
生成對抗網路——GAN(一)
Generative adversarial network
據有關媒體統計:CVPR2018的論文裡,有三分之一的論文與GAN有關
由此可見,GAN在視覺領域的未來多年內,將是一片沃土(CVer們是時候入門GAN了)。而發現這片礦源的就是GAN之父,Goodfellow大神。
生成對抗網路GAN,是當今的一大熱門研究方向。在2014年,被Goodfellow大神提出來,當時的G神還只是蒙特利爾大學的博士生而已。
GAN之父的主頁:
http://www.iangoodfellow.com/
入坑GAN,首先需要理由,GAN能做什麼,為什麼要學GAN。
GAN的初衷就是生成不存在於真實世界的資料,類似於使得 AI具有創造力
- AI作家,AI畫家等需要創造力的AI體;
- 將模糊圖變清晰(去雨,去霧,去抖動,去馬賽克等),這需要AI具有所謂的“想象力”,能腦補情節;
- 進行資料增強,根據已有資料生成更多新資料供以feed,可以減緩模型過擬合現象。
以上的場景都可以找到相應的paper。而且GAN的用處也遠不止此,期待我們繼續挖掘,是發論文的好方向哦
GAN的原理介紹
這裡介紹的是原生的GAN演算法,雖然有一些不足,但提供了一種生成對抗性的新思路。放心,我這篇博文不會堆一大堆公式,只會提供一種理解思路。
理解GAN的兩大護法G和D
G是generator,生成器: 負責憑空捏造資料出來
D是discriminator,判別器: 負責判斷資料是不是真資料
這樣可以簡單的看作是兩個網路的博弈過程。在最原始的GAN論文裡面,G和D都是兩個多層感知機網路。首先,注意一點,GAN操作的資料不一定非得是影象資料,不過為了更方便解釋,我在這裡用影象資料為例解釋以下GAN:
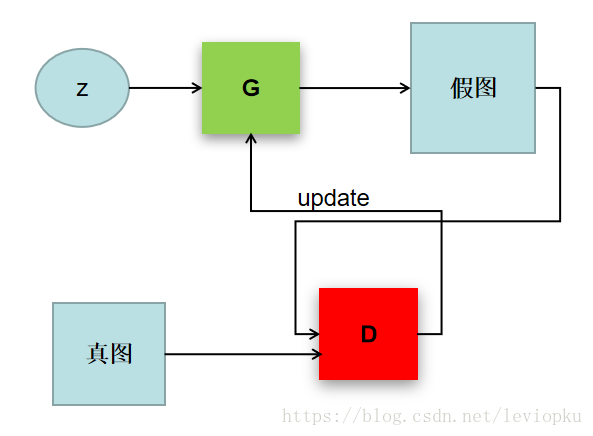
稍微解釋以下上圖,z是隨機噪聲(就是隨機生成的一些數,也就是GAN生成影象的源頭)。D通過真圖和假圖的資料(相當於天然label),進行一個二分類神經網路訓練(想各位必再熟悉不過了)。G根據一串隨機數就可以捏造一個“假影象”出來,用這些假圖去欺騙D,D負責辨別這是真圖還是假圖,會給出一個score。比如,G生成了一張圖,在D這裡得分很高,那證明G是很成功的;如果D能有效區分真假圖,則G的效果還不太好,需要調整引數。GAN就是這麼一個博弈的過程。
那麼,GAN是怎麼訓練呢?
根據GAN的訓練演算法,我畫一張圖:
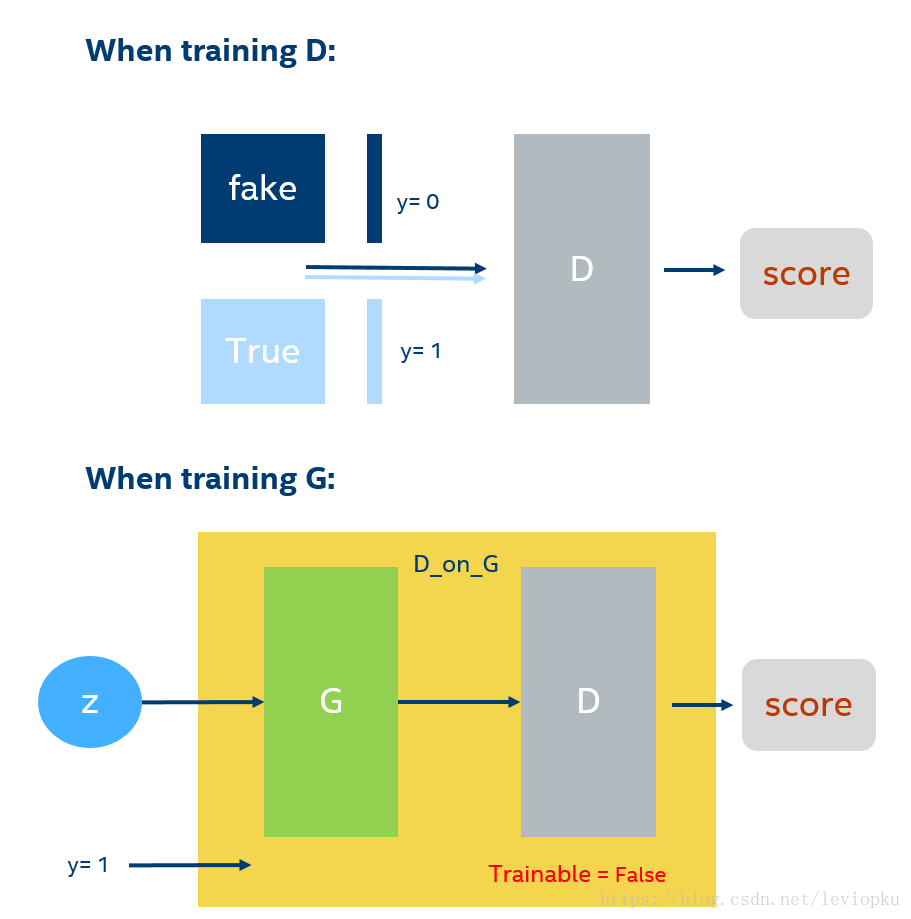
GAN的訓練在同一輪梯度反傳的過程中可以細分為2步,先訓練D在訓練G;注意不是等所有的D訓練好以後,才開始訓練G,因為D的訓練也需要上一輪梯度反傳中G的輸出值作為輸入。
當訓練D的時候,上一輪G產生的圖片,和真實圖片,直接拼接在一起,作為x。然後根據,按順序擺放0和1,假圖對應0,真圖對應1。然後就可以通過,x輸入生成一個score(從0到1之間的數),通過score和y組成的損失函式,就可以進行梯度反傳了。(我在圖片上舉的例子是batch = 1,len(y)=2*batch,訓練時通常可以取較大的batch)
當訓練G的時候, 需要把G和D當作一個整體,我在這裡取名叫做’D_on_G’。這個整體(下面簡稱DG系統)的輸出仍然是score。輸入一組隨機向量,就可以在G生成一張圖,通過D對生成的這張圖進行打分,這就是DG系統的前向過程。score=1就是DG系統需要優化的目標,score和y=1之間的差異可以組成損失函式,然後可以反向傳播梯度。注意,這裡的D的引數是不可訓練的。這樣就能保證G的訓練是符合D的打分標準的。這就好比:如果你參加考試,你別指望能改變老師的評分標準
需要注意的是,整個GAN的整個過程都是無監督的(後面會有監督性GAN比如cGAN),怎麼理解這裡的無監督呢?
這裡,給的真圖是沒有經過人工標註的,你只知道這是真實的圖片,比如全是人臉,而系統裡的D並不知道來的圖片是什麼玩意兒,它只需要分辨真假。G也不知道自己生成的是什麼玩意兒,反正就是學真圖片的樣子騙D。
正由於GAN的無監督,在生成過程中,G就會按照自己的意思天馬行空生成一些“詭異”的圖片,可怕的是D還能給一個很高的分數。比如,生成人臉極度扭曲的圖片。這就是無監督目的性不強所導致的,所以在同年的NIPS大會上,有一篇論文conditional GAN就加入了監督性進去,將可控性增強,表現效果也好很多。