
《Stereo R-CNN based 3D Object Detection for Autonomous Driving》論文解讀
論文連結:https://arxiv.org/pdf/1902.09738v2.pdf
這兩個月忙著做實驗 部落格都有些荒廢了,寫篇用於3D檢測的論文解讀吧,有理解錯誤的地方,煩請有心人指正)。
部落格原作者Missouter,部落格園連結https://www.cnblogs.com/missouter/,歡迎交流。
【Abstract】
該論文提出了一種結合影象中語義、幾何學與稀疏、稠密資訊的3D目標檢測演算法。
該演算法用Faster R-CNN接收作為立體輸入的左右影象,同時檢測、聯絡兩幅影象中的物體;在立體檢測網路的RPN後,論文添加了一個用於檢測稀疏關鍵點(key points)、視點(viewpoints)與物體尺寸的網路結構,與左右兩圖的2D檢測框一併作為輸入,計算出對應的3D檢測框,(個人覺得這個新新增的網路結構是這篇論文的一大亮點?)也許是因為這個結構,較其他3D檢測演算法而言這個方法並不需要深度輸入。
但單用這種結構算出的3D檢測框精度不夠,所以論文利用左右影象的ROI實現了基於區域的光度校準,從而提升3D框的精度。
【Introduction】
論文提出了一種使用雙目立體相機的3D檢測演算法,與鐳射定位(LiDAR)相比,立體相機具有成本低、具備更大更遠的識別範圍的優勢。

論文提出的網路結構如上圖所示,主要分為3個部分:
1、 以雙目圖片作為輸入的立體檢測RPN。
2、 經過ROI校準後用於得到key points、view points與物體尺寸的網路分支,承接該網路輸出作為約束條件的3D檢測框估值網路。
3、 保證3D檢測框效能與精度的基於高密度區域的光度對準方法(Dense 3D Box Alignment),位於網路的最後。
筆者感興趣的地方在第二部分。
【Stereo R-CNN Network】
Stereo R-CNN使用權值共享的ResNet與FPN作為主幹,提取左右兩圖的一致特徵。
1、 Stereo RPN
與普通的RPN不同的是,stereo r-cnn的RPN接受的是左右兩圖各尺度上連線的feature map;左右影象真實地面框的並集被作為物件分類的目標,iou高於0.7的目標將被歸為正樣本,低於0.3的將被定義為負樣本,錨框能夠囊括左右兩圖的興趣區域得益於此;
針對錨框的偏移計算,文章給出了六種迴歸形式:[∆u, ∆w, ∆u‘, ∆w’, ∆v, ∆h],u,v分別代表二位檢測框的水平、垂直中心座標,w、h分別代表檢測框的寬和高,由於使用已矯正過的立體影象,故對於兩圖的v、h同一變數進行迴歸。綜上,與傳統的RPN不同,stereo r-cnn的輸出通道有6個。在輸出候選區域時論文同樣使用nms降重。
2、 Stereo R-CNN
a). Stereo Regression
經RPN得到左右影象的建議區域對後,網路分別對左右兩圖的feature map應用ROI排列,得到的兩圖ROI特徵被放入兩個連續的全連線層中提取語義資訊。四個子分支被用於物體分類、檢測框、尺寸和view points角度的預測;檢測框的迴歸形式與RPN類似。
對於不同朝向的物體,view points角度是不同的:論文以 代表物體朝向與相機朝向的夾角,以 代表物體-相機連線與相機朝向的夾角,需進行迴歸的view points角度α可被定義為α=θ+β,為了避免不連續性,子分支中的訓練目標為[sinα, cosα]。
根據二維框、物體尺寸,深度資訊可被直觀地恢復;通過解耦view points角度與三維位置的關係,物體朝向也可以被解出來。
一個左/右ROI與左/右真實框的IoU高於0.5的左右ROI對,將會作為前景,而左右任一ROI與真實框的IoU處於0.1~0.5的將會作為背景;前景ROI對的左/右ROI與左右真實框將會用於偏移的迴歸計算;與RPN相同,垂直方向的值仍是左右兩圖共用的。
對於尺寸預測,論文僅用預先設定的尺寸來回歸地面真實尺寸,獲取偏移量。
b). Keypoint Prediction
除了檢測框和view points角度外,在檢測框中部投影的3D角可以為3D檢測框估計提供更嚴格的約束條件。論文定義了4個表示轉角的3D檢測框底部的4個關鍵點。下圖中標為Boundary key points。

透視關鍵點是唯一一個可以明顯地投射到框的中間(而不是左或右邊緣) 的3D語義關鍵點。(從後文看就是後2個邊界點之間的後輪);除此之外還有兩個Boundary key points被定義,作為規則物體的替代表示(圖中前輪),只有在這兩點以內的區域可以被認定為處於物體內部,且可用於後續的dense alignment。
關鍵點的預測使用了Mask R-CNN。只有左影象的14*14 feature map被用於key points的預測。左影象經RoI排列的feature map被輸入6個連續的256通道,3*3卷積層,每個卷積層後接啟用層。一個2*2的非卷積層被用於補強輸出尺寸至28*28。這裡文章特別提到,關鍵點的座標中只有u座標提供了2D檢測框之外的額外資訊。論文對6×28×28輸出中的高度(h?)通道求和,得到6×28預測:前四個通道表示四個語義關鍵點投射到相應u位置的概率,另外兩個通道分別表示每個u位於左右邊界的概率。因前文定義的透視關鍵點只有一個,softmax被用於4*28的輸出中,求一個獨特的被投射至單個位置的語義關鍵點,這個設計避免了關鍵點型別的混亂。對於左右的邊界關健點,softmax被分別用於兩個1*28的輸出上。
簡單來說,需要被迴歸求出的關鍵點只有1個透視關鍵點,2個用於規則物體替代的邊界關鍵點,其他點都是2D檢測框有的(這裡的解讀存疑)。
【3D Box Estimation】
之前求得的關鍵點、view points角度與2D檢測框被用於3D檢測框的粗略估計。一個3D檢測框可被表示為{x, y, z, θ},分別表達檢測框的中心座標與物體的水平朝向角。根據尺寸、關鍵點和2D框,3D框可以通過減小2D框與關鍵點的二次投影誤差得到。
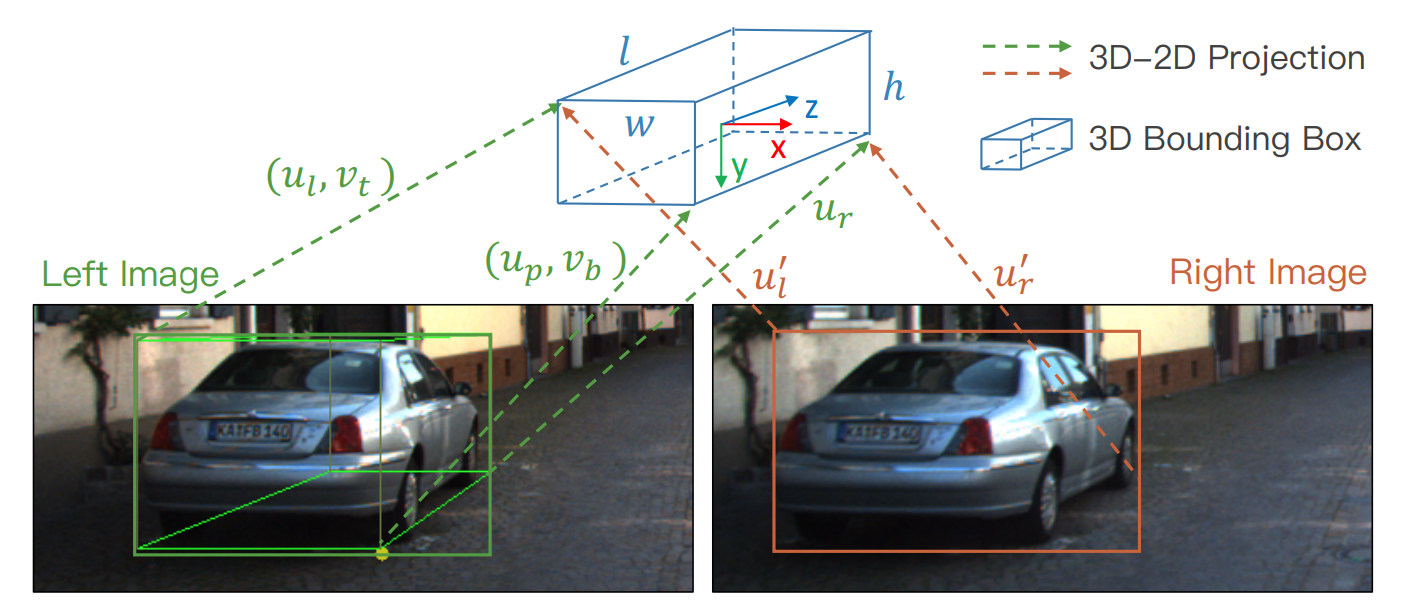
如上圖,7個測量值從2D檢測框與透視關鍵點中被提取,z = {ul, vt, ur, vb, ul', ur', up},分別代表左2D檢測框的左邊界橫座標、底部縱座標、右邊界橫座標、頂部縱座標、右檢測框的左、右邊界橫座標與關鍵點的橫座標,原文稱“Given the perspective key point, the correspondences between 3D box corners and 2D box edges can be inferred”。論文使用7個對應測定量的投影變換公式對{x, y, z, θ}進行求解。原文“There are total seven equations corresponding to seven measurements, where the sign of {w/2, l/2} should be changed appropriately based on the corresponding 3D box corner.”中提到{ , }的適當調整讀起來有些…曖昧?
對於觀察不到車輛的2個面(車屁股正對?)的情況,up、物體尺寸無從得知,文章給出基於view point的補充公式:

α、β含義與前文相同。
Dense 3D Box Alignment部分不在博主研究範圍內,博主決定摸了。
&n