
Stereo Vision-based Semantic 3D Object and Ego-motion Tracking for Autonomous Driving
Peiliang Li、Tong Qin、沈劭劼
香港科技大學
摘要
我們提出一種基於立體相機的方法來追蹤複雜自動駕駛環境中相機的運動和3D語義物件。取代了直接還原3D立體輪廓的端到端方法,我們提出使用簡易標記的2D檢測和離散視點分類與一個輕量級的語義推斷方法一同去獲得粗略的3D物件測量值。基於在複雜環境中魯棒的半自動物件感知相機姿態追蹤,結合我們新的動態物件集束調整方法去融合時間稀疏對應特徵和3D語義測量方法,我們獲得3D物體姿態,速度、動態點雲估計和推斷準確性和時間一致性。我們提出的方法在不同的場景中表現。與最先進的解決方案比較了自我運動估計和物體定位。
關鍵字:語義SLAM、3D物體定位、視覺里程計
1 介紹
定位運動物件和估計3D空間中相機運動是自動駕駛的關鍵任務。目前,這些目標都分別通過端到端3D物件檢測方法和傳統的視覺SLAM方法來探索。然而,很難直接在自動駕駛場景中使用這些方法。對於3D物件檢測存在兩個主要的問題:1、端到端的3D迴歸方法需要很多訓練資料並且需要很大的工作量去精確的標記三維空間中所有物件3D盒子。2、例如3D檢測產生與幀無關的結果,在連續感知的自動駕駛中的一致性會不夠。為了克服這兩個問題,我們提出了一個輕量級的僅以依賴2D物體檢測和離散的觀測點分類的語義3D盒子推斷方法。相比於直接3D迴歸,2D檢測和分類任務很容易去訓練,並且訓練資料可以很容易僅用2D影象去標記。然而,提出的3D盒子推斷仍然與幀無關並且以例項2D檢測精度為條件。另一方面,眾所周知的SLAM方法由於精確的幾何特徵約束可以準確的追蹤相機運動。受此啟發,我們可以相似的利用稀疏特徵關聯對物體相關運動約束去增強時間一致性。但是,例項物體位姿不能沒有語義先驗單純的從特徵測量中獲得。出於這個目的,由於語義和特徵資訊的互補性,我們整合我們的例項語義推斷模型和時間特徵相關性到一個緊耦合的優化框架,這樣可以連續追蹤3D物件並且用例項準確性和時間一致性來恢復動態稀疏點雲。受益於物件範圍感知屬性,我們的系統可以魯棒的估計相機位姿而不受動態物體的影響。多虧時間幾何一致性,我們可以連續的追蹤物件即使是在極端截斷的情況下,就是在物件位姿很難進行例項推斷。此外,我們使用運動學模型去檢測車輛確保方向一致性和運動估計;對於特徵觀測較少的遠距離車輛,也起到了很好的平滑作用。只依賴於一種成熟的2D檢測和物體分類網路,我們的系統在魯棒自身運動估計和多種場景下3D物件追蹤有很好的表現能力。主要的貢獻總結如下。
- 一個輕量級的只使用2D物件檢測和推薦的觀測點分類的3D盒推斷方法,這樣為目標特徵提取提供了目標再投影輪廓和遮擋掩模。它也是後續優化的語義度量模型。
- 一種新的動態物件束調整方法,它將語義和特徵度量緊密地結合在一起,連續跟蹤例項物件狀態精確性和時態一致性。
- 對不同的場景進行演示,以顯示所建議的系統的實用性。
2 相關工作
本文綜述了基於語義SLAM和基於學習影象的三維物體檢測的相關工作。
語義SLAM
隨著二維目標檢測技術的發展,一些與語義理解有關的聯合SLAM出現了,我們從三個方面來討論。第一個是語義輔助定位:重點在於通過將僅為一維的目標度量大小納入估計框架來糾正單目視覺里程計的的全域性尺度。在這兩個工作中,分別進行了室內小物體和室外實驗。提出了一種物件資料關聯方法,當重新觀察以前的物體時在概率公式中顯示了它的漂移校正能力。然而,通過將二維包圍框視為點進行訓練它忽略了目標的方向。在參考文獻[10]中,作者通過計算一個永久矩陣僅從先驗語義圖中的物件觀察來處理定位任務。第二種是SLAM輔助目標檢測和重建。開發二維物體識別系統,在攝像機定位的幫助下,它對視點的變化具有很強的魯棒性。而參考文獻[12]則使用視覺慣性測量進行置信度增長的3d物件檢測。參考文獻[13,14]分別用單目和RGBD SLAM融合點雲重建稠密的三維物體表面。最後,第三類是對相機和物體姿態的聯合估計:用預編譯的二進位制詞袋,定位資料集中的物件,並迴圈修正地圖尺度。在參考文獻[16,17]中,作者提出了一種語義SfM方法,同時考慮到相機、物體和場景組成的聯合估計。然而,這些方法都沒有展現出解決動態物件影響的能力,更沒有充分利用二維邊界框資料(中心、寬度和高度)和三維物體尺寸。也有一些現有的工作[18,19,20,21]建立稠密地圖,並用語義標籤分割。這些工作超出了本文的範圍,因此我們將不進行詳細討論。
3D物體檢測
通過深度學習的方法從影象中推斷出物體的姿態,為三維物體的定位提供了一種替代的方法。參考文獻[22,23]使用這個先驗模型去解釋3D物件位姿,其中分別採用稠密形狀和線框模型。在參考文獻[24]中,使用體素模型來檢測具有可見特殊模型的物件三維姿態。類似於文獻[6]中2D物件檢測提出的方法,參考文獻[1]提出利用從立體影象中計算出的深度資訊生成3D模型,參考文獻[2]利用地面假設和附加的分割特徵生成三維候選;然後使用r-cnn進行候選評分和目標識別。這種提出的用於生成或模型擬合的高維特徵對於訓練和使用的計算都很複雜。取代直接生成3D包圍盒的方法,參考文獻[25]在不同的階段復原物件方向和尺寸;然後2D-3D包圍盒幾何約束被用來計算3D物件位姿,在物件截斷的情況下其表現受限於完全的依賴於2D包圍框例項。
在本文中,我們研究了現有工作的優缺點,並提出了一種完整的自主駕駛感知解決方案,通過充分利用例項語義先驗和精確特徵時空關聯來實現對相機和靜態或動態物件在不同環境中的魯棒和連續狀態估計。
3 概覽
我們的語義跟蹤系統有三個主要模組,如圖2所示。第一個模組執行2D物件檢測和視點分類,根據2D包圍框和3D包圍盒頂點之間的約束,粗略地推斷出物體所處的位置。第二個模組是特徵提取與匹配,它將所有推斷的3D包圍盒投影到2D影象中,以獲得目標輪廓和遮擋。然後引導特徵匹配得到立體影象和時態影象的魯棒特徵關聯。在第三個模組中我們整合了所有的語義資訊、特徵測量值到一個緊耦合的優化方法中。此外還將運動學模型應用於汽車以獲得一致的運動估計。
4 觀測點分類與3D包圍盒推導
我們的語義測量包括2D物件包圍框盒和觀測點分類。在此基礎上,可以大致實時推匯出物件的近似位姿。
4.1 觀測點分類
2D目標檢測可以通過最先進的物件檢測器來實現,如Faster R-cnn、yolo等。我們在系統中使用Faster R-cnn,因為它在小物體上表現良好。由於實時性要求,只使用左影象進行目標檢測。網路架構如圖2(a)所示。不像參考文獻[6]中最初知識單純的做物件分類,我們在最後的FC層中添加了子類別分類來表示物件的水平和垂直離散觀測點。如圖3(a)所示,我們將連續目標觀測角劃分為八個水平和兩個垂直的觀測點。共有16個水平和垂直視點分類組合,我們基於3D包圍盒的重投影將與2D包圍框緊密配合的假設,可以生成2D包圍框中的邊緣和3D包圍盒頂點之間的關聯。這些關聯為建立四邊-頂點的約束推導3D包圍盒和構建我們的語義測量模型提供了基本條件。
與直接3D還原相比,發展完善的2D檢測和分類網路在不同的場景下具有更強的魯棒性。所提出的觀測點分類任務易於訓練,並且具有較高的精度,即使對於小的和極端遮擋物件也是如此。
基於觀測點的3D包圍盒推導
給出了通過在歸一化影象平面[Umin,vmin,UMAX,Vmax]中用四邊表示的二維包圍框和分類觀測點,我們目的是通過2D包圍框的邊和3D包圍盒頂點之間的四個約束來推斷物件的姿態,這是受到參考文獻[25]的啟發。一個3D包圍盒可以用它的中心位置p=[px,py,pz]T跟與相機幀相關的水平方向θ和先驗尺寸d=[dx,dy,dz]T來表示。例如,在圖3(b)中表示的這樣一個來自圖3(a)中的16種觀測點組合之一(表示為紅色),四個頂點投影到2D邊,相應的約束可構造為:
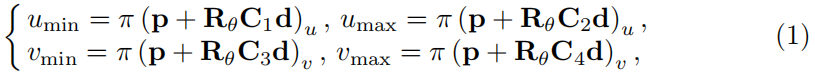
其中π是一個3D投影翹曲函式,定義為π§=[px/pz,py/pz]T,(·)u表示歸一化影象平面中的u座標。我們用Rθ表示由目標幀到相機幀的水平方向θ所表示的旋轉引數。C1:4是四個對角線選擇矩陣,用來描述物件中心與選定的四個頂點之間的關係,它們在得到分類的觀測點點後才能確定。從圖3(b)中定義的物件幀可以很容易地看出:

利用這四個方程,可以直觀地求解四自由度物體的姿態,並給出先驗尺寸。與對所有有效的邊緣頂點配置進行徹底測試的參考文獻[25]形成鮮明對比,這個求解過程的時間非常短。
我們將複雜的三維目標檢測問題轉化為二維檢測問題,觀測點分類,和直接封閉形式的計算。不可否認,求解的姿態是一種近似估計,它取決於2D包圍框的例項“緊性”和物件的先驗尺寸。同樣對於一些頂檢視的情況,3D包圍盒的重投影並不完全適合2D包圍框,這可以從圖3(b)的頂部邊緣觀察到。然而,對於自動駕駛場景中幾乎平行或俯視的視點來說,這個假設是合理的。需要注意我們的例項位姿推斷僅用於生成物件投影輪廓和遮擋標記用於特徵提取並作為最大後驗(Map)估計的初始值。其中基於滑動視窗的特徵相關和目標點雲對齊將進一步優化3D目標軌跡。
5特徵提取與匹配
我們將推匯出的3D物件包圍盒 投影到立體影象上來生成一個有效的輪廓。如圖2(b)所示,我們使用不同的顏色標記來表示每個物件的可見部分(灰色背景)。對於遮擋物件,我們根據物體的2D重疊和3D深度關係,將被遮擋部分標記為不可見。對於小於四個有效邊緣的截斷物件,不能通過Sec.
4.2中的方法來推斷,我們直接將左側影象中檢測到的2D包圍框投影到右側影象。我們在可見區域內為每個物件和背景同時提取左、右影象的ORB特徵。
立體匹配通過極線搜尋來實現。物件特徵的深度範圍是從推斷的物件姿態中知道的,所以我們將搜尋區域限制在一個較小的範圍內,以實現魯棒的特徵匹配。對於時間匹配,我們首先通過2D包圍框相似性評分投票將連續幀中的物件關聯起來。在對攝像機旋轉進行修正後,根據連續影象之間二維包圍框的中心距離和形狀相似度對相似度進行加權。如果該物件與前一幀中的所有物件的最大相似度分數小於一個閾值,則該物件被視為丟失。我們注意到有一些更復雜的關聯方案,例如參考文獻[9]中的概率資料關聯,但是它相比於高度動態和無重複的自動駕駛場景,更適合於靜態物件場景避免在重新訪問時的決策困難。緊接著我們將相關物件和背景的ORB特性與上一幀匹配。極端值通過RANSAC和對每個目標和背景分別進行區域性基本矩陣測試捨去。
6 自身運動和物件跟蹤
從符號定義開始,我們用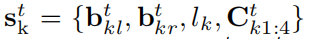 表示在時間t時第k個物件的語義測量,
表示在時間t時第k個物件的語義測量,
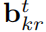
是2D包圍框的左上角和右下座標的測量值,
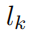
是物件的類別標籤
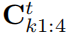
是在Sec. 4.2中定義的四個選擇矩陣。對於固定在一個物體或背景上的稀疏特徵的測量,我們使用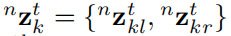
表示在第k個物件上t時間處的第n次特徵的立體觀測值(K=0表示靜態背景),
分別是在歸一化左右影象平面上的特徵座標。相機和第k個物體的狀態分別表示為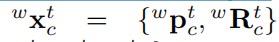
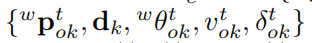
在這裡使用
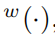
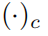
和
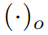
去表示世界、相機和物件幀。
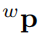
表示世界幀中的位置。對於物體方位我們只對水平旋轉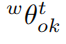 建模而不是
建模而不是
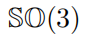
旋轉
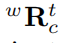
相機自身。
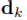
是第k個物件的時間不變尺寸
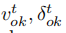
是速度和轉向角只用於車輛估計。
為一目瞭然,我們在圖4中展示在時間t的測量和狀態。
考慮一般的自動駕駛場景,我們的目標是連續估計車載相機從時間0到T
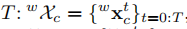
並跟蹤3D物件的
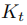 :
:
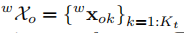

並恢復動態稀疏特徵的3D位置: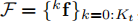
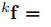
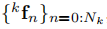
(這裡使用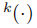
表示第k個物件幀,其中的特徵是相對靜態的,K=0表示世界背景,其中特徵是全域性靜態的)
給定語義測量值: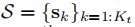
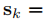
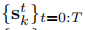
和第k個物體上的稀疏特徵觀測:
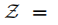
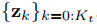
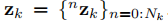
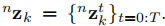
我們將語義物件和攝像機自我運動跟蹤從概率模型轉化為一個非線性優化問題。
6.1 自身運動追蹤
在靜態背景特徵觀測的情況下,可以通過最大似然估計(MLE)來求解自我運動:
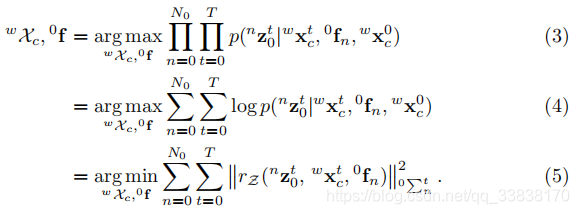
這是典型的SLAM或SfM方法。在第一狀態下有條件地估計相機姿態和背景點雲。如Eq.3所示測量殘差的對數概率與其mahalanobis範數成正比
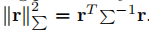
然後將MLE問題轉化為一個非線性最小二乘問題,這個過程也被稱為集束調整(BA)。
6.2 語義物體追蹤
在求解相機機位姿後,基於先驗尺寸和例項語義測量,可以求解每個時刻t的物件狀態。我們假設物體是一個剛體,這意味著其中存在的特徵是固定在物件幀上的。因此,如果有連續的物件特徵觀測,則物件的時間狀態是有關聯的。給定相機的姿態,不同物體的狀態是條件獨立的,這樣我們就可以並行和獨立地跟蹤所有的物體。對於第k個物件,我們對於每個類別標籤有尺寸先驗分佈 我們假設每個物件在每一時刻的檢測結果和特徵測量是獨立且高斯分佈的,根據貝葉斯準則,我們有以下的最大後驗(MAP)估計:
我們假設每個物件在每一時刻的檢測結果和特徵測量是獨立且高斯分佈的,根據貝葉斯準則,我們有以下的最大後驗(MAP)估計: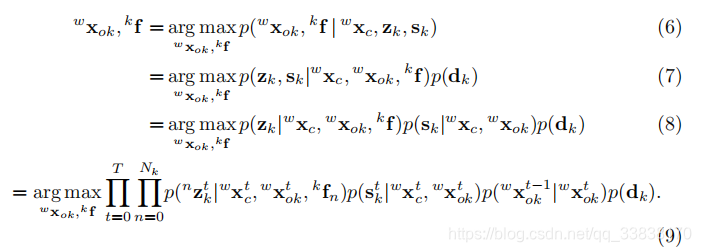
類似於Eq.3,我們將對映轉化為一個非線性優化問題: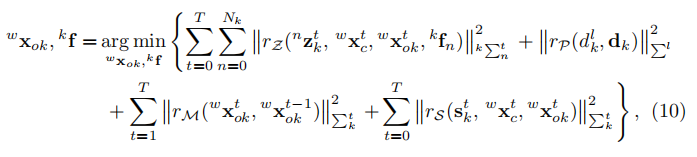
其中,我們使用rz、rp、rm和rs分別表示特徵重投影、先驗尺寸、物件運動模型和語義包圍盒重新投影的殘差。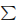 是每次測量對應的協方差矩陣。我們將3D物件追蹤問題轉化為一種動態物件BA方法,充分利用了目標的尺寸和運動的先驗性,增強了時間一致性。最大後驗估計可以通過最小化所有殘差的Mahalanobis範數之和來實現。
是每次測量對應的協方差矩陣。我們將3D物件追蹤問題轉化為一種動態物件BA方法,充分利用了目標的尺寸和運動的先驗性,增強了時間一致性。最大後驗估計可以通過最小化所有殘差的Mahalanobis範數之和來實現。
稀疏特徵觀測
我們將靜態特徵與相機位姿之間的射影幾何擴充套件為動態特徵和物件位姿。基於與目標幀相關的錨定相對靜態特徵,通過因子圖可以將具有相同特徵觀測的物體姿態聯絡起來。對於每個特徵觀測,殘差可以用預測的特徵位置的重投影誤差和左右影象上的實際特徵觀測來表示: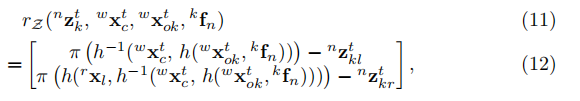 其中,我們使用h(x,p)來表示將3D剛體變換x變換到一個點p。例如
其中,我們使用h(x,p)來表示將3D剛體變換x變換到一個點p。例如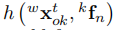 將第n個特徵點
將第n個特徵點 從物件幀轉換為世界幀,
從物件幀轉換為世界幀,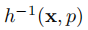 是對應的逆變換。
是對應的逆變換。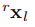 表示離線標定的立體相機的外部變換。
表示離線標定的立體相機的外部變換。
語義3D物體測量
受益於觀測點的類別,我們可以瞭解2D包圍框的邊緣與3D包圍盒的頂點之間的關係。假設2D包圍框緊貼在物體邊界上,每個邊緣與一個重新投影的3D頂點相交。這些關係可以被確定為每個2D邊的四個選擇矩陣。語義殘差可以用預測的具有檢測到的2D包圍框邊緣和3D包圍盒頂點的重投影誤差來表示: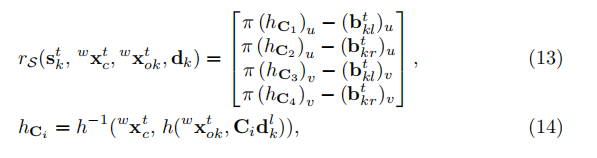
其中我們使用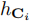 將由3D包圍盒的相應選擇矩陣
將由3D包圍盒的相應選擇矩陣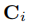 指定的頂點投影到相機平面上。這個因素立即建立了物體姿態與其尺寸之間的聯絡。注意由於實時性的要求,我們只對左邊的影象執行2D檢測。
指定的頂點投影到相機平面上。這個因素立即建立了物體姿態與其尺寸之間的聯絡。注意由於實時性的要求,我們只對左邊的影象執行2D檢測。
車輛運動模型
為了實現車輛類別的運動和方向一致性估計,我們使用參考文獻[28]中引入的運動學模型。時間t的車輛狀態可以用t−1的狀態來預測: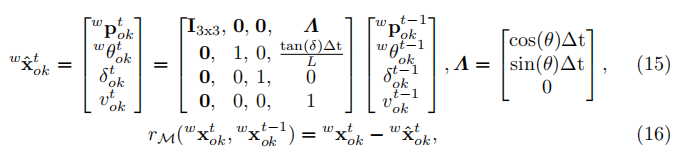
其中L是軸距的長度,它可以被尺寸引數化。車輛的的方向總是與運動方向平行的。為獲得更多內容我們請讀者閱讀參考文獻[28]。通過這種為自主駕駛和路徑規劃提供了豐富的資訊運動學模型,我們可以連續地跟蹤車輛的速度和方向。對於行人等其他類別,我們直接使用一個簡單的恆速模型來提高平滑度。
點雲對齊
在最小化所有殘差後,我們得到了基於尺寸先驗的目標位姿的最大後驗估計。然而,由於物件的尺寸不同所估計的位姿可能會存在偏差。因此我們將3D包圍盒對齊到恢復的點雲,因為精確的立體外部校準,這是沒有偏差的。我們最小化所有3D點到錨定的3D包圍盒表面的距離: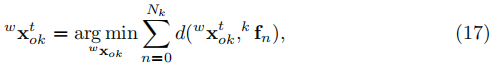
其中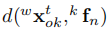 表示第k個特徵與其相應的觀測表面的距離。在將這些資訊緊密融合在一起後,我們得到了對靜態和動態目標的一致和準確的位姿估計。
表示第k個特徵與其相應的觀測表面的距離。在將這些資訊緊密融合在一起後,我們得到了對靜態和動態目標的一致和準確的位姿估計。