
生成對抗網路GAN---生成mnist手寫數字影象示例(附程式碼)
Ian J. Goodfellow等人於2014年在論文Generative Adversarial Nets中提出了一個通過對抗過程估計生成模型的新框架。框架中同時訓練兩個模型:一個生成模型(generative model)G,用來捕獲資料分佈;一個判別模型(discriminative model)D,用來估計樣本來自於訓練資料的概率。G的訓練過程是將D錯誤的概率最大化。可以證明在任意函式G和D的空間中,存在唯一的解決方案,使得G重現訓練資料分佈,而D=0.5。
生成對抗網路(GAN,Generative Adversarial Networks)的基本原理很簡單:假設有兩個網路,生成網路G和判別網路D。生成網路G接受一個隨機的噪聲z並生成圖片,記為G(z);判別網路D的作用是判別一張圖片x是否真實,對於輸入x,D(x)是x為真實圖片的概率。在訓練過程中, 生成器努力讓生成的圖片更加真實從而使得判別器無法辨別影象的真假,而D的目標就是儘量把分辨出真實圖片和生成網路G產出的圖片,這個過程就類似於二人博弈,G和D構成了一個動態的“博弈過程”。
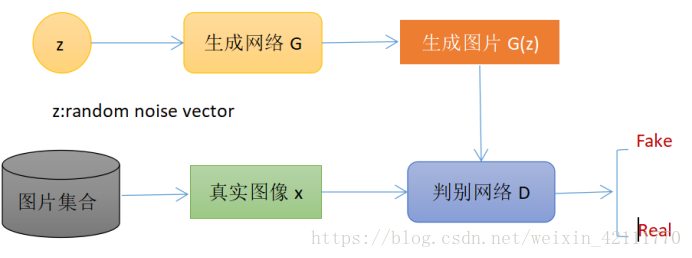
對於GAN更加直觀的理解:生成模型可以被看做是一個偽造團隊,試圖生產假幣並且在不被發現的情況下使用, 而判別模型則類似於警察,嘗試檢查是否為假幣。偽造團隊的目的是生產出警察識別不出的假幣,而警察則是想更加精確地識別出假幣,因此在這個遊戲中,兩個團隊因為各自目的而不斷改進它們的方法直到偽造團隊生產的假幣警察分辨不出來。
上面講述生成對抗網路的基本原理, 為了能夠更深此理解GAN,下面我們使用GAN來生成MNIST資料集。
import tensorflow as tf import numpy as np import os from tensorflow.examples.tutorials.mnist import input_data from matplotlib import pyplot as plt BATCH_SIZE = 64 UNITS_SIZE = 128 LEARNING_RATE = 0.001 EPOCH = 300 SMOOTH = 0.1 mnist = input_data.read_data_sets('/mnist_data/', one_hot=True) # 生成模型 def generatorModel(noise_img, units_size, out_size, alpha=0.01): with tf.variable_scope('generator'): FC = tf.layers.dense(noise_img, units_size) reLu = tf.nn.leaky_relu(FC, alpha) drop = tf.layers.dropout(reLu, rate=0.2) logits = tf.layers.dense(drop, out_size) outputs = tf.tanh(logits) return logits, outputs # 判別模型 def discriminatorModel(images, units_size, alpha=0.01, reuse=False): with tf.variable_scope('discriminator', reuse=reuse): FC = tf.layers.dense(images, units_size) reLu = tf.nn.leaky_relu(FC, alpha) logits = tf.layers.dense(reLu, 1) outputs = tf.sigmoid(logits) return logits, outputs # 損失函式 """ 判別器的目的是: 1. 對於真實圖片,D要為其打上標籤1 2. 對於生成圖片,D要為其打上標籤0 生成器的目的是:對於生成的圖片,G希望D打上標籤1 """ def loss_function(real_logits, fake_logits, smooth): # 生成器希望判別器判別出來的標籤為1; tf.ones_like()建立一個將所有元素都設定為1的張量 G_loss = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=fake_logits, labels=tf.ones_like(fake_logits)*(1-smooth))) # 判別器識別生成器產出的圖片,希望識別出來的標籤為0 fake_loss = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=fake_logits, labels=tf.zeros_like(fake_logits))) # 判別器判別真實圖片,希望判別出來的標籤為1 real_loss = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=real_logits, labels=tf.ones_like(real_logits)*(1-smooth))) # 判別器總loss D_loss = tf.add(fake_loss, real_loss) return G_loss, fake_loss, real_loss, D_loss # 優化器 def optimizer(G_loss, D_loss, learning_rate): train_var = tf.trainable_variables() G_var = [var for var in train_var if var.name.startswith('generator')] D_var = [var for var in train_var if var.name.startswith('discriminator')] # 因為GAN中一共訓練了兩個網路,所以分別對G和D進行優化 G_optimizer = tf.train.AdamOptimizer(learning_rate).minimize(G_loss, var_list=G_var) D_optimizer = tf.train.AdamOptimizer(learning_rate).minimize(D_loss, var_list=D_var) return G_optimizer, D_optimizer # 訓練 def train(mnist): image_size = mnist.train.images[0].shape[0] real_images = tf.placeholder(tf.float32, [None, image_size]) fake_images = tf.placeholder(tf.float32, [None, image_size]) #呼叫生成模型生成影象G_output G_logits, G_output = generatorModel(fake_images, UNITS_SIZE, image_size) # D對真實影象的判別 real_logits, real_output = discriminatorModel(real_images, UNITS_SIZE) # D對G生成影象的判別 fake_logits, fake_output = discriminatorModel(G_output, UNITS_SIZE, reuse=True) # 計算損失函式 G_loss, real_loss, fake_loss, D_loss = loss_function(real_logits, fake_logits, SMOOTH) # 優化 G_optimizer, D_optimizer = optimizer(G_loss, D_loss, LEARNING_RATE) saver = tf.train.Saver() step = 0 with tf.Session() as session: session.run(tf.global_variables_initializer()) for epoch in range(EPOCH): for batch_i in range(mnist.train.num_examples // BATCH_SIZE): batch_image, _ = mnist.train.next_batch(BATCH_SIZE) # 對影象畫素進行scale,tanh的輸出結果為(-1,1) batch_image = batch_image * 2 -1 # 生成模型的輸入噪聲 noise_image = np.random.uniform(-1, 1, size=(BATCH_SIZE, image_size)) # session.run(G_optimizer, feed_dict={fake_images:noise_image}) session.run(D_optimizer, feed_dict={real_images: batch_image, fake_images: noise_image}) step = step + 1 # 判別器D的損失 loss_D = session.run(D_loss, feed_dict={real_images: batch_image, fake_images:noise_image}) # D對真實圖片 loss_real =session.run(real_loss, feed_dict={real_images: batch_image, fake_images: noise_image}) # D對生成圖片 loss_fake = session.run(fake_loss, feed_dict={real_images: batch_image, fake_images: noise_image}) # 生成模型G的損失 loss_G = session.run(G_loss, feed_dict={fake_images: noise_image}) print('epoch:', epoch, 'loss_D:', loss_D, ' loss_real', loss_real, ' loss_fake', loss_fake, ' loss_G', loss_G) model_path = os.getcwd() + os.sep + "mnist.model" saver.save(session, model_path, global_step=step) def main(argv=None): train(mnist) if __name__ == '__main__': tf.app.run()
上述是訓練模型,下面是測試模型,依據訓練模型訓練的引數。generatorImage函式生成手寫字型圖片, 在這裡顯示了25張圖片。 生成影象如下圖1所示,還能夠大略猜出生成的圖片中的數字。
import tensorflow as tf
import numpy as np
from matplotlib import pyplot as plt
import pickle
import mnist_GAN
UNITS_SIZE = mnist_GAN.UNITS_SIZE
def generatorImage(image_size):
sample_images = tf.placeholder(tf.float32, [None, image_size])
G_logits, G_output = mnist_GAN.generatorModel(sample_images, UNITS_SIZE, image_size)
saver = tf.train.Saver()
with tf.Session() as session:
session.run(tf.global_variables_initializer())
saver.restore(session, tf.train.latest_checkpoint('.'))
sample_noise = np.random.uniform(-1, 1, size=(25, image_size))
samples = session.run(G_output, feed_dict={sample_images:sample_noise})
with open('samples.pkl', 'wb') as f:
pickle.dump(samples, f)
def show():
with open('samples.pkl', 'rb') as f:
samples = pickle.load(f)
fig, axes = plt.subplots(figsize=(7, 7), nrows=5, ncols=5, sharey=True, sharex=True)
for ax, image in zip(axes.flatten(), samples):
ax.xaxis.set_visible(False)
ax.yaxis.set_visible(False)
ax.imshow(image.reshape((28, 28)), cmap='Greys_r')
plt.show()
def main(argv=None):
image_size = mnist_GAN.mnist.train.images[0].shape[0]
generatorImage(image_size)
show()
if __name__ == '__main__':
tf.app.run()
上述基於MNIST資料集構造了一個簡單的GAN模型,對於生成模型和判別模型,僅僅使用了簡單的神經網路,對於影象的處理,卷積神經網路更勝一籌,如果將生成模型和判別模型改為深度卷積網路,那麼生成更加清晰的圖片。 而且目前也有各種GAN變體,後續慢慢整理。