
分散式日誌收集系統:Flume


Flume知識點:
Event 是一行一行的資料
1.flume是分散式的日誌收集系統,把收集來的資料傳送到目的地去。
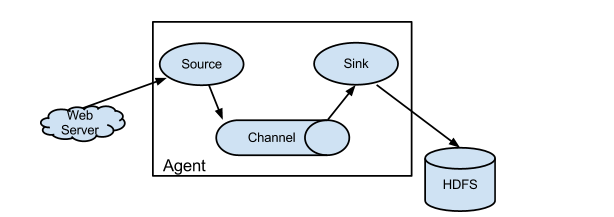
2.flume裡面有個核心概念,叫做agent。agent是一個java程序,執行在日誌收集節點。
3.agent裡面包含3個核心元件:source、channel、sink。
3.1 source元件是專用於收集日誌的,可以處理各種型別各種格式的日誌資料,包括avro、thrift、exec、jms、spooling directory、netcat、sequence generator、syslog、http、legacy、自定義。
source元件把資料收集來以後,臨時存放在channel中。
3.2 channel元件是在agent中專用於臨時儲存資料的,可以存放在memory、jdbc、file、自定義。
channel中的資料只有在sink傳送成功之後才會被刪除。
3.3 sink元件是用於把資料傳送到目的地的元件,目的地包括hdfs、logger、avro、thrift、ipc、file、null、hbase、solr、自定義。
4.在整個資料傳輸過程中,流動的是event。事務保證是在event級別。
5.flume可以支援多級flume的agent,支援扇入(fan-in)、扇出(fan-out)。
扇入指的是:source 可以接收多個輸入
扇出指的是:sink可以輸出多個目的地
Flume安裝:
1.分別解壓這兩個檔案在節點裡:

2.把src內容 複製到bin下:
cp -ri apache-flume-1.4.0-src/* apache-flume-1.4.0-bin/
3.src沒用可以刪掉了:
rm -rf apache-flume-1.4.0-src
4.重新命名apache-flume-1.4.0-bin 為flume:
mv apache-flume-1.4.0-bin/ flume
注意:flume安裝的 前提是你已經安裝了hadoop ,因為它要用到hadoop的jar
5 . 書寫配置檔案example
agent1表示代理名稱:
agent1.sources=source1
agent1.sinks=sink1
agent1.channels=channel1
Spooling Directory是監控指定資料夾中新檔案的變化,一旦新檔案出現,就解析該檔案內容,然後寫入到channle。寫入完成後,標記該檔案已完成或者刪除該檔案。
配置source1
agent1.sources.source1.type=spooldir
agent1.sources.source1.spoolDir=/root/hmbbs
agent1.sources.source1.channels=channel1
agent1.sources.source1.fileHeader = false
agent1.sources.source1.interceptors = i1
agent1.sources.source1.interceptors.i1.type = timestamp
配置sink1
agent1.sinks.sink1.type=hdfs
agent1.sinks.sink1.hdfs.path=hdfs://hadoop0:9000/hmbbs
agent1.sinks.sink1.hdfs.fileType=DataStream
agent1.sinks.sink1.hdfs.writeFormat=TEXT
agent1.sinks.sink1.hdfs.rollInterval=1 //指定時間檔案被關閉
agent1.sinks.sink1.channel=channel1
agent1.sinks.sink1.hdfs.filePrefix=%Y-%m-%d //生成檔案的字首
配置channel1
agent1.channels.channel1.type=file
//備份目錄
agent1.channels.channel1.checkpointDir=/root/hmbbs_tmp/123
agent1.channels.channel1.dataDirs=/root/hmbbs_tmp/
把該檔案寫入flume 的conf資料夾下,並命名為example
6.在root目錄下建立資料夾hmbbs
[[email protected] /]# cd /root
[[email protected] ~]# ls
anaconda-ks.cfg Documents install.log Music Public Videos
Desktop Downloads install.log.syslog Pictures Templates
[[email protected] ~]# mkdir hmbbs
7.在hadoop下建立資料夾
hadoop fs -mkdir /hmbbs
8.執行flume
進入flume執行命令
bin/flume-ng agent -n agent1 -c conf -f conf/example -Dflume.root.logger=DEBUG,console
9.建立
[[email protected] ~]# vi hello
[[email protected] ~]# cp hello hmbbs
在hdfs裡會看到檔案傳輸了進去
10 .
[[email protected] ~]# cd hmbbs
[[email protected] hmbbs]# ls
hello.COMPLETED
紅色部分表示任務完成,已經傳輸到channel中,字尾.COMPLETED是重新命名後的結果。
[[email protected] ~]# cd hmbbs_tmp
[[email protected] hmbbs_tmp]# ls
hmbbs_tmp表示的是channel使用的目錄。
[[email protected] hmbbs_tmp]# cd 123
[[email protected] 123]# ls
checkpoint checkpoint.meta inflightputs inflighttakes
這裡的資料是備份資料,如果datadir裡資料丟失可以從這裡恢復。
相關推薦
分散式日誌收集系統:Flume
Flume知識點: Event 是一行一行的資料 1.flume是分散式的日誌收集系統,把收集來的資料傳送到目的地去。 2.flume裡面有個核心概念,叫做agent。agent是一個java程序,執行在日誌收集節點。 3.agent裡面包
Alex 的 Hadoop 菜鳥教程: 第22課 分散式日誌收集元件:flume
本教程的目的:flume 跟 hadoop 有什麼關係介紹flume的結構介紹flume的安裝做一個簡單的收集網路傳送過來的文字(NetCat Source)並儲存到日誌檔案(Logger Sink)的例子flume 跟 hadoop 有什麼關係hadoop是一個分散式系統,
分散式日誌收集系統: Facebook Scribe
1.分散式日誌收集系統:背景介紹 許多公司的平臺每天會產生大量的日誌(一般為流式資料,如,搜尋引擎的pv,查詢等),處理這些日誌需要特定的日誌系統,一般而言,這些系統需要具有以下特徵: (1) 構建應用系統和分析系統的橋樑,並將它們之間的關聯解耦; (2) 支援近實時的線上分析系統和類似於Hadoo
分散式日誌收集系統 —— Flume
一、Flume簡介 Apache Flume 是一個分散式,高可用的資料收集系統。它可以從不同的資料來源收集資料,經過聚合後傳送到儲存系統中,通常用於日誌資料的收集。Flume 分為 NG 和 OG (1.0 之前) 兩個版本,NG 在 OG 的基礎上進行了完全的重構,是目前使用最為廣泛的版本。下面的介紹均以
Linux搭建ELK日誌收集系統:FIlebeat+Redis+Logstash+Elasticse
uri 對數 exp 取數 網速 docker useradd 通過 演示 Centos7部署ELK日誌收集系統 一、ELK概述: ELK是一組開源軟件的簡稱,其包括Elasticsearch、Logstash 和 Kibana。ELK最近幾年發展迅速,已經成為目前最流行的
改造apache的開源日誌專案來實現 分散式日誌收集系統
概述: 在分散式系統中,經常需要採集各個節點的日誌,然後統一分析。 本文提供一種簡單的方案,本文采用開源日誌專案 + 統一資料庫結構的方式,在各個開發環境中,提供統一的配置及呼叫方法,所有的日誌均記錄在日誌伺服器中,可以追蹤查詢任意一個系統節點上任意應用的任意執行緒的執行
Flume日誌收集系統架構詳解--轉
with 指定 mwl 裏程碑 工程 生命 數據接收 dba -i 2017-09-06 朱潔 大數據和雲計算技術 任何一個生產系統在運行過程中都會產生大量的日誌,日誌往往隱藏了很多有價值的信息。在沒有分析方法之前,這些日誌存儲一段時間後就會被清理。隨著技術的發展和
日誌收集系統Flume及其應用
註意 內存緩存 外部 ner 流動 場景 啟動 net conf Apache Flume概述 Flume 是 Cloudera 提供的一個高可用的,高可靠的,分布式的海量日誌采集、聚合和傳輸的系統。Flume 支持定制各類數據發送方,用於收集各類型數據;同時,Flu
Flume可分布式日誌收集系統
agen debug 程序 負責 and 序列化 得到 集群 ava Flume 1. 前言 flume是由cloudera軟件公司產出的可分布式日誌收集系統,後與2009年被捐贈了apache軟件基金會,為hadoop相關組件之一。尤其近幾年隨著flume的不斷被完善
分散式日誌收集框架flume實戰
實戰一:從指定網路埠採集資料輸出到控制檯 flume框架架構 Source:指定資料來源,有NetCat TCP(專案用到),kafka,JMS,Avro,Syslog等等 Channel:資料管道,有Kafka,Memory,File等等 Sink:日誌資料存放,有Avro,HBa
大資料技術學習筆記之網站流量日誌分析專案:Flume日誌採集系統1
一、網站日誌流量專案 -》專案開發階段: -》可行性分析 -》需求分析
分散式日誌收集框架Flume
文章目錄 Flume概述 Flume架構及核心元件 Flume&JDK環境部署 Flume實戰案例一 Flume實戰案例二 Flume實戰案例三(重點掌握) 業務現狀:公司有Hadoop
分散式日誌收集框架Flume環境部署
最近在做一個基於Spark Streaming的實時流處理專案,之間用到了Flume來收集日誌資訊,所以在這裡總結一下Flume的用法及原理. Flume是一個分散式、高可靠、高可用、負載均衡的進行大量
基於flume的日誌收集系統配置
大資料系統中通常需要採集的日誌有: 系統訪問日誌 使用者點選日誌 其他業務日誌(比如推薦系統的點選日誌) 在收集日誌的時候,一般分為三層結構:採集層、彙總層和儲存層,而不是直接從採集端將資料傳送到儲存端,這樣的好處有: 如果儲存端如Hadoop叢集、Kafka等需要停
Flume(日誌收集系統)簡介
一、Flume簡介 flume是一個分散式、可靠、高可用的海量日誌採集、聚合和傳輸的系統。支援在日誌系統中定製各類資料傳送方,用於收集資料 ; 同時,Flume提供對資料進行簡單處理,並寫到各種資料接受方(比如文字、HDFS、Hbase等)的能力 。 flume的
大資料學習筆記之flume----日誌收集系統
一、flume基本概念 Flume是Cloudera提供的一個高可用的,高可靠的,分散式的海量日誌採集、聚合和傳輸的系統; Flume支援在日誌系統中定製各類資料傳送方,用於收集資料; Flume提供對資料進行簡單處理,並寫到各種資料接受方(可定製)的能力。 總結:f
基於flume+kafka+storm日誌收集系統搭建
基於flume+kafka+storm日誌收集系統搭建 1. 環境 192.168.0.2 hadoop1 192.168.0.3 hadoop2 192.168.0.4 hadoop3 已經
分散式日誌收集框架Flume:從指定網埠採集資料輸出到控制檯
A)配置Source B)配置Channel C)配置Sink D)把以上三個元件串起來 變數: a1:agent名稱r1:source的名稱k1:sink的名稱c1:channel的名稱 #以下為配
基於Flume的美團日誌收集系統(二)改進和優化
問題導讀: 1.Flume的存在些什麼問題? 2.基於開源的Flume美團增加了哪些功能? 3.Flume系統如何調優? 在《基於Flume的美團日誌收集系統(一)架構和設計》中,我們詳述了基於Flume的美團日誌收集系統的架構設計,以及為什麼做這樣的設計。在本節
flume分散式日誌採集系統實戰-陳耀武-專題視訊課程
flume分散式日誌採集系統實戰—4303人已學習 課程介紹 隨著公司業務的不斷增長,劃分了許多應用,不同應用的日誌在不同伺服器上面,很難進行統一管理,通過學習該課程,你可以自己搭建日誌採集系統,可以進行資料分析,挖掘等工作課程收益 通過學習該課程,可以快