
#####tensorflow+入門筆記︱基本張量tensor理解與tensorflow執行結構 ***********######
Gokula Krishnan Santhanam認為,大部分深度學習框架都包含以下五個核心元件:
- 張量(Tensor)
- 基於張量的各種操作
- 計算圖(Computation Graph)
- 自動微分(Automatic Differentiation)工具
- BLAS、cuBLAS、cuDNN等拓展包
.
.
一、張量的理解
.
1、張量的解讀
張量是所有深度學習框架中最核心的元件,因為後續的所有運算和優化演算法都是基於張量進行的。幾何代數中定義的張量是基於向量和矩陣的推廣,通俗一點理解的話,我們可以將標量視為零階張量,向量視為一階張量,那麼矩陣就是二階張量。
舉例來說,我們可以將任意一張RGB彩色圖片表示成一個三階張量(三個維度分別是圖片的高度、寬度和色彩資料)。如下圖所示是一張普通的水果圖片,按照RGB三原色表示,其可以拆分為三張紅色、綠色和藍色的灰度圖片,如果將這種表示方法用張量的形式寫出來,就是圖中最下方的那張表格。
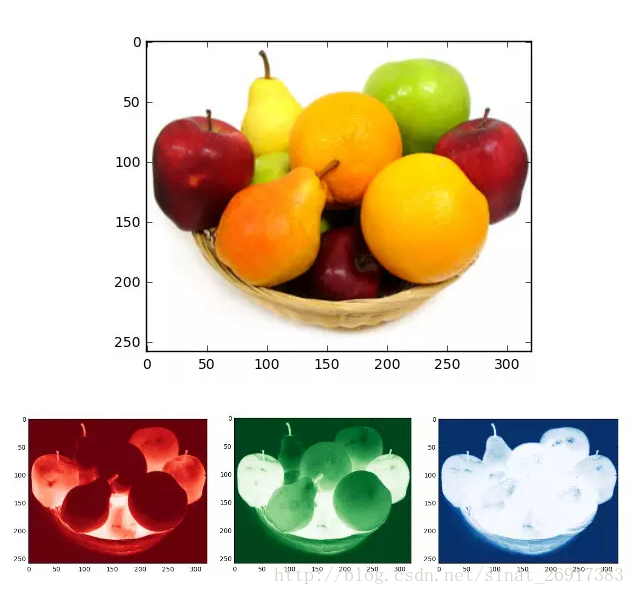
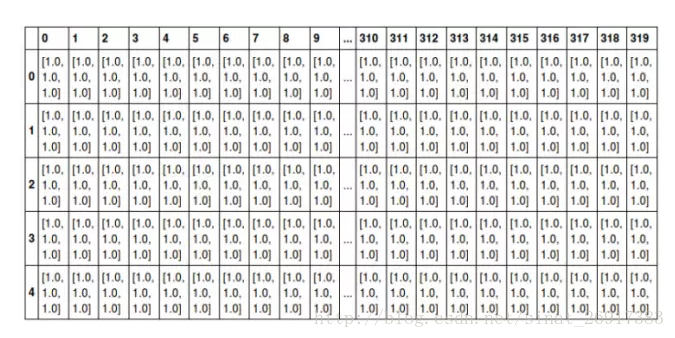
圖中只顯示了前5行、320列的資料,每個方格代表一個畫素點,其中的資料[1.0, 1.0, 1.0]即為顏色。假設用[1.0, 0, 0]表示紅色,[0, 1.0, 0]表示綠色,[0, 0, 1.0]表示藍色,那麼如圖所示,前面5行的資料則全是白色。
將這一定義進行擴充套件,我們也可以用四階張量表示一個包含多張圖片的資料集,其中的四個維度分別是:圖片在資料集中的編號,圖片高度、寬度,以及色彩資料。
為什麼需要使用張量來進行圖片處理??
當資料處理完成後,我們還可以方便地將張量再轉換回想要的格式。例如Python NumPy包中numpy.imread和numpy.imsave兩個方法,分別用來將圖片轉換成張量物件(即程式碼中的Tensor物件),和將張量再轉換成圖片儲存起來。
.
2、張量的各種操作
有了張量物件之後,下面一步就是一系列針對這一物件的數學運算和處理過程。

其實,所謂的“學習”就是不斷糾正神經網路的實際輸出結果和預期結果之間誤差的過程。這裡的一系列操作包含的範圍很寬,可以是簡單的矩陣乘法,也可以是卷積、池化和LSTM等稍複雜的運算。
.
3、計算圖(Computation Graph)
有了張量和基於張量的各種操作之後,下一步就是將各種操作整合起來,輸出我們需要的結果。
但不幸的是,隨著操作種類和數量的增多,有可能引發各種意想不到的問題,包括多個操作之間應該並行還是順次執行,如何協同各種不同的底層裝置,以及如何避免各種型別的冗餘操作等等。這些問題有可能拉低整個深度學習網路的執行效率或者引入不必要的Bug,而計算圖正是為解決這一問題產生的。
據AI科技評論瞭解,計算圖首次被引入人工智慧領域是在2009年的論文《Learning Deep Architectures for AI》。當時的圖片如下所示,作者用不同的佔位符(*,+,sin)構成操作結點,以字母x、a、b構成變數結點,再以有向線段將這些結點連線起來,組成一個表徵運算邏輯關係的清晰明瞭的“圖”型資料結構,這就是最初的計算圖。
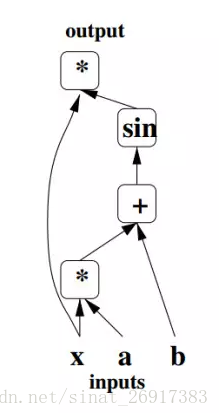
後來隨著技術的不斷演進,加上指令碼語言和低階語言各自不同的特點(概括地說,指令碼語言建模方便但執行緩慢,低階語言則正好相反),因此業界逐漸形成了這樣的一種開發框架:前端用Python等指令碼語言建模,後端用C++等低階語言執行(這裡低階是就應用層而言),以此綜合了兩者的優點。可以看到,這種開發框架大大降低了傳統框架做跨裝置計算時的程式碼耦合度,也避免了每次後端變動都需要修改前端的維護開銷。而這裡,在前端和後端之間起到關鍵耦合作用的就是計算圖。
需要注意的是,通常情況下開發者不會將用於中間表示得到的計算圖直接用於模型構造,因為這樣的計算圖通常包含了大量的冗餘求解目標,也沒有提取共享變數,因而通常都會經過依賴性剪枝、符號融合、記憶體共享等方法對計算圖進行優化。
目前,各個框架對於計算圖的實現機制和側重點各不相同。例如Theano和MXNet都是以隱式處理的方式在編譯中由表示式向計算圖過渡。而Caffe則比較直接,可以建立一個Graph物件,然後以類似Graph.Operator(xxx)的方式顯示呼叫。
因為計算圖的引入,開發者得以從巨集觀上俯瞰整個神經網路的內部結構,就好像編譯器可以從整個程式碼的角度決定如何分配暫存器那樣,計算圖也可以從巨集觀上決定程式碼執行時的GPU記憶體分配,以及分散式環境中不同底層裝置間的相互協作方式。
.
4、自動微分(Automatic Differentiation)工具
計算圖帶來的另一個好處是讓模型訓練階段的梯度計算變得模組化且更為便捷,也就是自動微分法。
將待處理資料轉換為張量,針對張量施加各種需要的操作,通過自動微分對模型展開訓練,然後得到輸出結果開始測試。那麼如何微分中提高效率呢?
第一種方法:模擬傳統的編譯器
每一種張量操作的實現程式碼都會預先加入C語言的轉換部分,然後由編譯器在編譯階段將這些由C語言實現的張量操作綜合在一起。目前pyCUDA和Cython等編譯器都已經實現了這一功能。
第二種方法:利用指令碼語言實現前端建模
用低階語言如C++實現後端執行,這意味著高階語言和低階語言之間的互動都發生在框架內部,因此每次的後端變動都不需要修改前端,也不需要完整編譯(只需要通過修改編譯引數進行部分編譯),因此整體速度也就更快。
第三種方法:現成的擴充套件包
例如最初用Fortran實現的BLAS(基礎線性代數子程式),就是一個非常優秀的基本矩陣(張量)運算庫,此外還有英特爾的MKL(Math Kernel Library)等,開發者可以根據個人喜好靈活選擇。
一般的BLAS庫只是針對普通的CPU場景進行了優化,但目前大部分的深度學習模型都已經開始採用並行GPU的運算模式,因此利用諸如NVIDIA推出的針對GPU優化的cuBLAS和cuDNN等更據針對性的庫可能是更好的選擇。
.
.
二、tensorflow執行結構
本節內容為小象學院深度學習二期,課程筆記,由寒小陽老師授課,感謝寒小陽老師,講得深入淺出,適合我這樣的菜鳥~
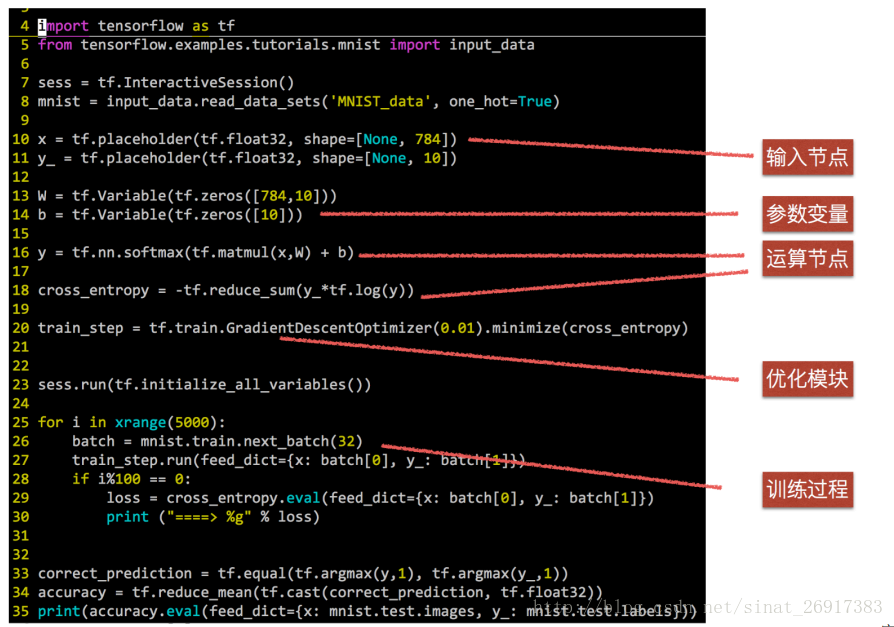
.
1、tensorflow框架整體結構
用張量tensor表示資料;計算圖graph表示任務;在會話session中執行context;
通過變數維護狀態;通過feed和fetch可以任意的操作(arbitrary operation)、賦值、獲取資料
.
2、Numpy和tensorflow中的張量對比

注意:如果tensorflow要輸出張量不跟numpy中的array一樣,要藉助eval()
print(tensor.eval()).
3、tensorflow中的計算圖

#建立節點
import tensorflow as tf
matrix1=tr.constant([[3.,3.]]) #常量節點,1*2
matrix2=tr.constant([[2.],[2.]]) #常量節點,2*1
product=tf.matmul(matrix1,matrix2) #矩陣乘法節點,兩常量相乘
#執行
sess=tf.Session() #建立session
result=sess.run(product) #run進行執行
print result #返回一個numpy中的ndarray物件
sess.close() #關閉對話,不然佔用資源.
4、用變數來儲存引數w
W2=tf.Variable(tf.zeros((2,2)).name="weights")
sess.run(tf.initialize_all_variables())
print(sess.run(W2))注意需要tf.initialize_all_variables對變數進行初始化才能賦值的。
.
5、如何指定、呼叫GPU/CPU
用with…device語句來指派。

.
6、計算模型computation graph 與層layer模型
計算模型
首先構造好整個計算鏈路,然後進行計算。同時可以對鏈路進行優化+分散式。
總得來看,鏈路結構較為複雜,但是比較好計算高效率運算。

layer模型
每個層固定實現前向與後向,同時必須手動指定目標GPU