
【CUDA並行程式設計系列(1)】GPU技術簡介
前言
CUDA並行程式設計系列是本人在學習CUDA時整理的資料,內容大都來源於對《CUDA並行程式設計:GPU程式設計指南》、《GPU高效能程式設計CUDA實戰》和CUDA Toolkit Documentation的整理。通過本系列整體介紹CUDA並行程式設計。內容包括GPU簡介、CUDA簡介、環境搭建、執行緒模型、記憶體、原子操作、同步、流和多GPU架構等。
本系列目錄:
CPU的發展
在早期,計算機的效能隨著中處理器(CPU)的發展得到了很大的提升,在摩爾定律的驅使下,CPU的時鐘頻率從30年前的1MHz發展到現在的1GHz~4GHz。但是,靠提高CPU時鐘頻率來提升計算機效能在現在已經不是一個好的方法了,隨著功耗的急劇升高和電晶體的大小已經接近極限,硬體廠商需要需求其它的方案。其中一個方案就是增加處理器的數量,現在所見到的大部分PC機都使用了多核處理器,像Intel的I3、I5、I7系列都是多核CPU。但是,受體積和功耗的現在,CPU的核心數量也不能增加的太多。可以說,近幾年CPU並沒有得到突破性的發展,連知名程式設計師Jeff Atwood
GPU的發展
在CPU發展的同時,圖形處理技術同樣經歷了巨大的變革,早期的GPU主要用於圖形顯示,以遊戲居多,在那時幾乎每一款新的大型遊戲推出都會引發顯示卡更換熱潮。圖形處理器直接執行圖形流水線功能,通過硬體加速渲染圖形,使得應用程式能實現更強的視覺效果。
GPGPU
GPU的計算能力以及並行性吸引了很多研究人員對把GPU應用於圖形之外的興趣,後來就出現了GPU通用計算(GPGPU)。2007年NVIDIA率先倡導使用GPU加速計算效能。
使用GPU加速,最主要的是讓程式並行執行,這點和PC叢集技術是一樣的。一個程式的大部分序列程式碼依然在CPU上執行,而少部分可並行的(往往也是最耗時間的,如for迴圈)程式碼在GPU上執行,如下圖。在這種方式下,程式的執行速度得到了很大的提升。
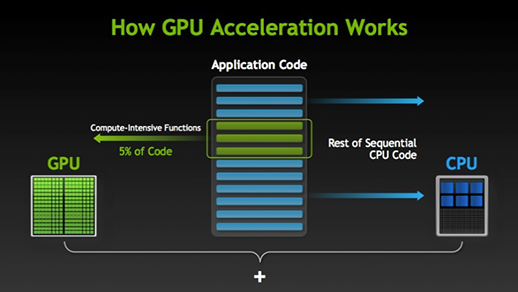
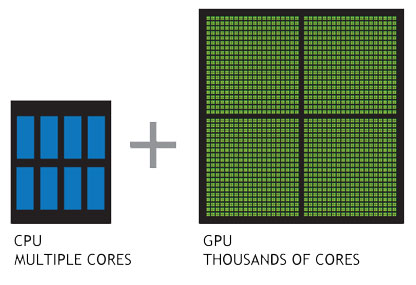
現代的GPU使用了類似於叢集技術,一個GPU內有許多流處理器簇(Streaming Multiprocessor, SM),它們類似CPU的核。一個GPU可能有成千上萬個核,因此就可以使程式在GPU上並行執行。對比CPU和GPU如下圖。
下面是NVIDIA官方給出的對比不同CPU和GPU在浮點型運算的效能:
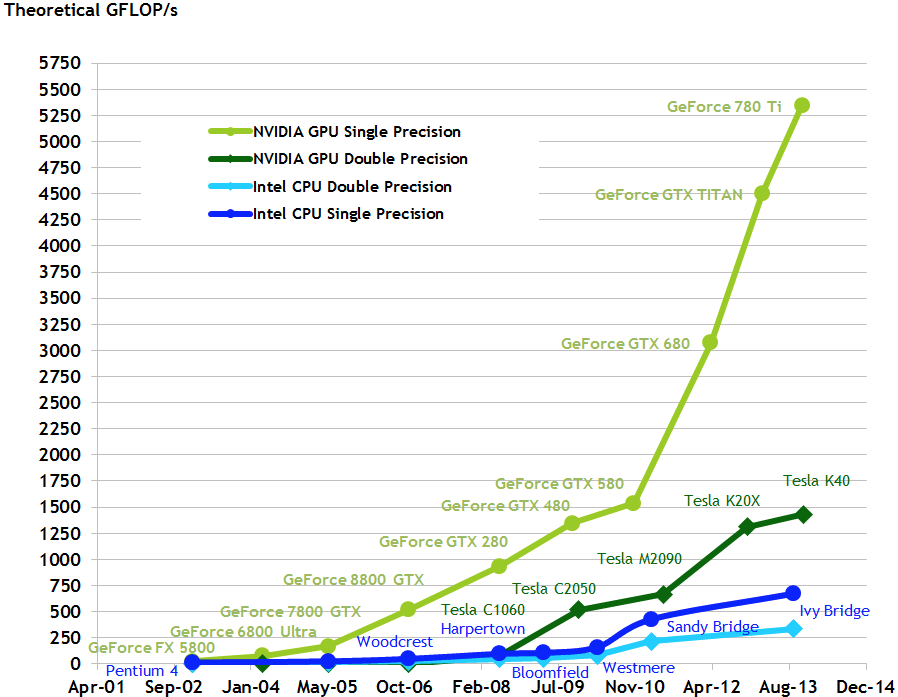
如果上面的圖表還不能明白GPU到底能加速到多塊,那麼下面這個視訊能更直觀地說明GPU加速的效果。(看不到視訊的話直接轉至 優酷連結 | Youtube)
參考文獻