
基於Flume的美團日誌收集系統(二)改進和優化
在《基於Flume的美團日誌收集系統(一)架構和設計》中,我們詳述了基於Flume的美團日誌收集系統的架構設計,以及為什麼做這樣的設計。在本節中,我們將會講述在實際部署和使用過程中遇到的問題,對Flume的功能改進和對系統做的優化。 1 Flume的問題總結 在Flume的使用過程中,遇到的主要問題如下: a. Channel“水土不服”:使用固定大小的MemoryChannel在日誌高峰時常報佇列大小不夠的異常;使用FileChannel又導致IO繁忙的問題; b. HdfsSink的效能問題:使用HdfsSink向Hdfs寫日誌,在高峰時間速度較慢; c. 系統的管理問題:配置升級,模組重啟等; 2 Flume的功能改進和優化點
- Source : 接收的event數和處理的event數
- Channel : Channel中擁堵的event數
-
Sink : 已經處理的event數
-
/**
-
* Rename bucketPath file from .tmp to permanent location.
-
*/
-
private void renameBucket() throws IOException, InterruptedException {
-
if(bucketPath.equals(targetPath)) {
-
return;
-
}
-
final Path srcPath = new Path(bucketPath);
-
final Path dstPath = new Path(targetPath);
-
callWithTimeout(new CallRunner<Object>() {
-
@Override
-
public Object call() throws Exception {
-
if(fileSystem.exists(srcPath)) { // could block
-
LOG.info("Renaming " + srcPath + " to " + dstPath);
-
fileSystem.rename(srcPath, dstPath); // could block
-
//index the dstPath lzo file
-
if (codeC != null && ".lzo".equals(codeC.getDefaultExtension()) ) {
-
LzoIndexer lzoIndexer = new LzoIndexer(new Configuration());
-
lzoIndexer.index(dstPath);
-
}
-
}
-
return null;
-
}
-
});
- }
2.3 增加HdfsSink的開關 我們在HdfsSink和DualChannel中增加開關,當開關開啟的情況下,HdfsSink不再往Hdfs上寫資料,並且資料只寫向DualChannel中的FileChannel。以此策略來防止Hdfs的正常停機維護。 2.4 增加DualChannel Flume本身提供了MemoryChannel和FileChannel。MemoryChannel處理速度快,但快取大小有限,且沒有持久化;FileChannel則剛好相反。我們希望利用兩者的優勢,在Sink處理速度夠快,Channel沒有快取過多日誌的時候,就使用MemoryChannel,當Sink處理速度跟不上,又需要Channel能夠快取下應用端傳送過來的日誌時,就使用FileChannel,由此我們開發了DualChannel,能夠智慧的在兩個Channel之間切換。 其具體的邏輯如下:
-
/***
-
* putToMemChannel indicate put event to memChannel or fileChannel
-
* takeFromMemChannel indicate take event from memChannel or fileChannel
-
* */
-
private AtomicBoolean putToMemChannel = new AtomicBoolean(true);
-
private AtomicBoolean takeFromMemChannel = new AtomicBoolean(true);
-
void doPut(Event event) {
-
if (switchon && putToMemChannel.get()) {
-
//往memChannel中寫資料
-
memTransaction.put(event);
-
if ( memChannel.isFull() || fileChannel.getQueueSize() > 100) {
-
putToMemChannel.set(false);
-
}
-
} else {
-
//往fileChannel中寫資料
-
fileTransaction.put(event);
-
}
-
}
-
Event doTake() {
-
Event event = null;
-
if ( takeFromMemChannel.get() ) {
-
//從memChannel中取資料
-
event = memTransaction.take();
-
if (event == null) {
-
takeFromMemChannel.set(false);
-
}
-
} else {
-
//從fileChannel中取資料
-
event = fileTransaction.take();
-
if (event == null) {
-
takeFromMemChannel.set(true);
-
putToMemChannel.set(true);
-
}
-
}
-
return event;
- }
2.5 增加NullChannel Flume提供了NullSink,可以把不需要的日誌通過NullSink直接丟棄,不進行儲存。然而,Source需要先將events存放到Channel中,NullSink再將events取出扔掉。為了提升效能,我們把這一步移到了Channel裡面做,所以開發了NullChannel。 2.6 增加KafkaSink 為支援向Storm提供實時資料流,我們增加了KafkaSink用來向Kafka寫實時資料流。其基本的邏輯如下:
-
public class KafkaSink extends AbstractSink implements Configurable {
-
private String zkConnect;
-
private Integer zkTimeout;
-
private Integer batchSize;
-
private Integer queueSize;
-
private String serializerClass;
-
private String producerType;
-
private String topicPrefix;
-
private Producer<String, String> producer;
-
public void configure(Context context) {
-
//讀取配置,並檢查配置
-
}
-
@Override
-
public synchronized void start() {
-
//初始化producer
-
}
-
@Override
-
public synchronized void stop() {
-
//關閉producer
-
}
-
@Override
-
public Status process() throws EventDeliveryException {
-
Status status = Status.READY;
-
Channel channel = getChannel();
-
Transaction tx = channel.getTransaction();
-
try {
-
tx.begin();
-
//將日誌按category分佇列存放
-
Map<String, List<String>> topic2EventList = new HashMap<String, List<String>>();
-
//從channel中取batchSize大小的日誌,從header中獲取category,生成topic,並存放於上述的Map中;
-
//將Map中的資料通過producer傳送給kafka
-
tx.commit();
-
} catch (Exception e) {
-
tx.rollback();
-
throw new EventDeliveryException(e);
-
} finally {
-
tx.close();
-
}
-
return status;
-
}
- }
2.7 修復和scribe的相容問題 Scribed在通過ScribeSource傳送資料包給Flume時,大於4096位元組的包,會先發送一個Dummy包檢查伺服器的反應,而Flume的ScribeSource對於logentry.size()=0的包返回TRY_LATER,此時Scribed就認為出錯,斷開連線。這樣迴圈反覆嘗試,無法真正傳送資料。現在在ScribeSource的Thrift介面中,對size為0的情況返回OK,保證後續正常傳送資料。 3. Flume系統調優經驗總結3.1 基礎引數調優經驗
-
HdfsSink中預設的serializer會每寫一行在行尾新增一個換行符,我們日誌本身帶有換行符,這樣會導致每條日誌後面多一個空行,修改配置不要自動新增換行符;
- lc.sinks.sink_hdfs.serializer.appendNewline = false
-
調大MemoryChannel的capacity,儘量利用MemoryChannel快速的處理能力;
- 調大HdfsSink的batchSize,增加吞吐量,減少hdfs的flush次數;
-
適當調大HdfsSink的callTimeout,避免不必要的超時錯誤;
- lc.sinks.sink_hdfs.hdfs.path = /user/hive/work/orglog.db/%{category}/dt=%Y%m%d/hour=%H
HdfsS ink中處理每條event時,都要根據配置獲取此event應該寫入的Hdfs path和filename,預設的獲取方法是通過正則表示式替換配置中的變數,獲取真實的path和filename。因為此過程是每條event都要做的操作,耗時很長。通過我們的測試,20萬條日誌,這個操作要耗時6-8s左右。 由於我們目前的path和filename有固定的模式,可以通過字串拼接獲得。而後者比正則匹配快幾十倍。拼接定符串的方式,20萬條日誌的操作只需要幾百毫秒。 3.3 HdfsSink的b/m/s優化 在我們初始的設計中,所有的日誌都通過一個Channel和一個HdfsSink寫到Hdfs上。我們來看一看這樣做有什麼問題。 首先,我們來看一下HdfsSink在傳送資料的邏輯:
-
//從Channel中取batchSize大小的events
-
for (txnEventCount = 0; txnEventCount < batchSize; txnEventCount++) {
-
//對每條日誌根據category append到相應的bucketWriter上;
-
bucketWriter.append(event);
-
}
-
for (BucketWriter bucketWriter : writers) {
-
//然後對每一個bucketWriter呼叫相應的flush方法將資料flush到Hdfs上
-
bucketWriter.flush();
- }
假設我們的系統中有100個category,batchSize大小設定為20萬。則每20萬條資料,就需要對100個檔案進行append或者flush操作。 其次,對於我們的日誌來說,基本符合80/20原則。即20%的category產生了系統80%的日誌量。這樣對大部分日誌來說,每20萬條可能只包含幾條日誌,也需要往Hdfs上flush一次。 上述的情況會導致HdfsSink寫Hdfs的效率極差。下圖是單Channel的情況下每小時的傳送量和寫hdfs的時間趨勢圖。

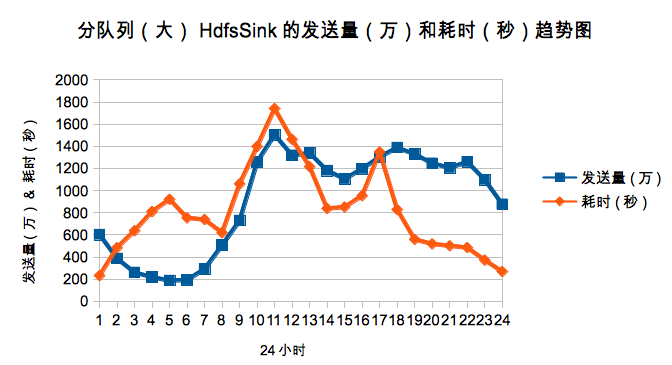
鑑於這種實際應用場景,我們把日誌進行了大小歸類,分為big, middle和small三類,這樣可以有效的避免小日誌跟著大日誌一起頻繁的flush,提升效果明顯。下圖是分佇列後big佇列的每小時的傳送量和寫hdfs的時間趨勢圖。
相關推薦
基於Flume的美團日誌收集系統(二)改進和優化
問題導讀: 1.Flume的存在些什麼問題? 2.基於開源的Flume美團增加了哪些功能? 3.Flume系統如何調優? 在《基於Flume的美團日誌收集系統(一)架構和設計》中,我們詳述了基於Flume的美團日誌收集系統的架構設計,以及為什麼做這樣的設計。在本節
基於Flume的美團日誌收集系統(一)架構和設計
美團的日誌收集系統負責美團的所有業務日誌的收集,並分別給Hadoop平臺提供離線資料和Storm平臺提供實時資料流。美團的日誌收集系統基於Flume設計和搭建而成。 《基於Flume的美團日誌收集系統》將分兩部分給讀者呈現美團日誌收集系統的架構設計和實戰經驗。 第一部
10044---基於Flume的美團日誌收集系統(一)架構和設計
原文 問題導讀: 1.Flume-NG與Scribe對比,Flume-NG的優勢在什麼地方?2.架構設計考慮需要考慮什麼問題?3.Agent宕機該如何解決?4.Collector宕機是否會有影響?5.Flume-NG可靠性(reliability)方面做了哪些措施?
COPY 基於Flume的美團日誌收集系統架構和設計
美團的日誌收集系統負責美團的所有業務日誌的收集,並分別給Hadoop平臺提供離線資料和Storm平臺提供實時資料流。美團的日誌收集系統基於Flume設計和搭建而成。 《基於Flume的美團日誌收集系統》將分兩部分給讀者呈現美團日誌收集系統的架構設計和實戰經驗。 第一部
基於flume+kafka+storm日誌收集系統搭建
基於flume+kafka+storm日誌收集系統搭建 1. 環境 192.168.0.2 hadoop1 192.168.0.3 hadoop2 192.168.0.4 hadoop3 已經
Go實現海量日誌收集系統(二)
fig encode 文件配置 sar 架構 cli 代碼執行 CP lob 一篇文章主要是關於整體架構以及用到的軟件的一些介紹,這一篇文章是對各個軟件的使用介紹,當然這裏主要是關於架構中我們agent的實現用到的內容 關於zookeeper+kafka 我們需要先把兩
基於flume的日誌收集系統配置
大資料系統中通常需要採集的日誌有: 系統訪問日誌 使用者點選日誌 其他業務日誌(比如推薦系統的點選日誌) 在收集日誌的時候,一般分為三層結構:採集層、彙總層和儲存層,而不是直接從採集端將資料傳送到儲存端,這樣的好處有: 如果儲存端如Hadoop叢集、Kafka等需要停
Flume日誌收集系統架構詳解--轉
with 指定 mwl 裏程碑 工程 生命 數據接收 dba -i 2017-09-06 朱潔 大數據和雲計算技術 任何一個生產系統在運行過程中都會產生大量的日誌,日誌往往隱藏了很多有價值的信息。在沒有分析方法之前,這些日誌存儲一段時間後就會被清理。隨著技術的發展和
日誌收集系統Flume及其應用
註意 內存緩存 外部 ner 流動 場景 啟動 net conf Apache Flume概述 Flume 是 Cloudera 提供的一個高可用的,高可靠的,分布式的海量日誌采集、聚合和傳輸的系統。Flume 支持定制各類數據發送方,用於收集各類型數據;同時,Flu
Flume可分布式日誌收集系統
agen debug 程序 負責 and 序列化 得到 集群 ava Flume 1. 前言 flume是由cloudera軟件公司產出的可分布式日誌收集系統,後與2009年被捐贈了apache軟件基金會,為hadoop相關組件之一。尤其近幾年隨著flume的不斷被完善
Flume(日誌收集系統)簡介
一、Flume簡介 flume是一個分散式、可靠、高可用的海量日誌採集、聚合和傳輸的系統。支援在日誌系統中定製各類資料傳送方,用於收集資料 ; 同時,Flume提供對資料進行簡單處理,並寫到各種資料接受方(比如文字、HDFS、Hbase等)的能力 。 flume的
大資料學習筆記之flume----日誌收集系統
一、flume基本概念 Flume是Cloudera提供的一個高可用的,高可靠的,分散式的海量日誌採集、聚合和傳輸的系統; Flume支援在日誌系統中定製各類資料傳送方,用於收集資料; Flume提供對資料進行簡單處理,並寫到各種資料接受方(可定製)的能力。 總結:f
nginx+flume+hdfs搭建實時日誌收集系統
1、配置nginx.conf,新增以下配置 http { #配置日誌格式 log_format lf '$remote_addr^A$msec^A$http_host^A$reques
分散式日誌收集系統:Flume
Flume知識點: Event 是一行一行的資料 1.flume是分散式的日誌收集系統,把收集來的資料傳送到目的地去。 2.flume裡面有個核心概念,叫做agent。agent是一個java程序,執行在日誌收集節點。 3.agent裡面包
基於ELK的日誌收集系統的心得
elasticsearch+logstash+kinana搭建的日誌收集系統 elasticsearch是基於倒排序查詢的查詢引擎,什麼叫倒排序?比如mysql建立的索引是正排序,對於規範化資料(比如表格,元資料)而言基本使用正排序索引,倒排序一般用於文字之類的查詢,典型
分散式日誌收集系統 —— Flume
一、Flume簡介 Apache Flume 是一個分散式,高可用的資料收集系統。它可以從不同的資料來源收集資料,經過聚合後傳送到儲存系統中,通常用於日誌資料的收集。Flume 分為 NG 和 OG (1.0 之前) 兩個版本,NG 在 OG 的基礎上進行了完全的重構,是目前使用最為廣泛的版本。下面的介紹均以
Linux 之rsyslog+LogAnalyzer 日誌收集系統
windows 服務器 應用程序 數據庫 規劃圖 一、LogAnalyzer介紹 LogAnalyzer工具提供了一個易於使用,功能強大的前端,用於搜索,查看和分析網絡活動數據,包括系統日誌,事件日誌和其他許多日誌源。由於它只是將數據展示到我們用戶的面前,所以數據本身需要由另一個程序收集
es redis logstash 日誌收集系統排錯
bsp pos keys allow light 通過命令 bash 系統排錯 man 用logstash收集日誌並發送到redis,然後通過logstash取redis數據寫入到es集群,最近kibana顯示日誌總是中斷,日誌收集不過來,客戶端重啟發現報錯: Faile
Linux搭建ELK日誌收集系統:FIlebeat+Redis+Logstash+Elasticse
uri 對數 exp 取數 網速 docker useradd 通過 演示 Centos7部署ELK日誌收集系統 一、ELK概述: ELK是一組開源軟件的簡稱,其包括Elasticsearch、Logstash 和 Kibana。ELK最近幾年發展迅速,已經成為目前最流行的
Kafka+Zookeeper+Filebeat+ELK 搭建日誌收集系統
could not arch success div 名稱 fill pil ice oca ELK ELK目前主流的一種日誌系統,過多的就不多介紹了 Filebeat收集日誌,將收集的日誌輸出到kafka,避免網絡問題丟失信息 kafka接收到日誌消息後直接消費到Lo