unroll)。
- Block 有序列化和非序列化兩種儲存格式,具體以哪種方式取決於該 RDD 的儲存級別。非序列化的 Block 以一種 DeserializedMemoryEntry 的資料結構定義,用一個數組儲存所有的物件例項,序列化的 Block 則以 SerializedMemoryEntry的資料結構定義,用位元組緩衝區(ByteBuffer)來儲存二進位制資料。
因為不能保證儲存空間可以一次容納 Iterator 中的所有資料,當前的計算任務在 Unroll 時要向 MemoryManager 申請足夠的 Unroll 空間來臨時佔位,空間不足則 Unroll 失敗,空間足夠時可以繼續進行。對於序列化的 Partition,其所需的 Unroll 空間可以直接累加計算,一次申請。而非序列化的 Partition 則要在遍歷 Record 的過程中依次申請,即每讀取一條 Record,取樣估算其所需的 Unroll 空間並進行申請,空間不足時可以中斷,釋放已佔用的 Unroll 空間。如果最終 Unroll 成功,當前 Partition 所佔用的 Unroll 空間被轉換為正常的快取 RDD 的儲存空間,如下圖所示:
由於同一個 Executor 的所有的計算任務共享有限的儲存記憶體空間,當有新的 Block 需要快取但是剩餘空間不足且無法動態佔用時,就要對 LinkedHashMap 中的舊 Block 進行淘汰,而被淘汰的 Block 如果其儲存級別中同時包含儲存到磁碟的要求,則要對其進行落盤,否則直接刪除該 Block,按照最近最少使用(LRU)的順序淘汰,直到滿足新 Block 所需的空間。
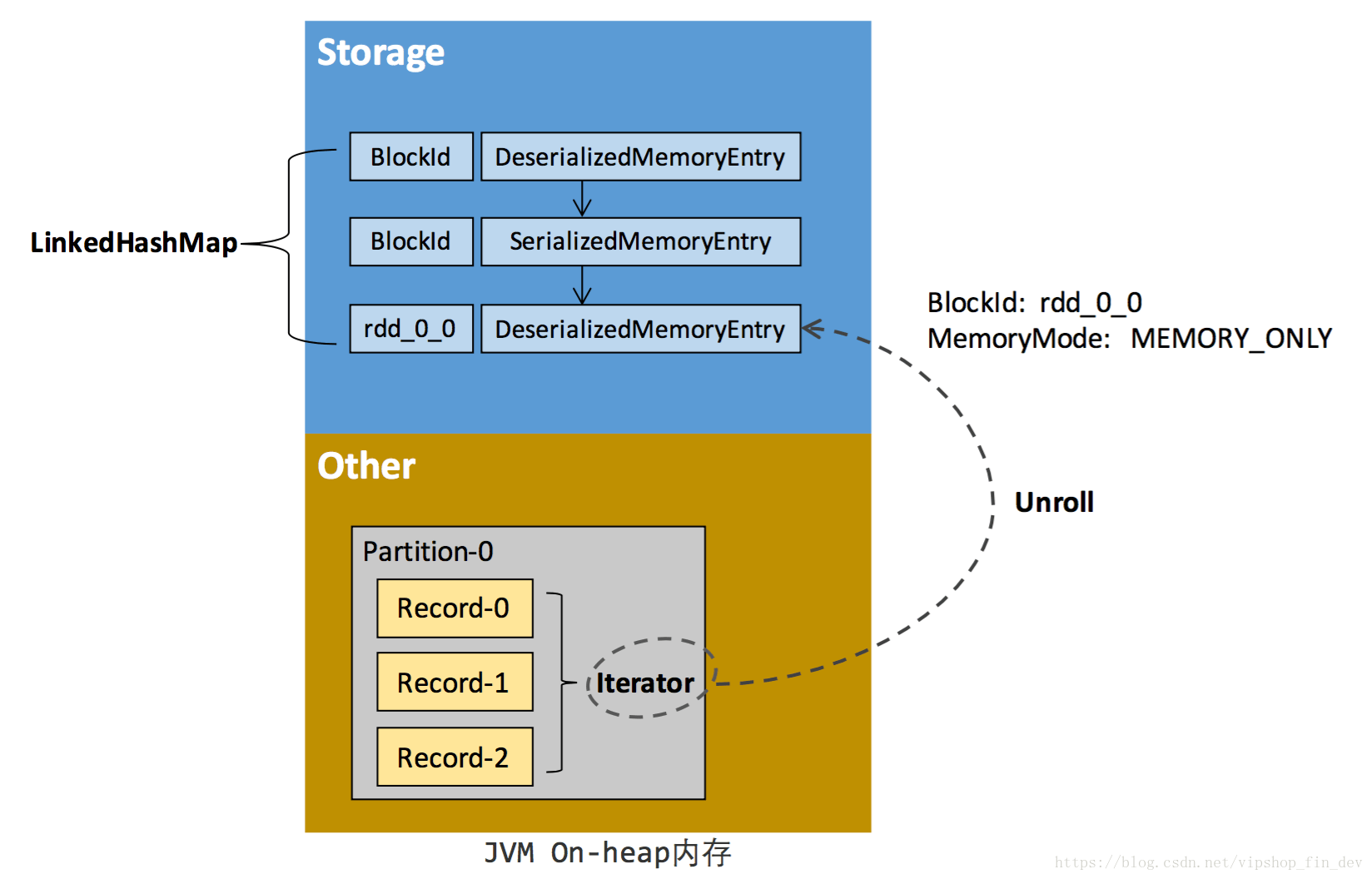
由以上的cache過程可以看出,cache操作在堆內進行了一次記憶體的重排,讓原先partition不連續的儲存空間變成一塊連續的記憶體儲存空間,只有當記憶體不足以存放新的block時才會溢位到磁碟,因此,在快取之後的dataset上的讀取執行上效率更高。
刪除cache
對於cache之後的dataset,在executor執行過程中會以最近最少使用的(LRU)方式丟棄舊資料分割槽,如果確認資料不使用,可以使用dataset.unpersist()方式釋放記憶體,但這只是將remove rdd block的訊息發到drive 與executor的執行佇列,並非立即執行,所以要避免大量的rdd、dataset同時remove造成通訊佇列阻塞。
/**
* SparkContext.scala
* Unpersist an RDD from memory and/or disk storage
*/
private[spark] def unpersistRDD(rddId: Int, blocking: Boolean = true) {
env.blockManager.master.removeRdd(rddId, blocking)
persistentRdds.remove(rddId)
listenerBus.post(SparkListenerUnpersistRDD(rddId))
}以上是我對dataset cache的瞭解和對參考資料的整理,歡迎批評指正。
賴澤坤 @vip.fcs